






Introduction to SupportVector Machines
支持向量机简介
Goal
在本教程中,您将学习如何:
使用 OpenCV 函数 cv::ml::SVM::train构建基于 SVM 的分类器,并使用 cv::ml::SVM::predict来测试其性能。
What is a SVM?
支持向量机(A Support Vector Machine) (SVM) 是由分离超平面(separatinghyperplane)正式定义的判别分类器(discriminative classifier)。换句话说,给定标记的训练数据(supervised learning监督学习),该算法输出一个对新示例进行分类的(optimal hyperplane)最佳超平面。
超平面在什么意义上是最优的?让我们考虑以下简单的问题:
对于属于两个类别之一的一组线性可分(a linearly separable set)的 2D 点,找到一条分离直线。

笔记
在这个例子中,我们处理笛卡尔平面中的线和点,而不是高维空间中的超平面和向量。这是对问题的简化。重要的是要理解这样做只是因为我们的直觉更好地建立在易于想象的示例中。但是,相同的概念适用于要分类的示例位于维度大于 2 的空间中的任务。
In this example we deal with lines andpoints in the Cartesian planeinstead of hyperplanes and vectors ina high dimensional space. This is asimplification of the problem.It is important to understand that this is doneonly because our intuition is betterbuilt from examples that are easy to imagine. However, the same concepts applyto tasks where the examples to classify liein a space whose dimension is higher than two.
在上图中,您可以看到存在多条直线可以解决问题。他们中的任何一条直线都比其他的更好吗?我们可以直观地定义一个标准来估计线条的价值(the worth of the lines):如果线条太靠近点,则它是坏的,因为它会对噪声敏感并且无法正确概括。因此,我们的目标应该是找到尽可能远离所有点的线。
然后,SVM算法的操作基于找到给训练样例提供最大最小距离的超平面。两次,这个距离在 SVM 理论中得到了重要的边际名称。因此,最优分离超平面(optimalseparating hyperplane)最大化了训练数据的边距。
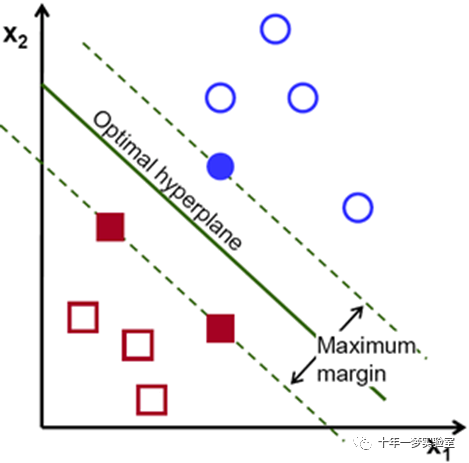
How is the optimalhyperplane computed?
让我们介绍用于正式定义超平面的符号:

其中β称为权重向量(the weight vector),β0称为偏差(bias)。
笔记
您可以在本书的第 4.5 节(分离超平面)中找到对此和超平面的更深入描述:T. Hastie、R. Tibshirani 和 J. H. Friedman 的Elementsof Statistical Learning [250])。
最优超平面可以通过缩放 β 和 β0 以无数种不同的方式表示。按照惯例,在超平面的所有可能表示中,选择的是
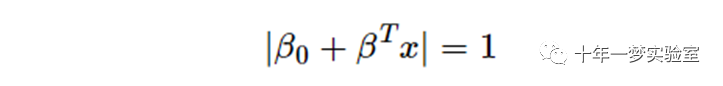
其中 x 表示最接近超平面的训练示例。通常,最接近超平面的训练样本称为支持向量。这种表示被称为规范超平面。
where x symbolizes the training examples closestto the hyperplane. In general, the training examples that are closest to thehyperplane are called support vectors. Thisrepresentation is known as the canonical hyperplane.
现在,我们使用几何结果给出点 x 和超平面 (β,β0) 之间的距离:
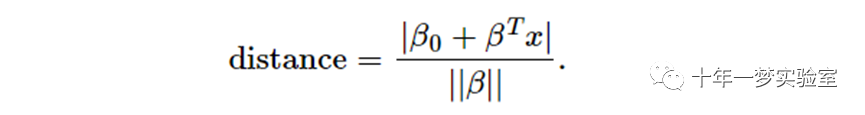
特别是,对于规范超平面,分子等于 1,到支持向量的距离为

