






 本文介绍了SDXL Turbo模型,它是微调的SDXL模型,可一步生成清晰图像。详细说明了在AUTOMATIC1111和ComfyUI上的运行步骤,给出最佳设置建议,对比了其与其他模型在Mac、Windows上的性能,还比较了与LCM - LoRA的差异,并提及微调模型DreamShaper XL Turbo。
本文介绍了SDXL Turbo模型,它是微调的SDXL模型,可一步生成清晰图像。详细说明了在AUTOMATIC1111和ComfyUI上的运行步骤,给出最佳设置建议,对比了其与其他模型在Mac、Windows上的性能,还比较了与LCM - LoRA的差异,并提及微调模型DreamShaper XL Turbo。
英文原文:https://stable-diffusion-art.com/sdxl-turbo/
SDXL Turbo 模型是一种经过微调的 SDXL 模型,可在 1 个采样步骤中生成清晰的图像。在这篇文章中,您将学到:
- SDXL Turbo 是什么
- 如何在 AUTOMATIC1111 和 ComfyUI 上运行 SDXL Turbo
- 如何使用 SDXL Turbo 设置实时提示
- 性能对比
- 最佳生成设置
- SDXL Turbo 与 LCM LoRA

使用 SDXL Turbo 模型进行实时提示。
文章目录
什么是 SDXL Turbo?
SDXL 模型是经过微调的Stable Diffusion XL 模型,经过训练可一步生成清晰的图像。
训练
Axel Sauer 及其同事在《Adversarial Diffusion Distillation》一文中描述了该训练。以前通过蒸馏方法加速采样的努力通常会导致低采样步骤下的图像模糊。另一方面,Generative Adversarial Network 生成对抗网络(GAN)可以生成清晰的图像,但无法与扩散模型的质量相匹配。
新的Adversal Diffusion Distillation(对抗扩散蒸馏)(ADD…)训练方法旨在实现两全其美。学生模型 (SDXL Turbo) 经过训练,可一步生成与教师模型 (SDXL) 相同的结果。这不是什么新鲜事。Consistency model(一致性模型)和 progressive distillation(渐进式蒸馏)正是试图做到这一点。 SDXL Turbo 模型的技巧是添加 GAN discriminator(GAN 判别器),以确保模型生成与教师模型无法区分的高质量图像。
训练总结如下图所示。

SD Turbo 模型的训练。 (来自研究论文。)
事实
SDXL Turbo 模型是
- 从 SDXL 基础模型进行微调。
- 训练生成 512×512 图像。
使用 AUTOMATIC1111 运行 SDXL Turbo
虽然 AUTOMATIC1111 没有对 SDXL Turbo 模型的官方支持,但您仍然可以使用正确的设置运行它。 (您将在“设置”部分了解为什么会出现这种情况。)
您可以在 Windows、Mac 或 Google Colab 上使用此 GUI。如果您是稳定扩散的新手,请查看快速入门指南。如果您是 AUTOMATIC1111 的新手,请查看 AUTOMATIC1111 指南。
步骤 1. 下载 SDXL Turbo 模型
下载 SDXL Turbo 模型。将其放入 stable-diffusion-webui > models > stable-diffusion 中。
步骤2.输入txt2img设置
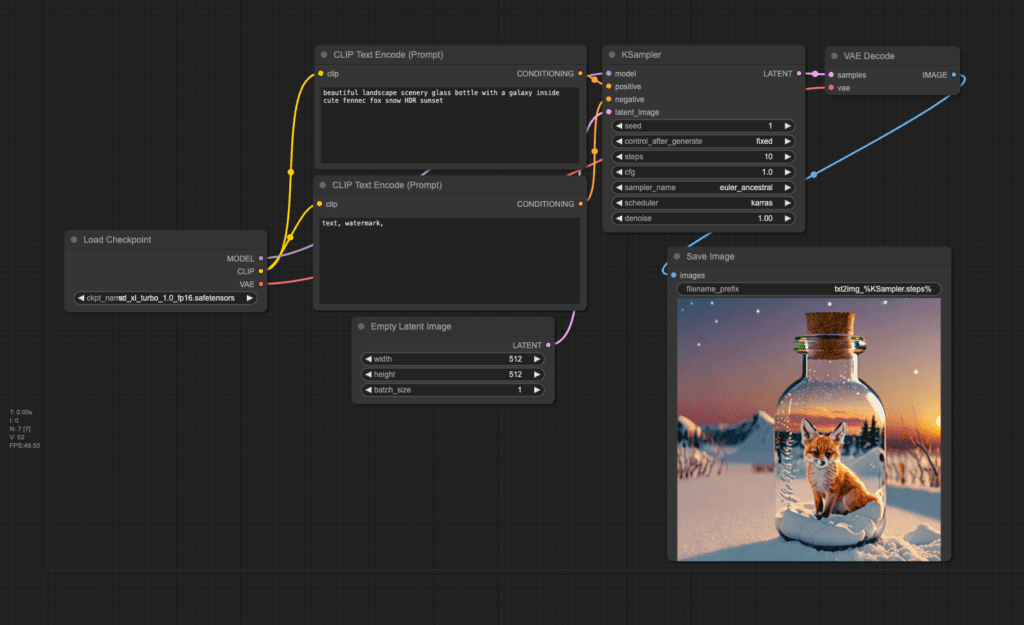
在 AUTOMATIC1111 的 txt2img 页面上,从Stable Diffusion Checkpoint下拉菜单中选择 sd_xl_turbo_1.0_fp16 模型。
提示词:
beautiful landscape scenery glass bottle with a galaxy inside cute fennec fox snow HDR sunset
- Sampling method: Euler a
- Sampling steps: 1
- Size: 512 x 512
- CFG Scale: 1

