感受
要想理解的原理XGBoost,就要对GBDT,CART很熟悉,XGBoost的原理还是很新颖的,XGBoost用了泰勒展开式,求的二阶导数,推导过程并不难,就是式子很难写,我在关键的地方都标注了详细的解析,如果有不懂的地方,请留言哈。所以要特别注意,要看懂本文的内容,就需要对很多基础概念有一定的了解,读者可以参考一篇博客,然后再回过来看详细解析,链接为:
通俗讲解
介绍
XGBoost全称eXtreme Gradient Boosting。它是Gradient Boosting Machine的一个C++实现,作者为陈天奇。Xgboost的最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进提高了精度。论文提到了XGBoost的几个主要特点:
(1)
基于树的能够自动处理稀疏数据的提升学习算法;
(2)
采用加权分位数法来搜索近似最优分裂点;
(3)
并行和分布式计算;
(4)
基于分块技术的大量数据高效快速处理;
基于以上这些特性,XGBoost使得我们能够在有限的资源条件下高效快速的实现大规模数据的任务处理。除了这些特性外,XGBoost还有一个有别于GBDT、AdaBoost等传统算法的特点:以加入了正则化项的结构化损失函数为优化函数。这也进一步减小了其生成模型过拟合的风险。
1基本概念
1.1函数空间中的优化问题
引入了函数空间的概念后,就可以方便的使用损失函数的导数等概念并借助常规的优化算法来学习弱学习器。机器学习的监督学习问题中,我们的目标是在提出的假设空间H中找到一个最优的假设F*(x)∈H使得它具有最小的泛化误差。
Ψ(y,F(x))为损失函数。
假设我们的训练数据集D包含N个样例:
我们从假设空间中任选一个假设F(x),在训练集上对每一个样本进行映射就可以得到一个N维点
P=F(x)=(F(x1),F(x2),…,F(xN))
此时我们的损失可表示为
由于联合分布P(X,Y)未知,所以我们只能用训练数据的平均损失作为期望损失的无偏估计。当我们选取不同的假设时,就会得到不一样的P,进而得到不同的损失值。那么P就相当于是一个N维空间中的向量,而损失就是变量P的函数值。此时问题就变成了在一个N维空间中的优化问题。
如式1.1所示,P通常是一个无限维度的变量(X通常有无限个取值),并且我们的优化应该是针对y在x上的边缘分布下损失函数值的期望最小化进行,但由于现实中我们只能拿到有限个数的训练数据,并且联合分布P(X,Y)通常是为止的,所以只能基于训练数据把每一个函数变量F(xi)当做一个维度,用P=F(x)=(F(x1),F(x2),…,F(xN))来近似代替真实的函数点。即
Pi表示用假设空间中的函数Fi∈H在训练集D上针对每一个样本进行映射而得到的一个N维点。P就是优化问题1.3的可行域,它通常是一个无限N维点击,即它是凸集。那么寻找最优假设的问题可以描述如下:
如果我们的损失函数是一阶连续可导甚至高阶连续可导的话,就可以借用导数相关的优化算法(比如线性搜索法,这是Gradient Boosting算法采用的搜索方法)在空间P中找到一个使得ψ(P)取极小值的点P*,此时对应的假设就是我们期望训练到的最优假设F*.