回想一下上一节中介绍的边距,这里表示为 M,是到最近示例的距离的两倍:

最后,最大化 M的问题等价于最小化受某些约束的函数 L(β)的问题。约束对超平面正确分类所有训练示例xi的要求进行建模。正式地,

其中 yi 表示训练示例的每个标签。
这是一个拉格朗日优化问题,可以使用拉格朗日乘数求解,得到最优超平面的权重向量β和偏置β0。
Source Code
https://github.com/opencv/opencv/tree/4.x/samples/cpp/tutorial_code/ml/introduction_to_svm/introduction_to_svm.cpp
#include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/ml.hpp>
using namespace cv;
using namespace cv::ml;
int main(int, char**)
{
//设置训练数据
//! [setup1]
int labels[4] = {1, -1, -1, -1};
float trainingData[4][2] = { {501, 10}, {255, 10}, {501, 255}, {10, 501} };
//! [setup1]
//! [setup2]
Mat trainingDataMat(4, 2, CV_32F, trainingData);//训练数据按行排列
Mat labelsMat(4, 1, CV_32SC1, labels);//标签(4个样本)4行1列
//! [setup2]
//训练SVM
//! [init]
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::LINEAR);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 100, 1e-6));
//! [init]
//! [train]
svm->train(trainingDataMat, ROW_SAMPLE, labelsMat);
//! [train]
// 可视化数据
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);//初始化为黑色背景图512x512
// 显示 SVM 给出的决策区域 Show the decision regions given by the SVM
//! [show]
Vec3b green(0,255,0), blue(255,0,0);
for (int i = 0; i < image.rows; i++)//图像的行 对应y坐标
{
for (int j = 0; j < image.cols; j++)//图像的列 对应x坐标
{
Mat sampleMat = (Mat_<float>(1,2) << j,i);//像素坐标
float response = svm->predict(sampleMat);//预测像素坐标 j,i 的响应
if (response == 1) //正样本 1 绿色
image.at<Vec3b>(i,j) = green;
else if (response == -1) //负样本 -1 蓝色
image.at<Vec3b>(i,j) = blue;
}
}
//! [show]
// 显示训练使用的数据
//! [show_data]
int thickness = -1;//填充圆圈
circle( image, Point(501, 10), 5, Scalar( 0, 0, 0), thickness );//黑色圆圈 1
circle( image, Point(255, 10), 5, Scalar(255, 255, 255), thickness );//白色圆圈 -1
circle( image, Point(501, 255), 5, Scalar(255, 255, 255), thickness );//白色圆圈 -1
circle( image, Point( 10, 501), 5, Scalar(255, 255, 255), thickness );//白色圆圈 -1
//! [show_data]
// 显示支持向量 Show support vectors
//! [show_vectors]
thickness = 2;
Mat sv = svm->getUncompressedSupportVectors();
for (int i = 0; i < sv.rows; i++)//遍历所有支持向量
{
const float* v = sv.ptr<float>(i);//支持向量 的x坐标指针
circle(image, Point( (int) v[0], (int) v[1]), 6, Scalar(128, 128, 128), thickness);//灰色圆
}
//! [show_vectors]
imwrite("result.png", image); // 保存图像
imshow("SVM Simple Example", image); // 显示
waitKey();
return 0;
}Explanation
设置训练数据
本练习的训练数据由一组标记的 2D 点组成,这些点属于两个不同类别之一;其中一类由一个点组成,另一个由三个点组成。
int labels[4]= {1, -1, -1, -1}; //标签:正、负