第三步:生成图像
按Generate。您应该会看到一些清晰的图像!

使用 ComfyUI 运行 SDXL Turbo
ComfyUI 正式支持 SDXL Turbo 模型
如果您是 ComfyUI 的新手,请阅读 ComfyUI 安装指南和 ComfyUI 初学者指南。
步骤1.更新ComfyUI
按照说明更新 ComfyUI。
步骤 2. 加载 SDXL Turbo 工作流程
下载下面的 SDXL Turbo 工作流程。
https://stable-diffusion-art.com/wp-content/uploads/2023/11/sdxl_turbo_txt2img.json
将工作流程图像文件拖放到 ComfyUI 以加载工作流程。
步骤 3. 下载 SDXL Turbo 模型
下载 SDXL Turbo 模型。将其放入 ComfyUI > models > checkpoints 文件夹中。
步骤 4. 生成图像
单击 Queue Prompt 生成图像。
实时提示
如果你有一块好的GPU卡,你可以在本地做一些有趣的事情,比如在ComfyUI上进行实时提示。

要在 ComfyUI 中启用实时提示,请选中“Queue Prompt”按钮下的“Extra Option”和“Auto Queue”。

SDXL Turbo 的最佳设置
工作设置与其他Stable Diffusion模型有很大不同。值得关注。
CFG scale
与 LCM LoRA 类似,CFG 尺度不能偏离 1 太多。
当 CFG 比例低于 1 时,图像开始退化。当 CFG 比例略高于 1 时,图像变得更亮并开始饱和。

将 CFG 值设置为 1 到 1.2 效果很好。
CFG Scale(无分类器引导尺度)或引导尺度是控制图像生成过程遵循文本提示的程度的参数。
负面提示
您指定您不想在负面提示中看到的内容。这是一项重要功能,因为有些图像如果不使用负面提示就无法生成。
当 CFG 为 1 时,否定提示不起作用。它不会改变一个像素。

在较高的 CFG 值(例如 1.1 – 1.3)下,负面提示会改变图像,但不会达到预期效果。请参阅下面的示例。
当CFG = 1.2时,无负提示:

与CFG=1.2的否定提示“树、车”相比,亮度略有变化,但成分相同。

我的建议是不要理会负面提示。这不起作用。
取样步骤
该模型经过训练可以进行 1 步推理。高采样步骤 5 – 10 的质量下降很明显。当噪声水平太低时,降噪器无法正确估计噪声水平。
保持采样步骤为 1 至 4。

Turbo 噪声表:SDXL Turbo,具有 1 – 10 个步骤和 Euler 祖先采样器。
噪音表
噪声表定义了每个采样步骤的噪声水平。
Turbo 噪声计划与所有其他噪声计划有很大不同。噪声几乎随着采样步长线性下降,而其他噪声在开始时下降得更快。因此,其他噪声计划可能不适用于 SDXL Turbo 模型。
但实际上,使用默认的 txt2img 工作流程以及 Karras 噪声计划和 Euler 祖先采样器会产生类似的结果。

