







1.浅拷贝与深拷贝
浅拷贝:只对指针进行了拷贝,拷贝后,两个指针指向同一块内存空间。
深拷贝:不仅对指针进行了拷贝,还对指针指向的内容进行了拷贝,拷贝后的指针是指向两个不同地址的指针。
引申内容:当对象中存在指针成员时,除了在复制对象时需要考虑自定义拷贝构造函数,还应该考虑以下两种情形:
1)当函数的参数为对象时,实参传递给形参的实际上是实参的一个拷贝对象,系统自动通过拷贝构造函数实现;
2)当函数的返回值为一个对象时,该对象实际上是函数内对象的一个拷贝,用于返回函数调用处;
3)浅拷贝带来的问题的本质在于析构函数时释放多次堆内存,使用共享指针std::shared_ptr,可以完美的解决这个问题。
2. 智能指针
先看下面这段代码:
#include <iostream>
using namespace std;
int main()
{
//new对象,申请内存空间存储
int *ptr = new(nothrow) int(0);
//内存申请不成功,去delete会出问题,所以申请完成后判断指针有效性
if(!ptr)
{
cout << "new fails."
return 0;
}
// 假定hasException函数原型是 bool hasException()
if (hasException())
{
//抛出异常后释放内存,虽然正确,但是繁琐不友好
delete ptr;
ptr = nullptr;
throw exception();
}
//delete作用是避免申请没释放,导致内存泄漏resoure leak
delete ptr;
//置空,delete虽然释放了申请的内存,但是ptr会变成空悬指针,即野指针 dangling pointer
ptr = nullptr;
return 0;
}从上面代码中我们可以发现:
1) 我们需要自己处理内存泄漏的问题(如:内存没有申请成功就delete);
2)需要处理空悬指针的问题(如:指针delete,但是没有置空);
3)需要处理隐晦的由异常造成的资源泄漏(未对异常处理,或者处理了异常,没有对指针进行回收)。
为了解决上述问题: C++11引入智能指针概念,上面出现的问题,智能指针都已经考虑到了
1). Class shared_ptr:实现共享式拥有(shared ownership)概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用(reference)被销毁”时候释放。为了在结构复杂的情境中执行上述工作,标准库提供了weak_ptr、bad_weak_ptr和enable_shared_from_this等辅助类。
shared_ptr的目标就是,在其所指向的对象不再被使用之后(而非之前),自动释放与对象相关的资源。
2). Class unique_ptr:实现独占式拥有(exclusive ownership)或严格拥有(strict ownership)概念,保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露(resourece leak)——例如“以new创建对象后因为发生异常而忘记调用delete”——特别有用。
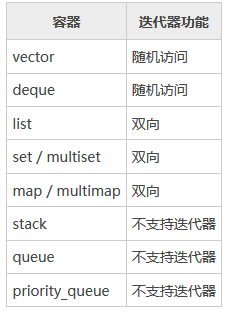
3.迭代器,遍历
不同容器的迭代器功能
Vector遍历
1)基本for循环
std::vector<int> arr;
...
for(std::vector<int>::iterator it=arr.begin();it!=arr.end();it++){
...
}2)使用auto关键字
std::vector<int> arr;
...
for(auto it = arr.begin();it != arr.end();it++){
...
}3)使用C++11新特性
std::vector<int> arr;
...
//注意此处的 n 得类型为 arr容器的value_type,即auto自动推导出vector中为int类型,n为arr中的值。
for(auto n : arr){
...//如果上面arr类型为std::map<std::string,int>,获取arr的string值n.first,获取arr的int值n.second。
}List遍历:

4. 线程安全与 std::lock_guard
当程序进行数据共享时,你肯定不希望程序陷入条件竞争,或者出现变量被破坏的情况,此时可以使用std::mutex互斥量来解决数据共享的问题。lock()上锁和unlock()解锁麻烦并且程序出现异常时还需要unlock(),不好把控,所以C++标准库未互斥量提供了RAII语法的模板类std::lock_guard,在std::lock_guard对象构造时,传入的mutex对象(即它所管理的mutex对象)会被当前线程锁住,并在析构的时候它所管理的mutex对象会自动解锁,从而保证一个已锁的互斥量能被正确解锁。
#include <iostream>
#include <thread>
#include <mutex>
int kData = 0;
std::mutex m_mutex;
void thread1()
{
std::thread thread1([&]
{
std::lock_guard<std::mutex> lock(m_mutex);
for (int i = 0; i < 10; ++i)
{
kData++;
std::cout << "\n Thread1 kData=" << kData << std::endl;
}
});
thread1.detach();
}
void thread2()
{
std::thread thread2([&]
{
std::lock_guard<std::mutex> lock(m_mutex);
for (int i = 0; i < 5; ++i)
{
kData += 100;
std::cout << "\n Thread2 kData=" << kData << std::endl;
}
});
thread2.detach();
}
void FuncThread()
{
// 1.创建一个互斥量的包装类,用来自动管理互斥量的获取和释放
// std::lock_guard<std::mutex> lock(m_mutex);
// 2.原生加锁
// m_mutex.lock();
std::lock_guard<std::mutex> lock(m_mutex);
for (int i = 0; i < 10; i++) {
// 打印当前线程的 id : kData
std::cout << "\n" << std::this_thread::get_id()
<< ":" << kData++ << std::endl;
}
// 2. 原生解锁
//m_mutex.unlock();
// 离开局部作用域,局部锁解锁,释放互斥量
}
int main()
{
/******* 方式一 ******/
//thread1();
//thread2();
/******* 方式二 ******/
//开两个线程
std::thread thread1(FuncThread);
std::thread thread2(FuncThread);
//主线程等待这两个线程完成操作之后再退出
thread1.detach();
thread2.detach();
getchar();
}测试方式一:

测试方式二:
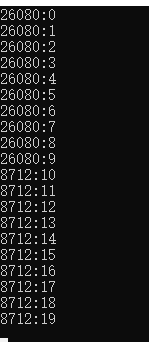
思考:不加锁结果为什么会出错?线程执行为什么不是我们所想的方式打印数据
先看方式一不加锁结果:

看到没有,不加锁,很难想象共享数据最终是一个什么结果,下面简单解释下:
首先线程也是一种轻量级进程,也存在调度,假设当前cpu使用是基于时间片的轮转调度算法,为每个进程分配一段可执行的时间片,因此每个线程都得到一段可以执行的时间,这就导致子线程1在修改并打印数据的时候,子线程1的时间片用完了,cpu切换到子线程2去修改并打印数据了,这就导致最终打印的结果不是我们预期的顺序。
5. 线程间通信
线程间通信的模型有两种:共享内存(全局变量形式)和消息传递
题目:有两个线程A、B, 当A线程向一个集合里面依次添加元素"abc"字符串,一共添加十次,当添加到第五次的时候,希望B线程能够收到A线程的通知,然后B线程执行相关的业务操作。
方法一:使用Volatile关键字
基于 volatile 关键字来实现线程间相互通信是使用共享内存的思想,大致意思就是多个线程同时监听一个变量,当这个变量发生变化的时候 ,线程能够感知并执行相应的业务。这也是最简单的一种实现方式。
public class TestSync {
// 定义一个共享变量来实现通信,它需要是volatile修饰,否则线程不能及时感知
static volatile boolean notice = false;
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// 实现线程A
Thread threadA = new Thread(() -> {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A向list中添加一个元素,此时list中的元素个数为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
notice = true;
}
});
// 实现线程B
Thread threadB = new Thread(() -> {
while (true) {
if (notice) {
System.out.println("线程B收到通知,开始执行自己的业务...");
break;
}
}
});
// 需要先启动线程B
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再启动线程A
threadA.start();
}
}
方式二: 使用Object类的Wait()方法和notify()方法。
众所周知,Object类提供了线程间通信的方法:wait()、notify()、notifyaAl(),它们是多线程通信的基础,而这种实现方式的思想自然是线程间通信。
注意: wait和 notify必须配合synchronized使用,wait方法释放锁,notify方法不释放锁
public class TestSync {
public static void main(String[] args) {
// 定义一个锁对象
Object lock = new Object();
List<String> list = new ArrayList<>();
// 实现线程A
Thread threadA = new Thread(() -> {
synchronized (lock) {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A向list中添加一个元素,此时list中的元素个数为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
lock.notify();// 唤醒B线程
}
}
});
// 实现线程B
Thread threadB = new Thread(() -> {
while (true) {
synchronized (lock) {
if (list.size() != 5) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程B收到通知,开始执行自己的业务...");
}
}
});
// 需要先启动线程B
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再启动线程A
threadA.start();
}
}
注意: 在线程A发出notify()唤醒通知之后,依然是走完了自己线程的业务之后,线程B才开始执行,这也正好说明了,notify()方法不释放锁,而wait()方法释放锁。
线程同步机制有以下几种情况:
1) 事件(Event)
2)信号量(semaphore)
3)互斥量(mutex)
4)临界区(Critical section)
临界区编程的一般方法是:
void UpdateData()
{
EnterCriticalSection(&gCriticalSection);
...//do something
LeaveCriticalSection(&gCriticalSection);
}互斥编程的一般方法:
void UpdateResource()
{
WaitForSingleObject(hMutex,…);
...//do something
ReleaseMutex(hMutex);
}
6. 内存分配
1) 在栈上分配内存:函数中的临时局部变量分配在栈上,由操作系统自动分配,函数调用结束时内存也随之析构,栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
2) 在静态存储区分配内存,这块内存在程序编译的时候就已经分配好,用来存放常量,全局变量和static变量,内存在整个程序运行周期内都存在。
3) 在堆区使用malloc或new申请内存,这种内存分配方式非常灵活,需要注意
①(立判)申请内存后立即判断指针是否为NULL确定内存是否分配成功,如果为NULL则立即用return终止此函数,或者用exit(1)终止整个程序的运行,为new和malloc设置异常处理函数;
②(初始化)为申请的内存赋初值,分配的是一段连续的内存空间的话,要防止指针下标越界;
③(sizeof得到指针字节数)sizeof是操作符,不能用sizeof得到内存空间的大小,只能在申请时候记住申请的空间大小;
④(防泄漏)在内存使用结束后必须用free或delete释放内存,注意在内存使用中如果存在指针加1或减1 的操作应特别注意,释放的内存要和申请的内存一致,放置内存泄漏,释放内存后,应该立即将指针置为NULL,不要存在野指针。

7. 半工,半双工,全双工
1. 单工:指两者的通信是单向的,一个只能主动的发信号,而另一个只能被动的接受信息。
eg:像交通灯可以发起各种信号,而行人、车辆只能被动接受信息。
2. 半双工:两个对象A和B,A能发信息给B,B也能发消息给A,但这两个动作不可以同时进行。
eg:像打球的两个人,可以相互传球,但不能同时传球(因为球只有一个)。
3. 全双工:两个对象A和B,A能发信息给B,B也能发消息给A,并且这两个动过可以同时进行。
eg:打电话的两个人。
socket套接字属于使用的是全双工
8. 哈希表 寻址容易,插入删除也容易的数据结构 (拉链法)

数组特点:寻址容易,插入和删除困难
链表特点:寻址困难,插入删除容易
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表
Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
hash就是找到一种数据内容和数据存放地址之间的映射关系。
当存储记录时,通过散列函数计算出记录的散列地址
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
哈希表中的关键问题:
1)哈希表的设计:关键字和数字(存储位置)之间建立了一个确定的对应关系f
2)哈希表冲突:通过哈希函数计算出的索引,即使关键字不同,索引也会有可能相同
3)哈希表实现时间和空间的平衡:无限空间时,时间为O(1);1的空间时,时间为O(n)Hash冲突发生的场景:当关键字值域远大于哈希表的长度,而且事先并不知道关键字的具体取值时。hash冲突就会发 生。
Hash溢出发生的场景:当关键字的实际取值大于哈希表的长度时,而且表中已装满了记录,如果插入一个新记录,不仅发生冲突,而且还会发生溢出。
解决Hash冲突和溢出的方法主要有:开放地址法和拉链法。















 4171
4171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









