







论文《Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks》
论文链接:Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks
这篇是IJCAI 2018的关于模型压缩加速的文章,思想简洁有效,主要是和Hard Filter Pruning(HFP)做对比。
背景理解:
首先了解一下比较常见的剪枝方式Hard Filter Pruning(HFP),剪枝的话一般是按照某些指标对卷积核进行排序,然后剪掉不符合指标的卷积核,然后做fine tune,HFP指的是硬裁剪,也就是说fine tune的时候网络中不包含被剪掉的卷积核。
文章灵感:
Soft Filter Pruning(SFP),也就是软裁剪,其和HFP最大的不同就是剪掉的卷积核仍然会参与网络的训练,并进行迭代更新参数,SFP在每个epoch结束后会进行剪枝,剪枝后再训练一个epoch,然后继续剪枝,循环迭代。如下图为SFP和HFP的对比图。
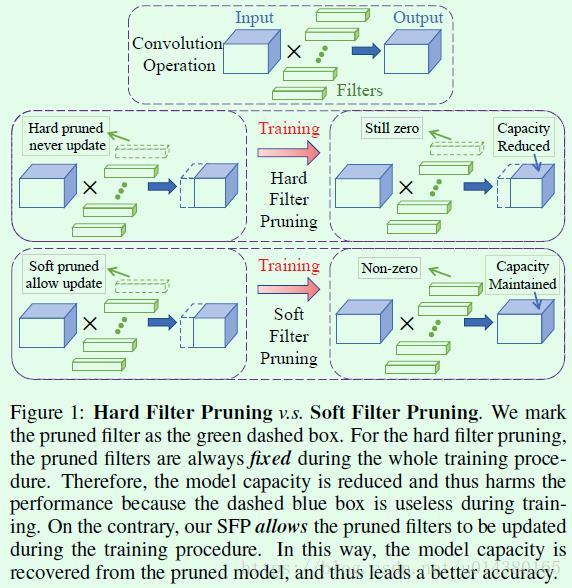
基于此,我们也就比较好的理解文章提出的两个创新点了:
1. Larger model capacity. 相比HFP直接裁剪掉网络的filter,SFP中被裁剪掉的filter仍然参与下次迭代参数更新,这样就保留了原来网络的表达能力,且更好收敛
2. Less dependence on the pretrained model. 采用这种边剪枝边重训的方法,可以从网络的训练开始就进行剪枝,不需要先训练好一个高精度网络模型再剪枝,节省了很多时间,也不完全依赖预训练模型,可以说是一种聪明的剪枝方法。
算法整体流程:

SFP算法示意图如Algorithm 1所示。
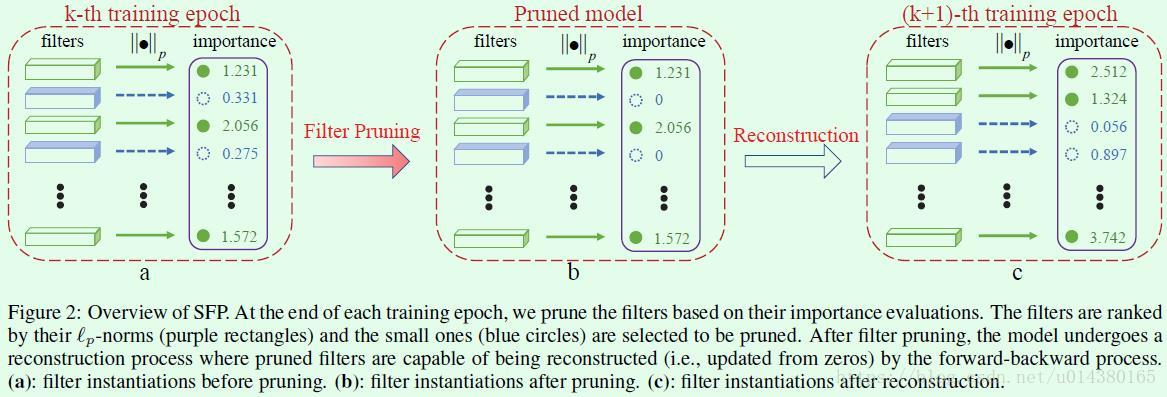
总体而言包含两个循环结构,第一个循环是epoch,其实就是常规的训练过程,每次训完一个epoch就要开始执行剪枝操作。第二个循环是遍历网络的每一层,计算每一层的每个卷积核的L2-norm(L2范数),剪枝概率Pi和第i层的卷积核数量Ni+1相乘表示一个网络层中被剪枝的卷积核数量,将卷积核的L2范数最低的Ni+1*Pi个卷积核剪枝,剪枝是通过将该卷积核的值置为0来实现,从而完成第i层卷积核的剪枝操作。这样随着epoch的迭代,最终得到的模型会包含一些值为0的卷积核,这些卷积核就可以直接去掉从而得到最终的模型。
Lp-norm(Lp范数)的式子如公式2所示,实际中用的是L2-norm,也就是p等于2。
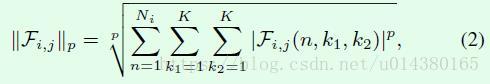
igure2是Soft Filter Pruning(SFP)的示意图。(a)表示剪枝之前的某个网络层的卷积核情况和对应的L2范数,L2范数比较低的用紫色表示。(b)表示对L2范数比较低的一些卷积核执行剪枝操作,也就是将卷积核的值置为0。(c)表示基于剪枝后的网络执行下一个epoch的迭代更新,和Hard Filter Pruning不同的是这里依然会对前面置零的卷积核执行更新操作,也就是参与此次迭代更新的卷积核数量和上一个epoch一模一样,只不过两次迭代前数值为0的卷积核不完全相同而已。
至于计算量的减少计算方式可以直接看论文了
可改进点:
整体来说,这篇文章偏简单基础,很多入门剪枝的童鞋可以看看,然后这其中有很多可以改进的点,接下来会进行描述。
- 这篇文章采用的是一整个网络的每个层都用相同的剪枝概率,但其实不同层用不同剪枝概率的做法在剪枝中还是比较常见的,而且每一层卷积分布不同,所以这块是可以做进一步探索的。此外,剪枝率的选择也是一个可探索的点。
- 对于按照某些指标对卷积核进行排序剪枝,这些指标也可以进行探索。
- 迭代次数的不同会影响网络的性能,这一块也是值得去探索的。
参考链接:
https://blog.csdn.net/m_buddy/article/details/85346684
https://blog.csdn.net/u014380165/article/details/81107032















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