Karras 噪声表:SDXL Turbo,具有 1 – 10 个步骤和 Euler 祖先采样器。
最好的部分是,如果您使用 1 步,Turbo 和 Karas 时间表是相同的。这就是为什么 SDXL Turbo 在没有官方支持的情况下可以在 AUTOMATIC1111 上运行!
使用低采样步骤 1 – 4。Turbo 或 Karras 噪声计划都可以。
性能对比
Mac 上的速度
Mac 不适合运行 Stable Diffusion,因为大多数强大的 GUI 没有本机代码来利用 Apple Silicon。让我们看看 SDXL Turbo 是否会改变这一点。
我将比较 SDXL Turbo 和 v1.5 基本模型,因为它们都生成 512×512 图像。请注意,与 v1.5 相比,SDXL Turbo 是一个更大的模型,但需要的步骤更少。
ComfyUI
在我刚刚重新启动的 Apple M1 上,SDXL Turbo 使用 ComfyUI 只需 1 步即可花费 71 秒生成 512×512 图像。 Stable Diffusion v1.5 需要 41 秒,20 个步骤。所以,SDXL Turbo 仍然较慢。这是由于 SDXL Turbo 型号尺寸较大。
AUTOMATIC1111
AUTOMATIC1111 上的速度有很大不同。同样,使用 Apple M1,SDXL Turbo 需要 6 秒(1 个步骤),而 Stable Diffusion v1.5 需要 35 秒(20 个步骤)。差异可能是由于内存管理的差异造成的。 ComfyUI 似乎在生成后从内存中卸载模型。
Windows 上的速度
配备 Nvidia GPU 卡的 Windows 机器上的采样步数是瓶颈。在 ComfyUI 中将实时提示与 SDXL Turbo 和 SD v1.5 进行比较时,我确实看到了 SDXL Turbo 的速度增益。
画面质量
我们在本节中做一些比较。
A color photo of a young boy and girl holding hands, witnessing the aftermath of an atomic bomb detonation from an elevated vantage point.
SDXL Turbo:

SDXL Base: (1024×1024):

Realistic Vision (v1.5 model):

现在,让我们将拍摄风格与以下提示和否定提示进行比较。
photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
SDXL Turbo:

SDXL:

Realistic Vision:

目前还不清楚 SDXL Turbo 的质量是否能与 v1.5 或 SDXL 型号相媲美。也许它只是一个基础模型,用于进一步微调。它似乎更容易生成重复图像和不正确的解剖结构。负面提示不起作用也无济于事。
SDXL Turbo 与 LCM-LoRA
这两种加速技术几乎是同时问世的。让我们进行比较,看看您应该使用哪一个。
质量
尽管提供了前所未有的速度,但 SDXL Turbo 型号较低的图像质量可能会限制其应用。我希望这个问题可以通过对高质量图像的进一步微调来解决。
另一方面,LCM-LoRA 没有微调的负担。它被设计为任何稳定扩散模型的通用加速器。它可以利用其他模型的微调。
XL LCM-LoRA 可加速 1024×1024 图像的生成。 SDXL Turbo 只能生成 512×512 的图像。
在这个质量领域,LCM-LoRA占据上风。
带 SDXL 1.0 基础模型的 LCM-LoRA:(1024×1024,4 步,LCM 采样器)

SDXL Turbo: (512×512, 1 step, Euler a sampler)

速度
SDXL Turbo 实现了最快的速度:1 步。 LCM-LoRA至少需要4步。毫无疑问,SDXL Turbo 是速度方面的赢家。
灵活性
LCM-LORA更加灵活。它是一个 LoRA,可与任何稳定扩散模型一起使用。 SDXL Turbo 是一个检查点模型。
最后的想法
如果 Stability AI 能够提供 Turbo 的 LoRA 版本那就太好了。我不确定技术障碍是什么,但如果可行的话,我们可以对任何 SDXL 模型进行一步操作!
同样,训练 1024×1024 版本也很棒。 SDXL 模型的部分吸引力在于更高的图像分辨率。 SDXL Turbo 模型解决了这个问题。
无法使用负面提示是一个缺陷。这极大地限制了模型的功能。
微调 SDXL Turbo 模型
SDXL Turbo 发布后不久,经过微调的 SDXL Turbo 模型开始出现。本节是对原始文章的补充,记录了这些微调模型的测试。
DreamShaper XL Turbo
体验用户对DreamShaper系列机型并不陌生。它们是通用模型,可提供更美观的效果。
现在,他们发布了 DreamShaper XL Turbo。由于 Turbo 训练,速度明显加快。
推荐设置为:
- Sampling steps: 4 (!)
- Sampling method: DPM++ SDE Karras
- CFG Scale: 2
以下是 DreamShaper Turbo 和 Alpha 2 模型之间的比较。 Alpha 2 模型使用 25 个步骤,CFG 比例为 7。
Dr. Evil, (Tony Stark:0.9), photo of a man working out in gym, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores

最好的部分是 DreamShaper Turbo 模型可以生成 SDXL 图像尺寸(接近 1024 x 1024)!
而且负面提示有效!
mustache

我预计会有更多 Turbo XL 车型上市。将采样步骤减少到 4 肯定有助于全球变暖……

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}