







2.2概率论
如果把机器学习处理的变量看成是随机变量,则可以用概率论的方法建模。本节简单介绍机器学习将要使用的概率论知识。
2.2.1随机事件与概率
随机事件a是指可能发生也可能不发生的事件,它有一个发生概率p(a),且该概率值满足如下约束:
即概率值为0~1,这个值越大,事件越可能发生,如果一个随机事件发生的概率为0,称为不可能事件;如果一个随机事件发生的概率为1,则称为必然事件。例如:抛一枚硬币,可能正面朝上,也可能反面朝上,两种事件发生的概率是相等的,各为0.5。
2.2.2条件概率
对于两个相关的随机事件a和b,在事件a发生的条件下事件b发生的概率称为条件概率p(b|a),定义为:
即a和b同时发生的概率与a发生的概率的比值。如果事件a是因,事件b是果,则概率p(a)称为先验概率。后验概率定义为:
先验概率是指根据以往经验分析得到的概率,往往作为“由因求果”问题中的“因”出现的概率。
后验概率是指事件已将发生了,有多种原因,判断事情的发生是由哪一种原因引起的,是“由果求因”。
贝叶斯公式指出:
变形后为:
贝叶斯公式描述了先验概率和后验概率之间的关系。如果有p(b|a)=p(b),或者p(a|b)=p(a),则称随机事件a和b独立。如果随机事件a和b独立,则有:
将上面的结论进行推广,如果n个随机事件 相互独立,则它们同时发生的概率等于它们各自发生的概率的乘积:
2.2.3随机变量
随机变量是一个随机事件结果的可能数值。它分为离散型和连续型两种,离散型随机变量的取值为有限个或者无限可列个(例如整数集),连续性随机变量的取值为无限不可列个(例如实数集)。
描述离散型随机变量分布情况的是概率质量函数,它由随机变量取每个值的概率 依次排列组成。它满足:
下表是一个随机变量概率质量函数的例子:
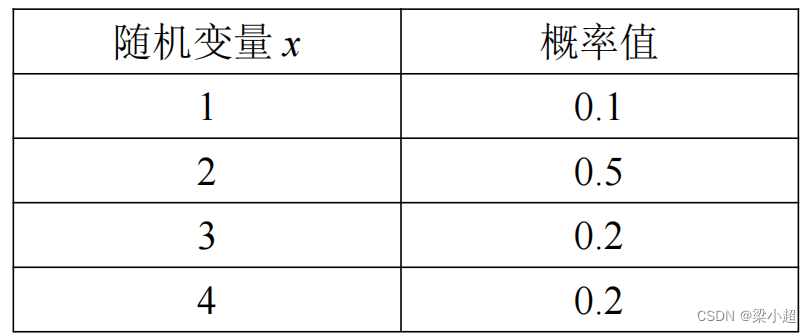
把概率质量函数推广到无限的情况,就可以得到连续型随机变量的概率密度函数。一个函数如果满足如下条件,则可以称为概率密度函数:
这可以看作离散型随机变量的推广,积分值为1对应于取各个值得概率之和为1。分布函数是随机变量 的概率,它是概率密度函数的变上限积分,定义为:
最常见的连续型概率分布是正态分布,也称高斯分布。它的概率密度函数为:
其中, 和
分别为均值和方差。现实世界中的很多数据,例如人的身高、体重、寿命等都近似服从正态分布。另外一种常见的分布是均匀分布,如果随机变量x服从[a,b]的均匀分布,则其概率密度函数为:
伯努利分布也是一种常见的分布,这是一种离散型随机变量的概率分布,变量取值只有0和1,取这两种值得概率为:
其中,p为[0,1]得一个实数。对于二分类问题,分类结果可以看作伯努利分布。
2.2.4数学期望与方差
数学期望是加权平均值的抽象,是随机变量在概率意义下的均值。对于离散型随机变量x,数学期望定义为:
例如前面的概率质量函数的表格,它的数学期望为:
1×0.1+2×0.5+3×0.2+4×0.2=2.5
方差定义为:
对于前面表格中的随机变量,它的方差为:
推广到连续型随机变量的情况,假设有一个连续型随机变量x的概率密度函数是f(x),其数学期望定义为:
连续型随机变量的方差定义为:
方差反应的是随机变量取值变化的程度,方差越小,随机变量的变化幅度越小,反之越大。
2.2.5随机向量
前面定义的随机变量是单个变量,如果推广到多个变量,就得到随机向量。随机向量x是一个向量,它的每个分量都是随机变量。同样,随机向量有离散型和连续型两种情况。描述离散型随机向量分布的是联合概率质量函数:
对于二维离散型随机向量,这是一个二维表:
描述连续型随机向量的是联合概率密度函数,这是一个多元函数。如果是二维随机向量,则其联合概率密度函数满足:
更高维的概率密度函数也需要满足这两个条件。
对于离散型随机向量,边缘概率定义为:
对于连续型随机向量,边缘密度函数定义为:
条件概率密度函数定义为:
有了条件概率密度函数,就可以定义两个随机变量之间的独立性:
显然,如果两个随机变量独立,则有:
协方差描述两个随机变量总体误差的期望,它能够描述两个变量的相关程度,定义为:
对于n维随机向量x,其任意两个分量 和
之间的协方
差组成的矩阵称为协方差矩阵,协方差矩阵是一个对称矩阵。
将一维的正态分布推广到高维,可以得到多维正态分布概率密度函数:
其中,x为n维随机向量, 为均值向量,
为协方差矩阵。
2.2.6最大似然估计
有些应用中已知样本服从的分布,例如服从正态分布,但是需要估计分布函数的参数 ,例如均值和协方差。确定这些参数常用的一种方法是最大似然估计。
最大似然估计(Maximum Likelihood Estimate,MLE)构造一个似然函数,通过让似然函数最大化求解出 。
假设样本服从的概率密度函数为 ,其中,x为随机变量,
为要估计的参数。给定一组样本
,它们都服从这种分布,并且相互独立。构造如下似然函数:
这是一个关于 的函数,要让该函数的值最大化,这样做的依据是应该最大化这组样本发生的概率。即求解如下最优化问题:
乘积求导不易处理,因此对该函数取对数,得到对数似然函数:
最后要求解的问题变为:
这是一个不带约束的优化问题,可以用梯度下降法或者牛顿法直接求解析解。后面讲解算法时我们会对这两种求解方法进行讲解。
参考文献
雷明. 机器学习——原理、算法与应用.清华大学出版社.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