1.2分步加性模型
分步加性模型是大多数Boosting算法的核心。集成学习的主要手段就是反复训练多个模型,并将这些模型通过一定方式组合在一起,形成一个高性能的强大的集成模型。在Boosting算法体系中一般采用迭代串行的形式生成一系列模型,然后将这些模型进行线性加权相加,得到最终集成学习器。假设已经迭代到m-1次,得到的集成模型为
在下一次迭代中,我们要训练fm(x),它应该是让新生成的集成模型在训练集上损失最小的模型
对于每一次迭代后更新得到的新集成模型Fm(m=1,2,…,T),将它作用于训练集D中的每一个样本,就可以得到一个N维向量
经过T次迭代后就得到一系列的集成模型Fm∈{F1,F2,…,FT},分别将他们作用于训练集,就得到一系列N维的点
随着m的增大我们的模型Fm的训练误差ψ(Y,Fm(X))会越来越小,如果无限迭代下去,理想情况下训练误差就会收敛到一个极小值,相应的序列Pm会收敛到一个极小值点P*。我们把Fm(X)看成是在N维空间中的一个一个的点,而损失函数就是这个N维空间中的一个函数,我们要某种逐步逼近的算法来求解损失函数的极小值(最小值)。把我们的思维切换到N维空间P中,当我们已经迭代了前m-1次后,得到的集成模型如式1.5,此时我们在N维空间P中处于点
那么要搜索的下一个点就是Pm,这个点该怎么搜索呢?这是boosting算法的核心。
2.Gradient Boosting算法原理
第1节我们提到对于搜索下一个点Pm的方法,优化理论里有一种简单的算法就是线性搜索。假设我们的损失函数至少是一阶连续可导的,那么我们可以在点Pm-1处对损失函数求导,得到损失函数在该点的负梯度ρm-1
然后再点Pm-1处沿着负梯度方向即在射线
上搜索使得损失最小的点Pm
而这种方法正是Gradient Boosting算法采用的搜索方法。下面是Gradient Boosting算法的通用流程:
下面我将推导一下Gradient Descent方法的通用形式
假设我们的模型能够用下面的函数来表示,P表示参数,可能由多个参数组成,P = {p0,p1,p2….},F(x;P)表示以P为参数的x的函数,也就是我们的预测函数。我们的模型是由多个模型加起来的,β表示每个模型的权重,α表示模型里面的参数。为了优化F,我们就可以优化{β,α}也就是P。
对于模型的参数{β,α},我们可以用下面的式子来进行表示,这个式子的意思是,对于N个样本点(xi,yi)计算其在模型F(x;α,β)下的损失函数,最优的{α,β}就是能够使得这个损失函数最小的{α,β}。
写成梯度下降的方式就是下面的形式,也就是我们将要得到的模型fm(x)的参数{αm,βm}能够使得fm的方向是之前得到的模型Fm-1(x)的损失函数下降最快的方向:
对于每一个数据点xi都可以得到一个gm(xi),最终我们可以得到一个完整梯度下降方向
为了使得fm(x)能够在gm(x)的方向上,我们可以优化下面的式子得到,可以使用最小二乘法:
推导过程到这里就讲完了。
从图2.1看到,Gradient Boosting算法首先利用训练数据训练一个常数值函数
相当于我们在搜索最优解时选定一个初始点P0=F0(X),如果我们的损失函数是平方损失的话,F0(X)=∑_(i=1)^N▒wiyi,即为加权平均值。其实,这个初始点是可以随便选取的,如果损失函数是凸函数,则一定可以搜索到最小值点,如果不是凸函数,我们选取的不同的初始点有可能得到不同的极小值点。即可能得到不同的集成模型。
在选定了初始点(生成了第一个弱学习器)后,下一个弱学习器该怎么生成呢?Gradient Boosting的思路是:既然我们有了第一个初始点P0=F0(X),那么我们就可以求出损失函数ψ(y,F(X))在点F0(X)处的负梯度
每一个样本都对应负梯度的一个分量
我们现在想要生成下一个弱学习器f1,让它在训练集D上的输出P1=(f1(x1),f1(x2),…,f1(xN))与-∇ψ(F0(X))尽量相同,即利用f1(X)得到负梯度的近似值。我们用yi代替原始训练集中的目标变量(类标签或实数值)yi,得到一个新的样本(xi,yi),每一个样本都这样做暂时性的替换后得到新的训练集D={(x1,y1),(x2,y2),..,(xN,yN)}。因为yi∈R,训练f1(X)就变成了一个回归问题。
通常我们会采用CART回归树来训练弱学习器,训练f1就跟我们平常使用CART回归树训练模型是一样的过程了。在得到f1后,就相当于模拟出了负梯度方向,那么又如何确定步长λ1呢?在CART回归树中,每一个叶子结点的输出的值都是一样的,Gradient Boosting算是将负梯度按照叶子结点为单位划分为L(L为叶子结点)个区间,然后在各个叶子结点中对处于该结点上的负梯度分量所确定的方向上寻找最佳步长λn(n为λ的下标),l∈{1,2,…,L},这样就会大大简化最佳步长的确定问题,尤其是当我们的损失函数采取绝对值损失时,每个叶子结点的输出值直接为该结点上残差的中位数。
按照同样的方法,我们逐步迭代,直到达到预先设置的迭代次数T后,我们就得到了最终的模型
即在给定一个初始点P0=F0(x),经过T次迭代后我们搜索到了点PT=FT(X),想要提高精度(降低误差)就增大搜索次数T.
