







线性判别分析
声明:版权所有,转载请联系作者并注明出处:
http://blog.csdn.net/u013719780?viewmode=contents
知乎专栏:
https://www.zhihu.com/people/feng-xue-ye-gui-zi/columns
线性判别分析(Linear Discriminant Analysis或者Fisher’s Linear Discriminant)简称LDA,是一种监督学习算法。
LDA的原理是,将数据通过线性变换(投影)的方法,映射到维度更低纬度的空间中,使得投影后的点满足同类型标签的样本在映射后的空间比较近,不同类型标签的样本在映射后的空间比较远。
一、线性判别分析(二类情形)
在讲解算法理论之前,先补充一下协方差矩阵的定义。
1. 协方差矩阵定义
矩阵 Xmxn 协方差的计算公式:
设
x,y
分别是两个列向量,则
x,y
的协方差为
若将 x,y 合并成一个矩阵 Xmxn ,则求矩阵 Xmxn ,则矩阵 Xmxn 的协方差矩阵为
2. 算法原理
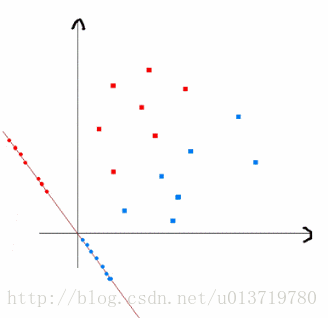
上图中红色的方形的点为0类的原始点、蓝色的方形点为1类的原始点,经过原点的那条线就是投影的直线,从图上可以清楚的看到,红色的点和蓝色的点被原点明显的分开了。下面具体看看二分类LDA问题的情形:
现在我们觉得原始特征数太多,想将
n
维特征降到只有一维(LDA映射到的低维空间维度小于等于
假设用来区分二分类的直线(投影函数)为:
注意这里得到的
y
值不是0/1值,而是
已知数据集
将
D
按照类别标签划分为两类
定义两个子集的中心:
则两个子集投影后的中心为
则两个子集投影后的方差分别为
同理可得
令
则有
令
则有
现在我们就可以定义损失函数:
我们分类的目标是,使得类别内的点距离越近(集中),类别间的点越远越好。分母表示数据被映射到低维空间之后每一个类别内的方差之和,方差越大表示在低维空间(映射后的空间)一个类别内的点越分散,欲使类别内的点距离越近(集中),分母应该越小越好。分子为在映射后的空间两个类别各自的中心点的距离的平方,欲使类别间的点越远,分子越大越好。故我们最大化 J(w) ,求出的w就是最优的了。
因为
其中,
设
Sw=S1+S2,
则
这样就可以用最喜欢的拉格朗日乘数法了,但是有一个问题,如果分子、分母是都可以取任意值,就会导致有无穷解,我们将分母限制为长度为1(这是用拉格朗日乘子法一个很重要的技巧,在下面将说的PCA里面也会用到,如果忘记了,请复习一下高数),并作为拉格朗日乘子法的限制条件,带入得到:
令
则有
很显然,
SBw
和
μ1−μ2
是平行的,又因为对
w
扩大缩小任何倍(平移
下面看看具体的数学推导,
将上式代入特征值公式中可得
因为
w
的平移不影响结果,故可以扔掉
得到
w
之后,就可以对测试数据进行分类了。就以二值分类为例,我们可以将测试数据投影到低维空间(直线,因为二分类问题是投影到一维空间),得到
因为
根据中心极限定理,独立同分布的随机变量和服从高斯分布,然后利用极大似然估计求
然后用决策理论里的公式来寻找最佳的 y0 ,详情请参阅PRML。这是一种可行但比较繁琐的选取方法。
其实,还有另外一种非常巧妙的方法可以确定 y0=0 ,投影之前的数据集的标签 ylabel 是用0和1来表示,这里我们将其做一个简单的变换,
从变换后的 y~label 的定义可以看出,对于样本 x(i) , 若 y~(i)label>0 ,则 x(i)∈D1 ,即 y(i)label=0 ,若 y~(i)label<0 ,则 x(i)∈D2 ,即 y(i)label=1 .
