







最近在学习定位算法时有涉及到利用svm方法来实现定位的,所以就把近来学习到的一些知识做一些摘抄和总结。
详细地可以从前辈的博客看到:这里写链接内容
http://www.eefocus.com/xuqiong89/blog/13-06/295127_b24ea.html
来理解学习。
一、首先要明确一些基本概念:
1、VC维:定义是对于一个函数指标集若存在h个样本被函数按所有可能的2^h种形式打散,则h就是该指标函数集的VC维。可以理解为是对于一个分类函数的复杂度的一个度量VC维越大分类函数越复杂。
##2、衡量工具——风险:使用数据样本上的分类与真实结果的误差,但这只是经验误差,他只对于该样本有较好的结果所以引入了置信风险,合起来使得结构风险最小:
R(w)<=Remp(w)(经验风险)+Φ (n/h)(置信风险)
置信风险随样本数增多,置信风险(误差)越小;VC维越大,越难推广,风险变大。
#二、问题本质:在n维空间中寻找一个分类平面——超平面(Hyper plane)能够将样本完全分开。
【目标函数g(x)=wx+b实际上就是所求的分类面。在训练阶段我们的目标是利用提供的样本训练求得参数w和b;在分类定位阶段带入xi用g(xi)>0 or<0来分类定位】。
最终把训练阶段归结为一个二次规划问题(针对于二维情况而言):
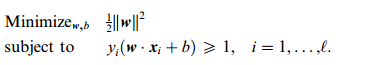
距离超平面最近的样本点距离最大(分的越开)δ=1/11w11反比关系。
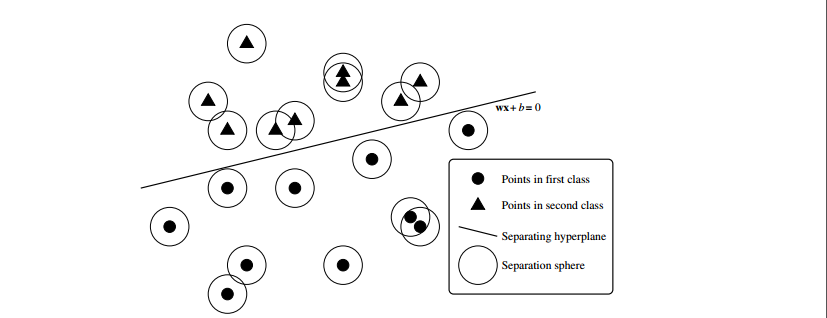
通过以上讨论推出了分类问题的基本结论。然而对于非线性和样本不可分离这两个问题呢?则需要对于它进行一个拓展。
三、对于样本无法完全正确分离
引入了松弛变量ζ和惩罚因子C:
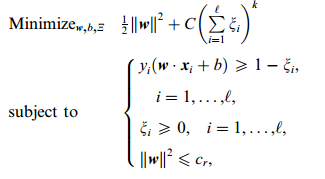
这个式子有这么几点要注意:
一是并非所有的样本点都有一个松弛变量与其对应。实际上只有“离群点”才有,所有没离群的点松弛变量都等于0在迭代求w的时候如何样本点非离群点,即分类正确,那么就设它的松弛变量为0了。
二是松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
三是惩罚因子C决定了你有多重视离群点带来的损失,显然当所有离群点的松弛变量的和一定时,你定的C越大,对目标函数的损失也越大,此时就暗示着你非常不愿意放弃这些离群点。
四是惩罚因子C不是一个变量,整个优化问题在解的时候,C是一个你必须事先指定的值,指定这个值以后,解一下,得到一个分类器,然后用测试数据看看结果怎么样优化问题在解的过程中,C一直是定值,要记住。
四、对于问题的非线性性——引入了核函数
如果有这样的函数,那么当给了一个低维空间的输入x以后,
g(x)=K(w,x)+b
f(x’)=(w,x)+b
这两个函数的计算结果就完全一样,我们也就用不着费力找那个映射关系,直接拿低维的输入往g(x)里面代就可以了。而的确存在着许多的核函数可以实现。也就是说在二维空间的一条双曲线是非线性的,那么当它映射到四维空间就成了一个线性问题【好神奇有木有】。
以上便是我的学习心得,如有涉及版权问题请联系本人。















07-15
 382
382
382
08-24
381
381
01-15
6405
6405
01-20
331
331
08-13
3880
3880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