这就是Gradient Boosting算法的主要思想,它是通过优化经验损失函数在通过迭代反复拟合损失函数的负梯度并利用线性搜索法来生成最优的弱学习器fm和系数αm.而XGBoost算法是通过优化结构化损失函数(加入了正则项的损失函数,可以起到降低过拟合的风险)来实现弱学习器的生成,并且XGBoost算法没有采用上述搜索方法,而是直接利用了损失函数的一阶导数和二阶导数值,并通过预排序、加权分位数、系数矩阵识别以及缓存识别等技术大大提高了算法的性能。
3. XGBoost算法原理
3.1XGBoost的损失函数
XGBoost算法是基于树的Boosting算法,并且其优化的目标函数引入了正则化项
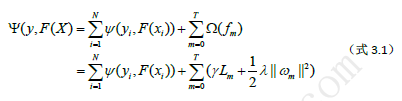
(公式第一行等号左边少了一个括号)
上式中Lm表示m次迭代中生成的树模型ƒm的叶子结点数,ωm=(ωm1, ωm2,…, ωmLm)表示ƒm各个叶子结点的输出值。ℽ和λ是正则化系数,从直观上我们能看出这两个值能对模型的复杂度和输出值起到很强的控制,当ℽ和λ都为零时,只剩下经验风险部分,即生成的树的规模和输出值不受限制。在引入了正则化项后,算法会选择简单而性能优良的模型,上式中右端的正则化项∑_(m=0)^T▒〖Ω(fm)〗只是用来在每次迭代中抑制弱学习器ƒm(X)过拟合的,并不参与最终模型的集成。另外,XGBoost要求ψ至少是二阶连续可导的凸函数。
XGBoost算法也是采用分步前向加性模型,只不过在每次迭代中生成弱学习器后不再需要计算一个系数,模型形式如下:
这跟采用绝对值损失的GBDT的形式是一样的。
接着第2节的内容我们继续。假设Pm-1=Fm-1(X),(m-1为下标)处,Gradient Boosting算法是学习一个弱学习器ƒm来近似损失函数在Pm-1=Fm-1(X),(m-1为下标)处的负梯度。而XGBoost则是直接先求损失函数在该点处的泰勒近似值,然后通过最小化该近似损失函数值来训练弱学习器ƒm。在点Pm-1=Fm-1(X)处对损失函数做一阶近似(省去二阶及以上的部分):
补充:很多人可能泰勒展开式也忘了,所以这里把它写出来方便大家理解
泰勒公式是将一个在x=x0处具有n阶导数的函数f(x)利用关于(x-x0)的n次多项式来逼近函数的方法。若函数f(x)在包含x0的某个闭区间[a,b]上具有n阶导数,且在开区间(a,b)上具有(n+1)阶导数,则对闭区间[a,b]上任意一点x,成立下式:
其中,f(n)(x),(n为上表),等号后的多项式称为函数f(x)在x0处的泰勒展开式,剩余的Rn(x)是泰勒公式的余项,是(x-x0)^n的高阶无穷小。
然后回到正题,我们取x0=Fm-1(xi),x取Fm-1(xi)+fm(xi)(其中m-1和m为下标,i也为下标)就可以照葫芦画瓢推出上面的约等于的那个式子了,读者可以自己去看看。
上式中
为损失函数在点Pm-1(X)处对第i个分量Fm-1(xi)的一阶偏导数,
为损失函数在点Pm-1(X)处第i个分量Fm-1(xi)的二阶偏导数。这样我们就可以以ψm作为我们的近似优化目标函数。Pm=Fm(X)是一个N维的点。那么ƒm(X)也是一个N维向量,因为
所以,我们可以把ƒm(X)=( ƒm(x1), ƒm(x2),…, ƒm(xN))看成是N维空间中的点Pm(X)相对于点Pm-1(X)的一个增量。那么我们现在的目标就是要找到一个最优的增量使得损失函数在下一个点的损失最小
