







 SOM(Self-Organizing Map)网络是一种无监督的神经网络,用于将高维数据映射到二维平面上,保持数据的相似性。在训练过程中,最佳匹配单元及其邻近神经元的权重会逐渐调整,直到收敛。本文提供了SOM算法的Python代码实现,并展示了对未归一化和归一化数据的训练结果。
SOM(Self-Organizing Map)网络是一种无监督的神经网络,用于将高维数据映射到二维平面上,保持数据的相似性。在训练过程中,最佳匹配单元及其邻近神经元的权重会逐渐调整,直到收敛。本文提供了SOM算法的Python代码实现,并展示了对未归一化和归一化数据的训练结果。
算法简介
SOM网络是一种竞争学习型的无监督神经网络,将高维空间中相似的样本点映射到网络输出层中的邻近神经元。
训练过程简述:在接收到训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成为竞争获胜者,称为最佳匹配单元。然后最佳匹配单元及其邻近的神经元的权向量将被调整,以使得这些权向量与当前输入样本的距离缩小。这个过程不断迭代,直至收敛。
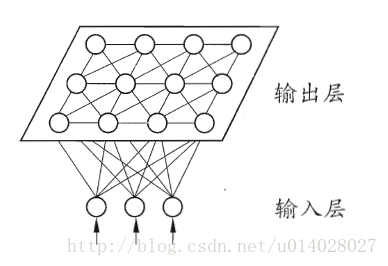
网络结构:输入层和输出层(或竞争层),如下图所示。
输入层:假设一个输入样本为X=[x1,x2,x3,…,xn],是一个n维向量,则输入层神经元个数为n个。
输出层(竞争层):通常输出层的神经元以矩阵方式排列在二维空间中,每个神经元都有一个权值向量。
假设输出层有m个神经元,则有m个权值向量,Wi = [wi1,wi2,....,win], 1<=i<=m。
算法流程:
1. 初始化:权值使用较小的随机值进行初始化,并对输入向量和权值做归一化处理
X’ = X/||X||
ω’i= ωi/||ωi||, 1<=i<=m
||X||和||ωi||分别为输入的样本向量和权值向量的欧几里得范数。
2.将样本输入网络:样本与权值向量做点积,点积值最大的输出神经元赢得竞争,
(或者计算样本与权值向量的欧几里得距离,距离最小的神经元赢得竞争)记为获胜神经元。
3.更新权值:对获胜的神经元拓扑邻域内的神经元进行更新,并对学习后的权值重新归一化。
ω(t+1)= ω(t)+ η(t,n) * (x-ω(t))
η(t,n):η为学习率是关于训练时间t和与获胜神经元的拓扑距离n的函数。
η(t,n)=η(t)e^(-n)
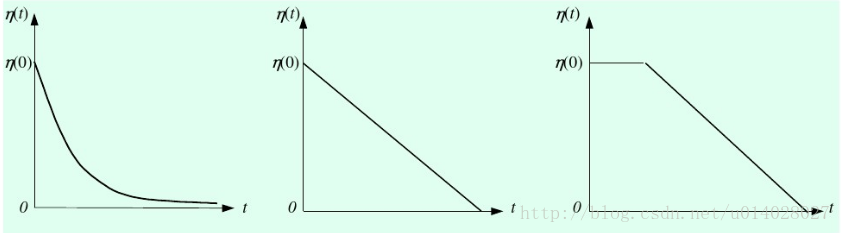
η(t)的几种函数图像如下图所示。
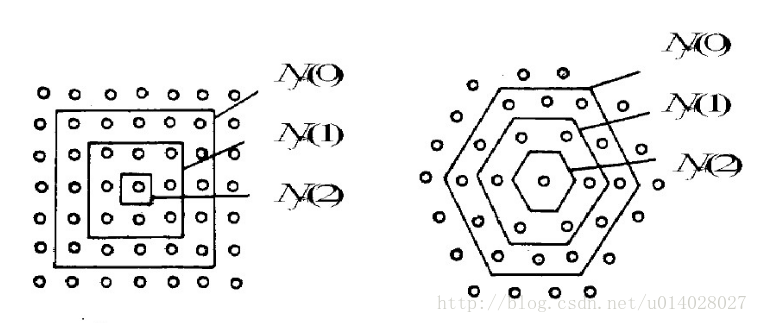
4.更新学习速率η及拓扑邻域N,N随时间增大距离变小,如下图所示。
5.判断是否收敛。如果学习率η<=ηmin或达到预设的迭代次数,结束算法。
python代码实现SOM
import numpy as np
import pylab as pl
class SOM(object):
def __init__(self, X, output, iteration, ba 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