float trainingData[4][2]= { {501, 10}, {255, 10}, {501, 255}, {10, 501} };//样本数据之后将使用的函数 cv::ml::SVM::train要求将训练数据存储为浮点数的 cv::Mat 对象。因此,我们从上面定义的数组中创建这些对象:
Mat trainingDataMat(4, 2, CV_32F, trainingData);
Mat labelsMat(4, 1, CV_32SC1, labels);设置 SVM 的参数
在本教程中,我们在最简单的情况下介绍了 SVM 的理论,即训练样本被分成两个线性可分的类。然而,SVM 可以用于各种各样的问题(例如,非线性可分数据的问题、使用核函数来提高示例维度的 SVM 等)。因此,我们必须在训练 SVM 之前定义一些参数。这些参数存储在cv::ml::SVM 类的对象中。
Ptr<SVM> svm= SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::LINEAR);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 100, 1e-6));这里:
Type of SVM支持向量机的类型。我们在这里选择可用于 n 类分类( n-classclassification)(n ≥ 2)的类型C_SVC。这种类型的重要特征是它处理类的不完美分离(即当训练数据是非线性可分离的)。这个特性在这里并不重要,因为数据是线性可分的,我们选择这种 SVM 类型只是因为它是最常用的。
Type of SVM kernel. SVM 内核的类型。我们没有讨论核函数,因为它们对我们正在处理的训练数据不感兴趣。不过,现在让我们简要解释一下核函数背后的主要思想。它是对训练数据进行的映射,以提高其与线性可分数据集的相似性。这种映射包括增加数据的维数,并使用核函数有效地完成。我们在这里选择类型LINEAR,这意味着不进行任何映射。此参数使用 cv::ml::SVM::setKernel定义。
Termination criteria of the algorithm. 算法的终止标准。SVM 训练过程以迭代方式求解受约束的二次优化问题。在这里,我们指定了最大迭代次数和容差误差,因此即使尚未计算出最佳超平面,我们也允许算法以更少的步数完成。 此参数在结构cv::TermCriteria 中定义。Here we specify a maximum number ofiterations and a tolerance error so we allow the algorithm to finish in lessnumber of steps even if the optimal hyperplane has not been computed yet.
Train the SVM 训练 SVM 我们调用方法cv::ml::SVM::train来构建 SVM 模型(build the SVM model)。
svm->train(trainingDataMat, ROW_SAMPLE, labelsMat);SVM 分类的区域Regionsclassified by the SVM
方法 cv::ml::SVM::predict用于使用经过训练的 SVM对输入样本进行分类。在此示例中,我们使用此方法根据 SVM 所做的预测为空间着色。换句话说,遍历图像,将其像素解释为笛卡尔平面上的点。每个点的颜色取决于 SVM 预测的类别; 如果是标签为 1 的类,则为绿色;如果是标签为 -1 的类,则为蓝色。
Vec3b green(0,255,0), blue(255,0,0);
for (int i = 0; i < image.rows; i++)
{
for (int j = 0; j < image.cols; j++)
{
Mat sampleMat = (Mat_<float>(1,2) << j,i); //像素坐标赋值给1行2列的Mat
float response = svm->predict(sampleMat);
if (response == 1)
image.at<Vec3b>(i,j) = green;
else if (response == -1)
image.at<Vec3b>(i,j) = blue;
}
}支持向量Support vectors
我们在这里使用了几种方法来获取有关支持向量的信息。方法 cv::ml::SVM::getSupportVectors 获取所有支持向量。我们在这里使用这种方法来查找作为支持向量的训练示例并突出显示它们。
thickness = 2;
Mat sv = svm->getUncompressedSupportVectors();
for (int i = 0; i < sv.rows;i++)//遍历支持向量
{
const float* v = sv.ptr<float>(i);//第i+1个支持向量的x坐标指针
circle(image, Point((int) v[0],(int) v[1]), 6, Scalar(128, 128, 128), thickness);
}Results
该代码会打开一个图像并显示两个类的训练示例。一类的点用白色圆圈表示,黑色的点用于另一类。
SVM 被训练并用于对图像的所有像素进行分类。这导致图像在蓝色区域和绿色区域中的划分。两个区域之间的边界是最优分离超平面。
最后,支持向量在训练示例周围使用灰色环显示。

参考:
https://docs.opencv.org/4.5.5/d1/d73/tutorial_introduction_to_svm.html















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