我们对(式3.3)做个变形,
上是右端第一项对于第m次迭代来说是常数,将其去掉不会影响我们优化的结果,因此,优化函数变成如下形式:
3.2确定各叶子结点的最有输出值
假设我们在第m轮迭代中已经生成了一棵树,它有L个叶子结点{l1,l2,…,lL},设Ij={i|q(xi)=j}表示落在第j个叶子结点的样本的索引号,q表示第m轮生成的树的结果,它将一个样本x映射到一个相对应的叶子结点。
原论文中λ写在后面,这里为了清晰直观,我把它挪到前面了。在第m轮迭代中由于ℽL是常数,所以最小化ψ-m(-在ψ的上面,m为下标)就可以通过分别在每个叶子结点中极小化损失值ƒ(ωj)来实现。因为前面我们要求损失函数ψ(y,F(x))是凸函数,因此由∑_(i∈Ij)▒〖hi≥0〗,另外正则化系数λ≥0,所以
这样就可以计算出ψ-m(-在ψ的上面,m为下标)的最小值为
其中q表示第m轮迭代中生成的树的结构,上式的值代表了第m次迭代中生成的模型带来的损失减小值,明显
ψ-m(q)(-在ψ的上面,m为下标)的值越小,则第m个模型加入后得到的新集成模型Fm(X)相对于Fm-1(X)减小的损失函数值就越大。
从(式3.7)和(式3.8)我们可以看到,使得第m轮生成的模型Fm(X)=Fm-1(X)+ƒm(X)的损失最小的树q,其每个叶子结点的最优输出值确定只由损失函数ψ在点Fm-1(X)的一阶导数g=(g1,g2,…,gN)和二阶导数h=(h1,h2,…,hN)决定。所以在第m轮迭代时,只要我们预先计算出g和h,在训练生成一颗树模型后就可以直接算出每个叶子结点的最优输出值。那么现在的关键是根据什么条件来生成一颗合适的树呢?作者提出在生成树的过程中,在每个叶子结点的分裂判定时利用“最大损失减少值”的原则来选择最优的分裂属性和分裂点。
3.3分裂条件
传统的CART回归树的分裂条件式均方差(或绝对值偏差等)减小最大的点作为分裂点。但XGBoost没有这么干,它在树的生成过程中依旧只接住了3.1小节提到的损失函数的一阶和二阶导数值,这些值都是在第m轮中提前计算好的。
假设我们从一个初始的结点(根结点)开始,I表示该结点上所有样本的索引集,现在我们要对该结点进行分裂,设IL,IR分别为分裂后左右子结点中样本的索引集,并且有I=IL∪IR。那么根据(式3.8)我们可以计算出分裂前后第m个树模型的损失函数值减小量为
这个公式跟我们之前遇到的信息增益或基尼指数的公式一样。XGBoost就是利用这个公式计算出的值作为分裂条件,在每一个结点的分裂中寻找最优的分裂属性和分裂点。这样我们就能顺利地得到我们在第m轮迭代中所需要的最优的模型ƒm(X)。
3.4弱学习器的集成
通过上述算法经过T次迭代我们得到T+1个弱学习器,(f0(X),f1(X),…,fT(X)),那么怎样将它们集成起来呢?其实是直接将T+1个模型相加,只不过为了防止过拟合,XGBoost也采用了shrinkage方法,来降低过拟合的风险,其模型集成形式如下
Shringkage技术最早由Friedman于1999年在论文《Greedy function approximation: A gradient boosting machine》中提出。通常η取较小的值时会使得模型的泛华能力较强,该参数与迭代次数T高度负相关(较大的η值对应着相对较小的迭代次数T)。为什么要乘上一个η值呢?大致有以下三个原因:
1.
