








第二章:SVM(支持向量机) - 理论

欢迎来到监督式机器学习的第二块踏脚石。本章再次分为两部分。第1部分(这一部分)讨论了理论,工作和调整参数。第2部分(这里)我们将采取小编码练习的挑战。
如果你还没有读过朴素贝叶斯,我建议你在这里仔细阅读。
0.引言
支持向量机(SVM)是由分离超平面正式定义的区分分类器。换句话说,给定标记的训练数据( 监督学习 ),该算法输出一个最优的超平面,对新的例子进行分类。在两维空间中,这个超平面是一个将平面分成两部分的直线,每部分都放在两侧。
混乱?别担心,我们将学习外行人员的条款。
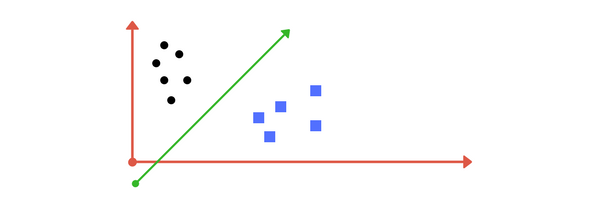
假设你给出了如图(A)所示的图上两个标签类的图。你能为班级决定一条分隔线吗?

你可能会想出类似于下面的图片(图片B)。它相当分离两个类。线左边的任何点落入黑色圆圈类,右边落入蓝色方形类。类的分离。这就是SVM所做的。它找出了一条线/超平面(在多维空间中分离出来的类)。不久,我们将讨论为什么我写了多维空间。
1.使它有点复杂...
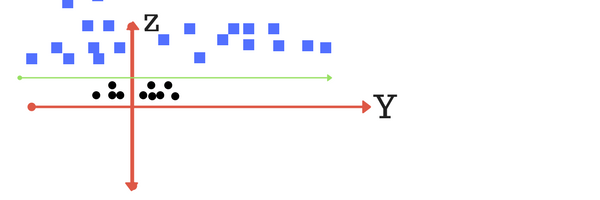
到现在为止还挺好。现在考虑一下,如果我们有如下图所示的数据?很显然,没有一条线可以分隔这个xy平面上的两个类。那么我们该怎么办?我们应用转换并添加另一个维度,因为我们称之为z轴。让我们假设z平面上的点的值,w = x 2 + y 2。在这种情况下,我们可以将它作为距离z原点的距离来操作。现在,如果我们在z轴上绘图,清晰的分隔是可见的,并且可以绘制一条线。

当我们将这条线转换回原始平面时,它将映射到圆形边界,如图E所示。这些转换称为内核。

值得庆幸的是,您不必每次都为您的数据集猜测/推导转换。sklearn库的SVM实现提供了内置的。
2.使它更复杂一点...
如果数据图重叠?或者,如果一些黑点是在蓝色点内?我们应该画哪一条线?


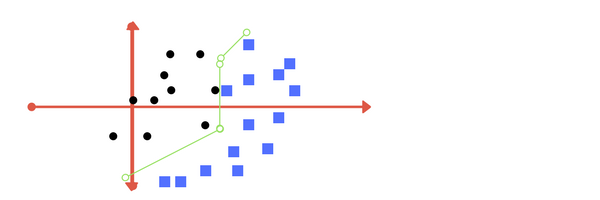
你认为哪一个?那么,这两个答案都是正确的。第一个容忍一些异常点。第二个是试图通过完美的分区达到0的容忍度。
但是,这是有利的。在现实世界的应用中,为数百万训练数据集寻找完美的课程需要很长时间。正如你将在编码中看到的那样。这被称为正则化参数。在下一节中,我们定义了两个正则化参数和伽马。这些是SVM分类器中的调整参数。改变这些,我们可以在合理的时间内以更准确的方式获得可观的非线性分类线。在编码练习中(本章第2部分),我们将看到如何通过调整这些参数来提高SVM的准确性。
另一个参数是内核。它定义我们是否想要线性分离的线性。这也在下一节讨论。

