









简短总结CNN可视化方法与《What have we learned from deep representations for action recognition》
CNN可视化方法总结
本节内容大部分来自于CS231n note,附上链接:cs231n
由于CNN经常被批评不知道学习到的特征不可解释。常用的方法有以下几种
Visualizing the activations and first-layer weights
Retrieving images that maximally activate a neuron
- Embedding the codes with t-SNE
- Occluding parts of the image
- Visualizing the data gradient and friends
- GAN
1.Visualizing the activations and first-layer weights
最常见的是可视化激活值和第一层权重,也比较好实现。
Layer Activations
Conv/FC Filters
Layer Activations
直接对网络输入样本,进行前向传播,得到激活值,对特定层进行可视化,通常会发现随着训练次数的增加,激活值会变得更加稀疏和局部化。有时候可以发现很多filter的激活值接近与0,称为 dead filter。
如下图所示,这幅图是AlexNet第一层卷积层的可视化结果。每一个方块显示了一个特定filter的激活映射。

下图是AlexNet同一幅图第五层卷积层的可视化结果,可以发现激活值非常稀疏且局部。

实现代码参考
tf_cnnvis
Conv/FC Filters
这种可视化方法和UFLDL主页上的可视化方法一致,不用特定输出得到激活值而是可视化每一个卷积核的权重值。在实验中通常是可视化第一层卷积层,因为很好解释。
如下图所示,为AlexNet第一层卷积层的卷积核的权重,可以发现每个卷积核在不同方向起到滤波效果。

实现代码参考:
ufldl exercise
2.Retrieving images that maximally activate a neuron
使用一个大的数据集,feed进整个网络,记录哪些图像最大化激活了某个神经元,然后把这些图像显示出来。通过观察图像可以了解对应的神经元响应哪些信息。
如下图所示,为最大激活AlexNET第五层池化层的一些图像。可以发现不同的神经元对不同类型的输入图像较敏感。

实现参考
arxiv.org.1311.2524
3.Embedding the codes with t-SNE
CNN可以看作将原始图像转换到一个类别可以通过线性分类器可以分类的表示空间。 可以有一个粗略的想法,低维度的表示和高维度的表示近似距离。有很多embedding的方法可以把高维向量嵌入到低维度空间中,并且保留点与点之间的主要信息。 t-SNE是其中用的最多的方法。
为了得到embedding,通常用CNN得到CNN codes,比如AlexNet在fc层前得到的4096维向量。然后用t-SNE得到每张图片的2D向量,并用网格可视化。如下图所示。

实现参考
cnnembed
4.Occluding parts of the image
在分类问题中,假定一张图像识别为狗,如何确定是从图片中提取到狗而不是利用了其它背景或者无关信息等?其中的一个方案是画出所有位置作为感兴趣点的概率。即把一系列图片初始为0,然后看类别的概率。可以用2D heat map 可视化。
诸如下图所示,可以看出主要通过狗的脸部来判断类别为狗。
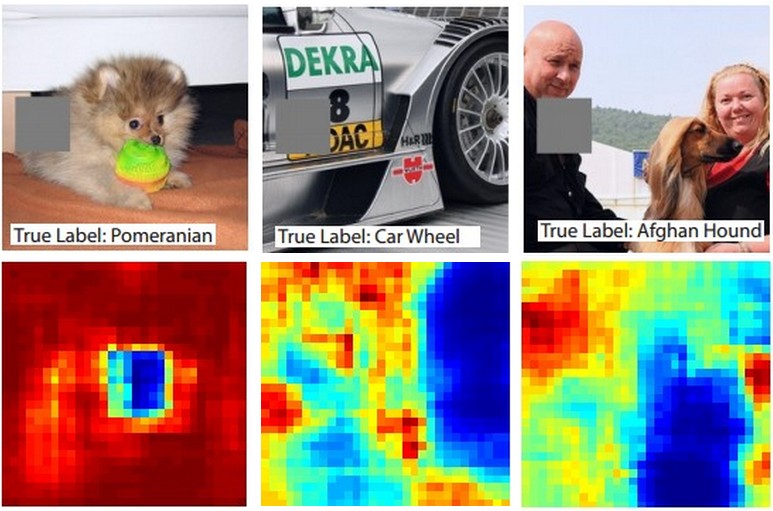
5.Visualizing the data gradient and friends
其它的有可视化梯度等…,主页上有提供文章链接
《What have we learned from deep representations for action recognition》笔记
这篇CVPR2018的文章主要解释了在动作识别中学习到的特征,得到了一些重要结论。
- 1.流融合可以真的学习到可区分的Spatitemporal特征
- 2.网络可以学习得到高区分度的表示信息
- 3.通过分层机制,特征变得更加抽象并且增加了对于方向的无偏性
- 4.可视化可以用来查看分类出错的原因
这篇文章中,把可视化常见的研究方法分为了三类。
1.Visualization for given inputs
2.Activation maximization
3.Generative Adversarial Networks(GANs)
Visualization for given inputs
1.选用大数据集,得到最大化感兴趣区域的数据集,用来做可视化。类似于前面介绍的Retrieving images that maximally activate a neuron
2.使用BP高亮隐藏单元中关键位置
GANS
通过生成对抗网络可视化输出
这篇文章比较大的一个创新在于第一次在行为识别中引入了可视化,之前没有其它人做过。
此外提出了一个Activation maximization 和两个正则化方法。比较大的贡献就是证明了时空融合的特征确实学习到了可区分的特征
文中揭示了几个比较容易混淆的例子,比如playingViolin和playingCello。使得产生分类混淆的时候可以通过可视化学习到的特征来理解为何会识别错误
事实上,很难通过可视化结果来分析分类错误原因,在文章中提到的区分App;yLipstick和AppleEyeMakeup例子里,也只是猜想,实际应用的意义不大,只能当作生成参考
这篇文章还有个比较好的工作就是pdf中嵌入了可点击的图片,同时会触发对应的卷积层,可视化激活单元。
在文章附录中提供了action_vis.pdf,其中包含了大量行为对应的可视化结果
All In All…… 这是花时间最长收获最少的一篇文章……















 1924
1924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