训练数据有限,存在一定的信息丢失;
2.
训练数据中存在一些噪声信息;
3.
如(式1.1)所示,我们应该是在由每一个不同的x对应一个维度所构成的N(N可能无穷大)维空间中去拟合模型F*(X),该模型对于一个确定的x所给出的预测的损失的期望Eyψ(y,F*(x))应该最小。但是我们的算法是把训练数据中的每一个样本都当做了一个不同的维度。这样必然会导致Pm=(Pm1,Pm2,…,PmN)与真实的Pm存在偏差。
上述三个因素的存在,如果我们依然在每一次都取最优的fm(X),就极有可能导致各个弱学习器过拟合。因此通过对f(X)给出的最优值乘以一个小于1的系数,让该模型尽量只学习到有用的信息,以抑制它过拟合。
关于η和迭代次数T的取值,可以通过交叉验证得到合适的值,通常针对不同的问题,其具体值是不同的。一般来说,当条件允许时(如对模型训练时间没有要求等)可以设置一个较大的迭代次数T,然后针对该T值利用交叉验证来确定一个合适的η值。但η的取值也不能太小,否则模型达不到较好的效果。
除了利用Shrinkage技术来抑制过拟合外,XGBoost在构造树模型过程中也借用了随机森林中随机选择一定量的特征子集来确定最优分裂点的做法,以达到抑制过拟合的目的。特征子集越大则每个弱学习器的偏差就越小,但方差就越大。
4.XGBoost的优化
4.1分裂点的搜索算法
在分裂结点时,跟大多数基于树的算法一样,XGBoost也实现了一种完全搜索式的算法(Exact Greedy Algorithm)。这种搜索算法会遍历一个特征上所有可能的分裂点,分别计算器损失减小量,然后选择最优的分裂点。这种算法在scikit-learn、R语言中的gbm包等常见库中都实现了。其优点是能够搜索到最优的分裂点,但缺点就是数据量很大时比较浪费计算资源。当我们的训练数据量很大,以致内存无法一次性加载完成或者在分布式计算环境下,该算法就无能为力。
为此XGBoost同时实现了一种基于特征值分位数的近似搜索算法。该算法首先是根据训练数据中某个特征K的取值的分布情况,选取l个分位数Sk={sk1,sk2,…skl},利用这l个分位数将特征K的取值去加截断为l+1个子区间。然后分别在每个子区间中将该区间中各个样本在当前迭代中的一阶导数和二阶导数求和,得到该区间的一阶和二阶导数的汇总统计量。后面在寻找最优分裂点时就只搜索这l个分位数点,并从这l个分位数点中找到最好的分裂点作为该特征上最优分裂点的近似。
XGBoost算法在计算特征k的分位数时并没有按照均匀分位的方式将样本等分到各个区间,而是采用了加权求分位数的方式。那这个权重是怎么来的呢?式3.4稍微变形就得到了
上式中的第二项在原文中用constant来表示,它可以被看成是某种正则化项,那么第一项就是一个标准的平方损失的表达式,只不过此时样本xi对应的输出的值变成了gi/hi,而其权重恰好就是hi。所以,在XGBoost算法里,在第m轮迭代中计算特征值的分位数时是把损失函数在各个样本点的二阶导数作为其样本权重。样本权重代表的就是概率,概率越大表示该点出现的次数或是该点附近的值出现的次数就越多。XGBoost算法依据该权重分步来选取分位数。其具体分位数计算如下:
1.首先将训练集样本根据特征k的值从小到大的顺序进行排列;
2.选定一个合适的权重累积阈值ϵ,将总的权重分成1/ε等份(等分数即为区间数+2);
3.对于i=0,1,2,…,[1/ε]循环执行如下操作