3.调整参数:内核,正则化,伽玛和边距。
核心
线性SVM中超平面的学习是通过使用一些线性代数来转换问题来完成的。这是内核扮演的角色。
对于线性内核,使用输入(x)和每个支持向量(xi)之间的点积对新输入进行预测的公式计算如下:
f(x)= B(0)+ sum(ai *(x,xi))
这是一个方程式,包括计算训练数据中所有支持向量的新输入向量(x)的内积。必须通过学习算法从训练数据中估计系数B0和ai(对于每个输入)。
的多项式内核可被写为K(X,XI)= 1个+ SUM(X *ⅹⅰ)^ d和指数为K(X,XI)= EXP(-gamma *总和((X - 。xi²))[来源对于这个摘录:http : //machinelearningmastery.com/ ]。
多项式和指数内核计算更高维的分隔线。这被称为 核心技巧
正则
Regularization参数(在Python的sklearn库中经常被称为C参数)告诉SVM优化您想避免对每个训练示例进行错误分类。
对于较大的C值,如果超平面能更好地获得正确分类的所有训练点,则优化将选择一个较小的裕度超平面。相反,C值非常小会导致优化器寻找更大的边界分离超平面,即使超平面会错误分类更多的点。
下面的图像(与图2中的图像1和图像2相同)是两个不同正则化参数的示例。由于正则化价值较低,因此左侧有一些错误分类。更高的价值导致像正确的结果。
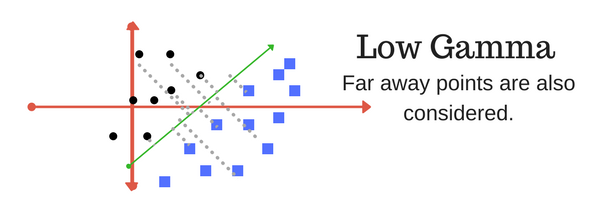
伽玛
gamma参数定义单个训练示例的影响能达到多远,其中低值表示“远”,高值表示“近”。换句话说,在低伽玛的情况下,在计算分离线时考虑远离合理分离线的点。在高伽玛意味着在计算中考虑接近合理线的点。

余量
最后是SVM分类器的非常重要的特性。核心SVM试图实现良好的利润率。
保证金是行与最接近的类别点的分离。
两个类别的分离度都较大的情况下,一个好的边界就是这样。下面的图片给出了好的和坏的边缘的视觉例子。良好的保证金允许分数在各自的班级中,而不会与其他班级交叉。
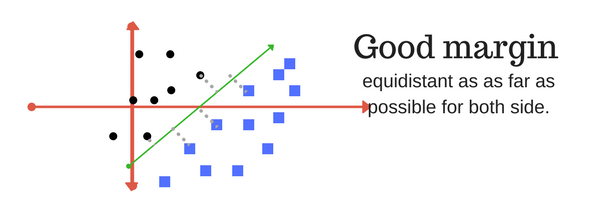
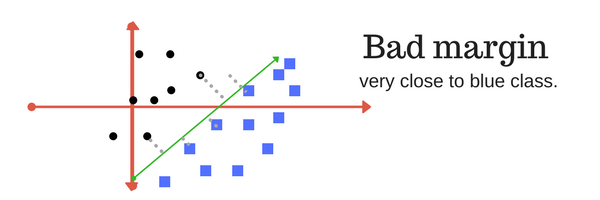
4.在本章的下一部分中,
在下一部分(这里),我们将调整和播放调整参数,并使用python的sklearn库实现SVM分类器(也称为SVC)的迷你项目。我们将比较结果与朴素贝叶斯类。查看编码部分:https : //medium.com/machine-learning-101/chapter-2-svm-support-vector-machine-coding-edd8f1cf8f2d。
5.结论
我希望这一部分有助于理解SVM分类器背后的工作。在下面评论你的想法,反馈或建议。如果你喜欢这篇文章,与你的朋友分享,订阅Machine Learning 101 点击心(❤)图标。和平!
















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









