







B站视频网址: https://www.bilibili.com/video/BV1zE411W7Wo?from=search&seid=10914252514621091604



标量对向量求导,得到的梯度也是一个向量,梯度和变量w的维度一样
求出的梯度是这N项的连加,梯度g(w)是w的一个函数。在不同位置上求出梯度也不一样,因为梯度跟w有关,所以并行训练时我们需要把w传来传去

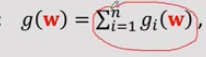 梯度写成g_i(w)连加,因为有n项,n个训练样本,
梯度写成g_i(w)连加,因为有n项,n个训练样本,![]() 每个g_i只与这个样本的x_i, y_i有关,与其他数据样本无关,这就时为什么做并行计算的时候可以把样本划分到多个机器上。每个机器只需要用本地的数据训练一个本地的g_i.
每个g_i只与这个样本的x_i, y_i有关,与其他数据样本无关,这就时为什么做并行计算的时候可以把样本划分到多个机器上。每个机器只需要用本地的数据训练一个本地的g_i.
沿着梯度方向会上升,反方向会下降。
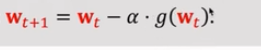 计算梯度g在w_t方向的梯度,然后沿着反方向走一小步到w_t+1。阿尔法是步长或学习率
计算梯度g在w_t方向的梯度,然后沿着反方向走一小步到w_t+1。阿尔法是步长或学习率

整个算法要迭代成百上千轮,每一轮都需要算一个梯度,对每一个样本算一个g_i,然后把他们全都加起来,所以样本越多,特征维度越大,计算量越大。
求神经网络一样,参数越多,样本越多,算梯度越慢。

两块处理器同时计算,加快速度,每块处理器只做了一半的计算,时间就少了一半。两个处理器计算结果![]() 和
和![]() 都是向量。
都是向量。

将两个处理器结果相加就得到了g(w).
复杂的是通信


参数服务器架构,server用来协调多个节点,work用来做计算,

另一种PeerToPeer 点对点的架构,所有节点都是work,邻居之间可以通信


每一轮要等到所有work全完成工作,才能开始下一轮。谷歌只发表了理论,但他的MapReduce不开源,所以有各种开源的MapReduce, 如hadoop,但都达不到谷歌的性能,过几年Spark出现也是mapReduce编程模型,区别在于spark把一切都放内存里而不是磁盘,而且有很好的容错机制,比hadoop快很多。MapReduce模型很适合大数据处理,但用来机器学习并不是很高效。
MapReduce架构是clinet server,有一个节点是server用来协调整个系统,数据都存在work上,计算也由work来做。

server和work可以通信,比如并行梯度下降时,server需要将参数广播出去。

每个work都可以做计算,我们自己定义一个算法,然后所有work都会运行这个函数,这一步是map,map是本地运行,不需要通信。
map是所有work并行做的。做并行梯度下降时,每个work都用自己数据去算一部分梯度。
reduce操纵也需要通信。

reduce对收集到的参数,进行reduce操作,比如加和,平均,等等。

举例用mapreduce做数据并行计算,每个样本都有x(input)和y(target),黄色为x,绿色为y, 将数据哦平分到m个work节点,每个节点有三个样本。
n个样本得到n个向量(g_i ~ g_n),用一个sum的reduce函数,reduce操作之后server得到了g,就是在w_t这个地方的梯度,然后梯度下降得到新的模型参数w_t+1。

1. server将w_t 广播到work节点上
2.work节点用自己本地的数据和w_t计算本地的梯度,g_i
3. work把他们的梯度传到server上去,server做reduce操作(比如对g_i向量求和),得到梯度g.
4. server做一次梯度下降,对模型参数进行更新,得到下一个模型参数w_t+1.
这样就完成了一次MapReduce, 然后系统不断重复这个过程,直到算法收敛。


做并行计算通常会算加速比。一个节点的运行时间,除以m个节点的运行时间。

通信代价主要有两方面,通信复杂度(正比与参数数量和节点数量)和网络延迟。
通信所需时间就是,通信复杂度/网络带宽 + 网络延迟,这公式并不是很准确但还是比较常用。
通信矩阵向量越大,通信复杂度就越高,时间越慢,说明尽量减少通信内容,两个byte标识一个实数就不要用8个byte.
网络延迟跟传多少参数没有关系,传一个矩阵和传一个bit延迟几乎一样,每次通信都会造成延迟,应该减少算法通信次数或减小网络延迟。

还有一部分时间开销是由同步造成的,因为要等最慢的work, MapReduce本身就是同步的

节点越多,出现一个节点挂掉的概率就越大,straggler造成的影响越严重,

算法运行时间主要由三个部分组成:
1.work上的计算时间。
2.broadcast和reduce都需要通信,通信时间=通信复杂度/网络带宽 + 网络延迟。
3.同步,要等最慢的work完成工作才能开始下一步,如果由节点异常变的很慢,整个系统效率大打折扣。
如果只有计算则加速比为m,但因为通信和同步,导致加速比总时小于m。
















 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











