







1.1机器学习是什么
机器学习是实现人工智能应用的主要方法,它广泛的应用于机器视觉、语音识别、自然语言处理、数据挖掘等领域。
机器视觉(CV):主要用计算机来模拟人的视觉功能,从客观事物的图像中提取信息,进行处理并加以理解,最终用于实际检测、测量和控制。例如图像识别。
语音识别:理解人说话的声音信号,将它转化成文字。例如语音转文字。
自然语言处理(NLP):主要研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。例如机器翻译、文本分类、问题回答。现在大火的大语言模型,比如ChatGPT的问答系统就属于NLP领域。
数据挖掘:指从大量的数据中通过算法搜索隐藏于其中信息的过程。例如数据归类、预测分析。
1.1.1关于机器学习一个简单的例子
有一个这样的问题:如何判断一个水果是樱桃还是猕猴桃?
人类可以瞬间给出问题的答案,但仔细思考一下我们来判断水果的时候主要看的是两种水果的特征,比较这两种水果的特征:猕猴桃比樱桃大、猕猴桃通常是绿灰色的而樱桃通常是红色的。
当我们用计算机来解决这个问题的时候也可以通过特征来进行判断。首先采集一些猕猴桃和樱桃,称它们为训练样本/样本数据,测量这些样本的质量和颜色,然后将水果放在二维坐标平面上,如图1.1所示。

图1.1
质量和颜色是区分两种水果的有用信息,组合在一起形成二维特征向量,这些特征向量可以转换成二维空间中的点,横坐标代表质量,纵坐标代表颜色。每测量一个水果就得到坐标中的一个点。我们把这些点绘制到二维坐标系中,得到如图1.2所示的结果,可以看到如果用一条直线把平面分成两部分,落在直线左上半部分的点判定为樱桃,落在直线右下部分的点判定为猕猴桃。
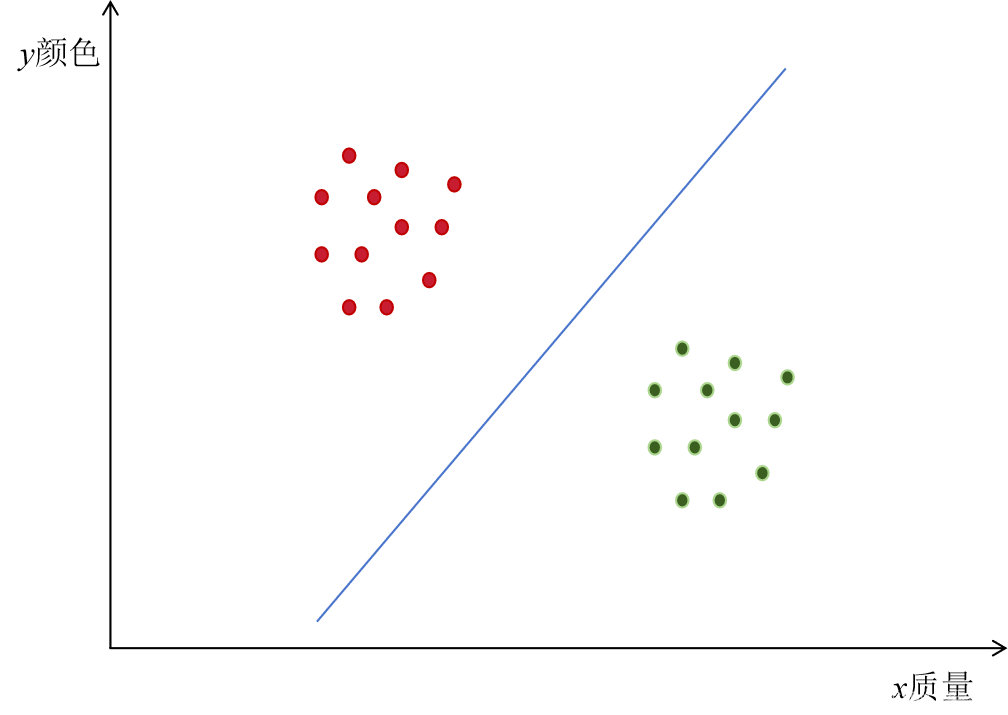
图1.2
我们的目标是要找到这条直线,假设它的方程为:
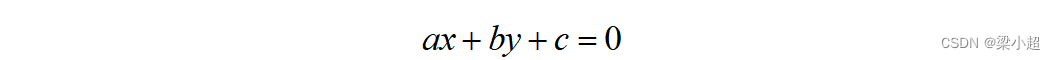
位于直线上方的所有点判定为樱桃,落在直线下方的点判定为猕猴桃,即满足如下不等式:
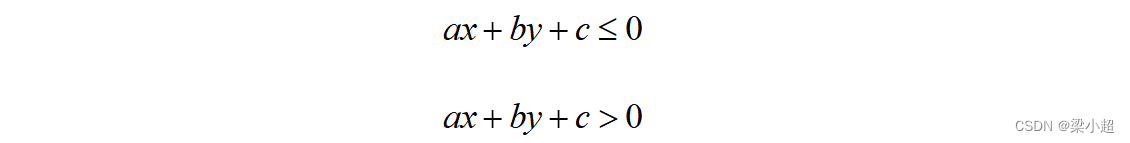
给两类水果进行编号,称为类别标签,定义樱桃的类别标签为-1,猕猴桃的类别标签为+1。上面的判定规则可以写成决策函数:
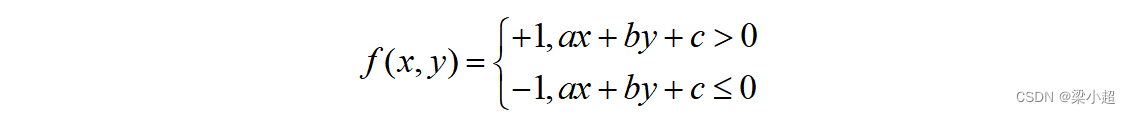