设定hiv=0,然后从第一个样本开始遍历,并累加各样本的权重hiv+=hi,当hiv>ε时,停止累加,并将已经遍历过样本归入第i个区间,得到第i+2个分位数。
对于第(3)步求分位数中,第1个和最后一个分位数是例外,它们默认为特征k的最小值和最大值。
对分位数的计算XGBoost也实现了两种形式,一种是在每次迭代中只生成一次全局的分位数,然后在树的各层中均使用相同的分为数值。另一种是每一次分裂后都对每一个新结点上所有样本按照同样方式重新计算加权分位数。
4.2稀疏数据的自动识别
在现实生活中,我们的数据包含大量缺失值,零值或是由于我们在做哑变量时引入的零值,这种情况下我们就认为训练数据是稀疏的。
XGBoost算法实现了一种自动处理缺失数据的算法,即通过默认值形式或是我们认为某个值为缺失值的形式,在构造树模型过程中,选择最优分裂点时只利用那些非缺失值,而缺失值一概跳过。
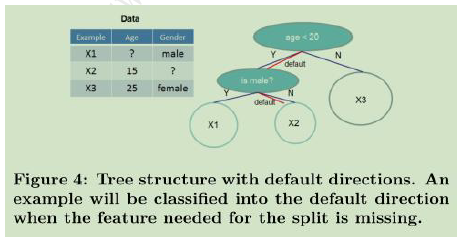

如果某个样本在特征k上的值缺失,分别考虑将其分到左子结点和右子结点(把在该特征上含缺失值的所有样本要么全部放进左子结点要么全部放进右子结点),根据不同的选择方向可以得到两个不同的模型,最后以两个模型中最优的模型对含有缺失值的样本分裂方向为最优方向。所以这个含有缺失值样本的分裂方向是根据训练数据自动学习到的。
4.3 其他计算性能优化
为了减小CART树构造过程中的计算开销,XGBoost在构造CART树之前先构造一个经过压缩处理的数据块,该数据块中存储的是按照各特征值排序后对样本索引的指针。每次寻找最优分裂点时只需要在这个数据块中依次遍历,然后根据其指针来提取各样本的一阶导数和二阶导数即可。这样就不必反复地进行拍虚了,大大提高了计算的速度。
由于在寻找最优分裂点时XGBoost使用的是数据块中各个特征值对应的指针来间接获取对应样本的导数值,虽然数据块中的数据是连续的,但其指针对应的样本的导数值不是连续存储的,所以就需要频繁的访问内存中不连续的区域,而缓存中通常存放的是我们最近一次访问地址的附近区域的数据,所以对于我们要访问不连续的数据是极有可能不同时存在于缓存中的。如果要获取的样本点的导数值恰好不在当前缓存中,CPU就必须访问内存,这就延长了处理时间。为了解决这个问题,XGBoost采用了Cache-aware Access技术来降低处理时间。
另外,当我们需要处理的训练数据非常大,以至于内存无法一次加载完成时,传统的方法就难以对付。XGBoost提出了Block Compression技术,它将整个训练数据集切割成多个块(block),并将其存储在外存中。在训练模型时XGBoost通过一个单独的线程来讲需要处理的某个数据块预加载到主存缓冲区,以实现处理操作在数据上的无缝衔接。XGBoost不是简单的将数据分块存放在外存中,而是采用一种按列压缩的方法对数据进行压缩,并且在读入时利用一个单独的线程来实时解压。另外,XGBoost还通过将数据分散到多个可用的磁盘上,并为每一个磁盘设置一个数据加载线程,这样就能同时从多个磁盘向内存缓冲区加载数据,模型训练线程就能自由地从每个缓冲区读取数据,这大大增加了数据吞吐量。这些技术的实现一是为了提高模型训练的效率,二是为了提升XGBoost处理大量数据的能力,充分利用计算机有限的资源。
参考文献
[1].机器学习中的数学(3):模型组合之 Boosting 与 Gradient Boosting.
