







浅谈Batch Normalization
记得第一次看见这篇论文的时候,是在2016年,当时看见论文中说,将训练速度提高了14倍的时候,觉得,哇,好厉害,然后读完在实验室作了个报告也就没有后续了,但最近写DDPG的时候,里面用到了BN算法来提高泛化性,使算法能够用于不同的任务。
下面我们先来简要地了解一下BN。
BN算法源自于《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Convariate Shift》,是Google的大佬们写的。该论文的主要想法是通过对批量数据的正则化来减轻ICA(Internal Covariate Shift)对训练的影响。BN方法的引入能够让我们使用更大的学习速率(lr),并且不需要那么仔细地去选取网络的初值,并且在某些情况下对于Dropout的依赖也减轻了。本文的实验的话,主要就是在ImageNet分类问题上进行。
现在我们从三个方面来聊聊BN算法:
1作者是如何一步一步提出BN的?
2.BN算法长什么样子?
3.如何在工程中应用BN算法?
1.BN的提出
先举一个例子,假设我们有一些数据,这些数据的真实分布是y=ax+b,采样过程是有噪声的。现在我们想要通过学习的方法来拟合出这条直线方程:
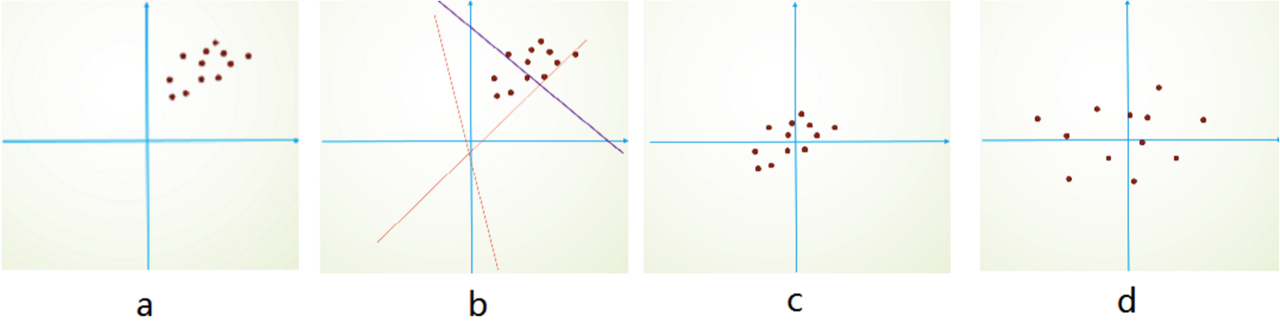
图a是采样得到的样本数据,图b表示我们的训练过程,其中的线表示尝试着去拟合的真实分布的直线,这时候我们可能需要经过多次调整,才能学到一个较好的对真实分布的拟合。而图c、d则表示我们进行了归一化和去相关之后的图像。我们对于图d进行学习时要比直接对图a进行学习要快一些的。
我们知道,在机器学习中,有一种算法叫做PCA,用于数据的降维,同时,还有一种算法叫做白化(其实就是均值和方差归一化),这是两种常用的对数据进行预处理的方法。不过对训练集进行这样的处理之后,一定要记得对测试集做同样的处理......
本文的作者呢,就是基于类似的想法,想要对每层的输入都进行正则化。但是如果我们直接对输入进行白化的话,计算量将会很大,因为要算输入各个维度的协方差矩阵,然后还要求它的inverse square root。所以作者呢,就“偷个懒”,对输入的每个维度分别处理,也即element-wise运算:
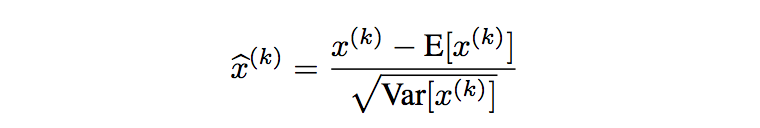
恩,这样计算量就小多了,我们只需要对于每一个维度的每一个batch求一下均值,求一下方差,代进去算一下,完美~
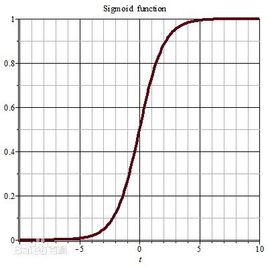
可是,做完之后,作者发现,不对,还有问题,我们将网络的capacity,也即表示能力给减弱了,比如说我们的激活函数是sigmoid,那么我们上面将均值限定为0,方差限定为1之后,也就只有sigmoid的线性段了:
作者就说,没关系,我们再引入一个线性变换,将正则化之后的输入再移回去就是了:
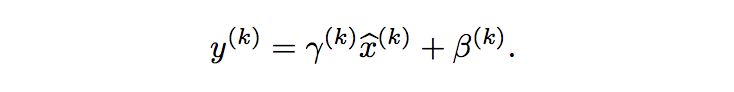
这里的gamma和beta都是可以学习的参数,是用来学习整个训练集的均值和方差的,其中gamma学习训练集的标准差,beta学习训练集的均值,所以y被规划化为整个训练集的分布了,而不是像之前那样,每个batch的数据分布都不同,导致网络学习都会由于这种batch数据分布的改变而很不开心。(因为一旦每批训练数据的分布各不相同(batch梯度下降),那么网络就要在每次迭代中去学习适应不同的分布,也就大大降低了网络的训练速度,所以要做归一化。)
这样,整个BN算法就算是提出来了。
2.BN层
BN层如下所示:

首先取出来一个mini-batch,然后求这个mini-batch的均值方差,正则化一下,最后通过学习得到的gamma和beta来求取y。
3.BN的工程应用
据作者所说,BN算法最好是用在激活函数之前,也即a=Wu+b上,然后再传给激活函数进行计算。激活函数的话,使用sigmoid和Relu都是可以的。此外,对于CNN而言,每一个特征图的所有的元素的activations都放在一个mini-batch中,统一进行正则化。也就是说,可以当做大小为m*p*q的mini-batch,m表示mini-batch的大小,p、q分别为图像的长和宽。
在论文中,作者提到,简单粗暴地应用BN方法并不能发挥BN的全部优势,我们需要遵循下面的几条建议:
1)增加学习速率。比如论文中将学习速率增加了30倍(0.0015-->0.045),效果还比以前好;
2)去掉Dropout层。因为BN层有着与Dropout类似的功能;
3)将训练样本打乱得更加彻底。对于论文中的实验,提高了1%的测试集准确率;
4)降低L2正则化权重。本文中将L2的权重减小了5倍;
5)加快lr的衰减速率。毕竟用了BN之后,训练起来更加快了,所以lr要衰减得更快一些;
6)Remove Local Response Normalization。参考论文《Dropout: A simple way to prevent neural networks from overfitting》
7)Reduce the photometric distortions。作者说因为BN训练得快,所以见到每个样本的次数比较少,因而只去关注“真实的”照片。
最后再聊一个问题,如何理解”神经网络学习的本质是学习数据的分布“?
个人认为这句话的理解要从数据集的大小来考虑,如果数据集是从真实分布中采样无穷次,并能完全覆盖所有的x范围(无限次覆盖),那么神经网络学习的就真的只是那个函数了,与x究竟是均匀分布还是高斯分布没啥关系。但关键问题就是我们在真实世界中的问题都是不可能有无限数据集的,因而神经网络的学习与x的分布有关,也就是说神经网络学习的本质是学习数据的分布。
又要到周末了~这周还有合肥马拉松,很是兴奋。大家也玩得开心,学得开心~















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