现在的问题是怎样找到这条直线,即确定参数a、b、c的值,保证水果能够被正确分类。通过样本数据寻找分类直线的过程就是机器学习的训练过程。由于要判断的是一个物体所属的类别,所以这个问题称为分类问题。预测水果类别的函数为:
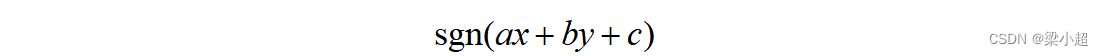
sgn是符号函数,定义为:
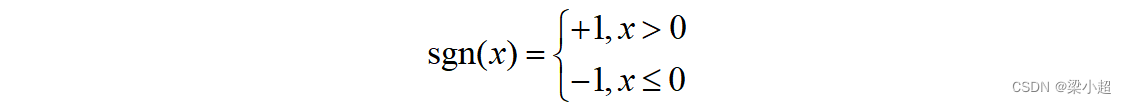
机器学习算法中有很多都会用到符号函数。上面的例子中,需要用样本数据进行学习,得到一个函数(也可以称为模型),然后用这个模型对新的样本进行预测。可以得到图1.3所示的机器学习任务的一般流程。
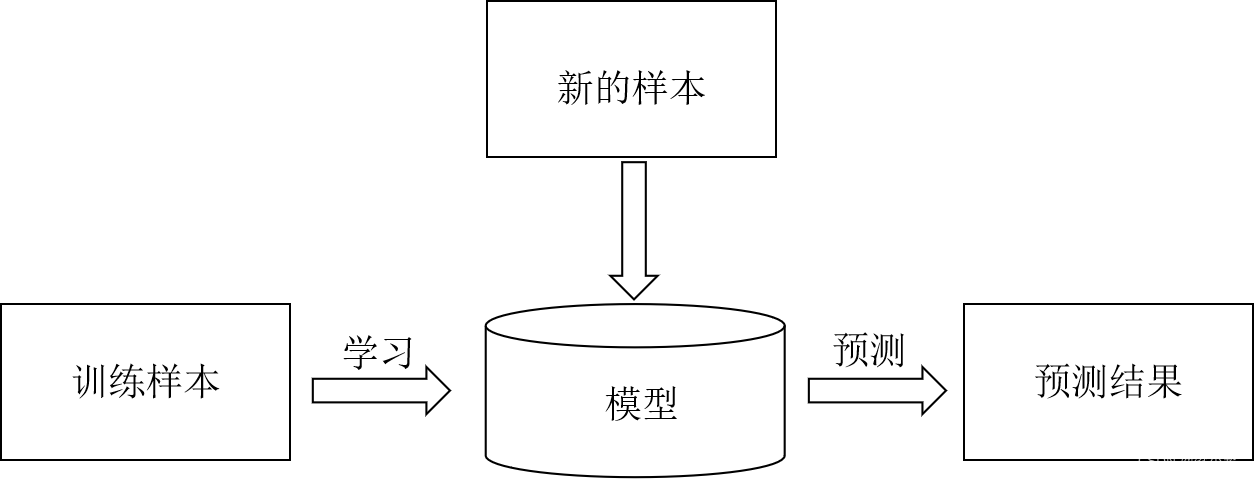
图1.3
上面的过程是有监督学习的一般流程。机器学习算法通常需要大量的样本数据,是一种数据驱动的方法。
机器学习(Machine Learning,ML)是人工智能的分支和一种实现方法,它根据样本数据学习模型,用模型对数据进行预测与决策(也称为推理Inference)。机器学习让计算机算法具有类似人的学习能力,像人一样能够从实例中学到经验和知识,从而具备判断和预测的能力。
机器学习的本质是模型的选择以及模型参数的确定。也就是说机器学习算法是要确定一个映射函数以及函数的参数
,建立如下映射关系:
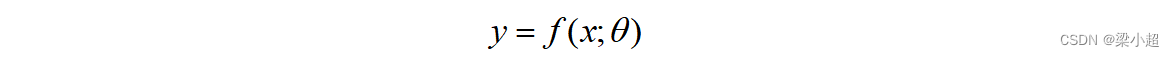
其中,x为函数的输入值,一般是一个向量:
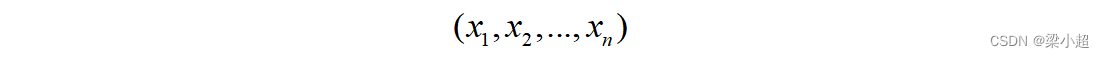
y为函数的输出值,是一个向量或者标量。当映射函数和它的参数确定之后,给定一个输入就可以产生一个输出。
映射函数没有特定的限制,上面水果分类的例子的映射函数是最简单的线性函数,也可以选择合适的非线性函数。
1.1.2机器学习的必要性
在20世纪80年代之前,人工智能技术解决各类问题的主流方法是逻辑推理、知识工程与专家系统,它们为人类的知识建立规则库,依靠规则库进行推断与决策以实现人工智能。以垃圾邮件过滤为例,其目标是确定一封邮件是否为垃圾邮件。如果使用人工规则的方法,通常是设定一些关键词,例如:发票、代开、代购、酒店、折扣、特价,它们是垃圾邮件中经常出现的词,如果一封邮件中出现这些关键词则认为是垃圾邮件。这种方法高度依赖于人类对具体问题的专业知识,而且通用性较差,人们需要对每个问题建立精细规则,对于复杂问题来说这是一件比较困难的事。
