







 本文详细介绍了图的遍历方法,包括广度优先搜索(BFS)和深度优先搜索(DFS)。BFS适合找单源最短路径,而DFS用于生成树和判断图的连通性。两种遍历方法的空间和时间复杂度也在文中进行了分析。
本文详细介绍了图的遍历方法,包括广度优先搜索(BFS)和深度优先搜索(DFS)。BFS适合找单源最短路径,而DFS用于生成树和判断图的连通性。两种遍历方法的空间和时间复杂度也在文中进行了分析。
图的遍历
定义:图的遍历是指从图中某一顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点访问一次且仅访问一次。
【注】树其实也是一种特殊的图,所以树的遍历实际上也可以看作一种特殊图上的遍历。
顺序表->树->图
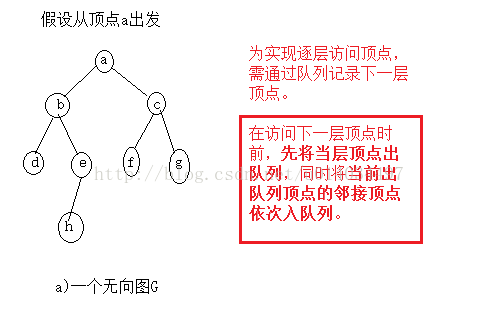
l 广度优先搜索(Breadth-Fist-Search)
【特点】 它是一种分层查找的过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有回退情况,因此它不是一个递归算法。 为了实现逐层访问,算法必须借助一个辅助队列,以记忆正在访问的顶点的下一层结点(否则的话,访问完当层顶点就下层顶点无法访问了)
【遍历过程】
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