http://blog.jobbole.com/88193/
[2]. 泰勒公式.
https://baike.baidu.com/item/%E6%B3%B0%E5%8B%92%E5%85%AC%E5%BC%8F/7681487?fr=aladdin
[3].Drxam, XGBoost 原理解析. yuwei8905@126.com








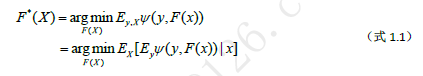
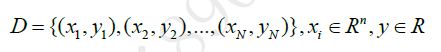
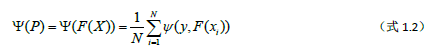
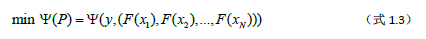
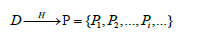
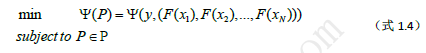

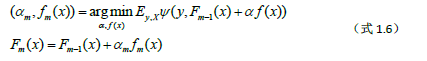
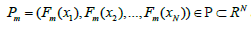
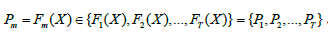


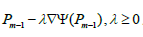
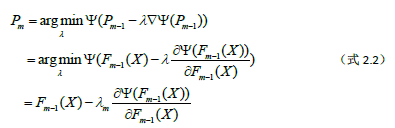


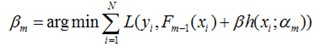
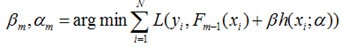
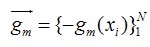
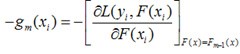
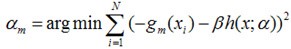
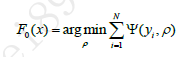
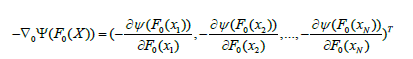
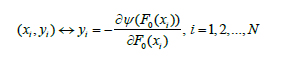
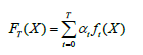

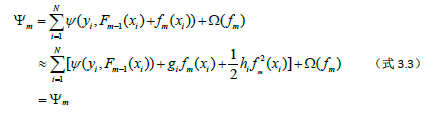
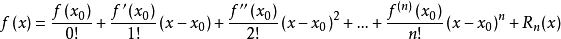
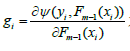
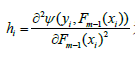
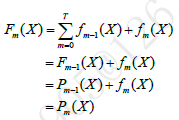
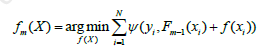
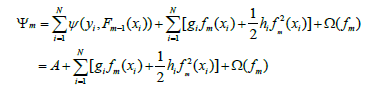
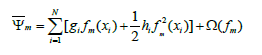
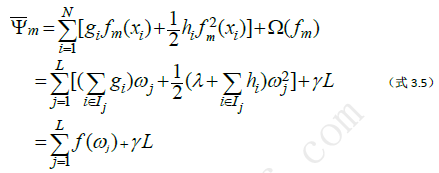
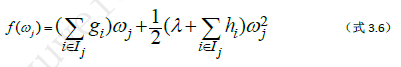
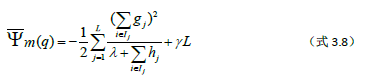
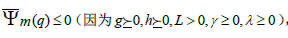
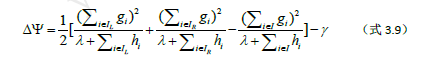
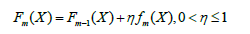

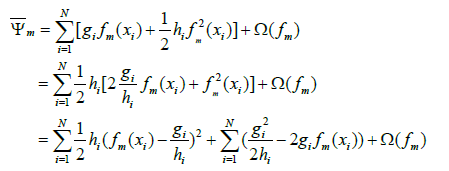

















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