算法流程
输入:数据集 D={x(1),x(1),…,x(m)} ;
输出:投影后的样本集 D' ;
计算类内散度矩阵 Sw ;
求解向量 w ,其中
w=S−1w(μ1−μ2) ;将原始样本集投影到以 w 为基向量生成的低维空间中(1维),投影后的样本集就是我们需要的样本集
D' (1维特征)。
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
def shuffle_data(X, y, seed=None):
if seed:
np.random.seed(seed)
idx = np.arange(X.shape[0])
np.random.shuffle(idx)
return X[idx], y[idx]
# 正规化数据集 X
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
# 标准化数据集 X
def standardize(X):
X_std = np.zeros(X.shape)
mean = X.mean(axis=0)
std = X.std(axis=0)
# 做除法运算时请永远记住分母不能等于0的情形
# X_std = (X - X.mean(axis=0)) / X.std(axis=0)
for col in range(np.shape(X)[1]):
if std[col]:
X_std[:, col] = (X_std[:, col] - mean[col]) / std[col]
return X_std
# 划分数据集为训练集和测试集
def train_test_split(X, y, test_size=0.2, shuffle=True, seed=None):
if shuffle:
X, y = shuffle_data(X, y, seed)
n_train_samples = int(X.shape[0] * (1-test_size))
x_train, x_test = X[:n_train_samples], X[n_train_samples:]
y_train, y_test = y[:n_train_samples], y[n_train_samples:]
return x_train, x_test, y_train, y_test
def accuracy(y, y_pred):
y = y.reshape(y.shape[0], -1)
y_pred = y_pred.reshape(y_pred.shape[0], -1)
return np.sum(y == y_pred)/len(y)
# 计算矩阵X的协方差矩阵
def calculate_covariance_matrix(X, Y=np.empty((0,0))):
if not Y.any():
Y = X
n_samples = np.shape(X)[0]
covariance_matrix = (1 / (n_samples-1)) * (X - X.mean(axis=0)).T.dot(Y - Y.mean(axis=0))
return np.array(covariance_matrix, dtype=float)
class BiClassLDA():
"""
线性判别分析分类算法(Linear Discriminant Analysis classifier). 既可以用来分类也可以用来降维.
此处实现二类情形(二类情形分类)
"""
def __init__(self):
self.w = None
def transform(self, X, y):
self.fit(X, y)
# Project data onto vector
X_transform = X.dot(self.w)
return X_transform
def fit(self, X, y):
# Separate data by class
X = X.reshape(X.shape[0], -1)
X1 = X[y == 0]
X2 = X[y == 1]
y = y.reshape(y.shape[0], -1)
# 计算两个子集的协方差矩阵
S1 = calculate_covariance_matrix(X1)
S2 = calculate_covariance_matrix(X2)
Sw = S1 + S2
# 计算两个子集的均值
mu1 = X1.mean(axis=0)
mu2 = X2.mean(axis=0)
mean_diff = np.atleast_1d(mu1 - mu2)
mean_diff = mean_diff.reshape(X.shape[1], -1)
# 计算w. 其中w = Sw^(-1)(mu1 - mu2), 这里我求解的是Sw的伪逆, 因为Sw可能是奇异的
self.w = np.linalg.pinv(Sw).dot(mean_diff)
def predict(self, X):
y_pred = []
for sample in X:
sample = sample.reshape(1, sample.shape[0])
h = sample.dot(self.w)
y = 1 * (h[0][0] < 0)
y_pred.append(y)
return y_pred
def main():
# 加载数据
data = datasets.load_iris()
X = data.data
y = data.target
# 只取label=0和1的数据,因为是二分类问题
X = X[y != 2]
y = y[y != 2]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
# 训练模型
lda = BiClassLDA()
lda.fit(X_train, y_train)
lda.transform(X_train, y_train)
# 在测试集上预测
y_pred = lda.predict(X_test)
y_pred = np.array(y_pred)
accu = accuracy(y_test, y_pred)
print ("Accuracy:", accu)
if __name__ == "__main__":
main()















 8008
8008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