以图像识别为例,假如要判断一张图像是不是猫,最简单的做法的穷举,即列举图像所有可能的情况,然后建立一个规则库,将每种可能的图像标记为猫或者非猫。如果图像的长和宽都是512像素,图像是灰度的(每个像素点只有一个采样颜色),每个像素是0~255的整数。根据排列组合的原理,所有可能的图像数有:
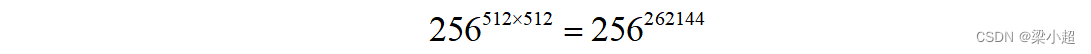
这是一个天文数字,要对如此海量的情况建立一个规则库显然是不现实的。
20世纪80年代开始,机器学习逐渐成为解决人工智能问题的主流方法。机器学习与之前基于人工规则的模型相比,无需人工给出规则,而是让程序自动从大量的样本中抽象、归纳出知识与规则。因此,它具有更好的通用性。
1.2典型应用
语音识别:理解人说话的声音信号,将它转化成文字。语音识别算法是语音输入法、人机对话系统等应用的关键技术。
人脸检测:找出图像中所有的人脸,确定它们的大小和位置。人脸检测是机器视觉领域被深入研究的经典问题,在安防监控人机交互等领域都有重要的应用价值。数码相机、智能手机上已经使用已经使用人脸检测技术实现成像时对人脸的对焦。
人机对弈:人机对弈属于策略类问题,它是人工智能的传统问题,象棋、围棋等在过去几十年是检验人工智能进展的代表性问题。
机器翻译:将一种语言的语句转换成另外一种语言的语句,二者有相同的语义。早期的实现大多基于规则的方法,后来逐渐过度到使用机器学习的方法。
自动驾驶:自动驾驶需要解决多方面的问题,例如环境感知,需要准确检测道路、车道线、行人、障碍物等,还要识别出交通标志、信号灯等重要信息;路径规划,指定车辆的当前位置和目的地,计算出到达目的地的一条可行路径,行驶期间可能还需要根据路况信息做出调整。
名词解释
训练样本:指的是用于训练机器学习模型的数据集的一个或多个实例。这些实例通常包含输入特征和对应的目标输出值(对于监督学习问题)。
特征向量:用于表示数据点的属性,这些属性被用作模型的输入。
类别标签:用于标识数据样本所属的类别或分类。
决策函数:是一个数学函数、一个统计模型、一个神经网络等,用来描述输入数据和输出之间的关系。
决策变量:决策变量是指在决策过程中可以改变的因素,这些因素能够影响到决策的结果。
有监督学习:使用已知标签或输出值的训练数据集来训练模型,使模型能够学习从输入到输出的映射关系。
参考文献
雷明. 机器学习——原理、算法与应用.清华大学出版社.















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









