







1.用 lxml 库解析网页节点
通过 urllib 库可以模拟请求,得到网页的内容,但是在大多数情况下我们并不需要整 个网页,而只需要网页中某部分的信息。可以利用解析库 lxml 迅速、灵活地处理 HTML 或 XML,提取需要的信息。另外,该库支持 XPath 的解析方式,效率也非常高。
1.1安装 lxml
如果是本地安装的Python是最新版本的我们使用1方法直接安装;
如果和我一样使用的是Python3.6或者其他低版本的Python我们选择2离线安装 lxml
- window电脑点击win键+R,输入:cmd
pip install lxml -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2.离线下载安装
离线下载lxml传送门https://mirrors.aliyun.com/pypi/simple/lxml/
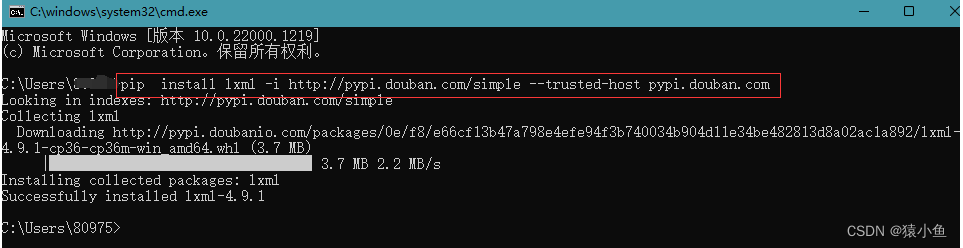
说明:[lxml‑4.6.2‑cp36‑cp36m‑win_amd64.whl](javascript:😉 #cp36 代表Python版本3.6
pip install C:\Users\Administrator\Desktop\lxml-4.6.2-cp36-cp36m-win_amd64.whl
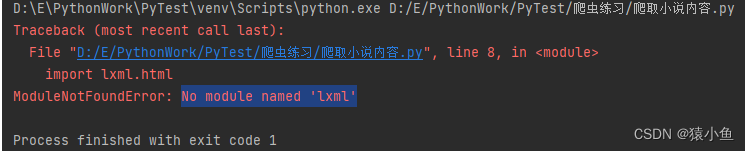
说明:使用的是低版本的Python,直接安装时可以安装最新版本的lxml的但使用的时候会出现如下错误,所以我们要使用对应Python版本的lxml库
1.2 XPath 语法速成
XPath(XML Path Language,XML 路径语言),用于在 XML 文档中查找信息。它既适 用于 XML 文档的搜索,又适用于 HTML。其核心是按照规则,通过编写路径选择表达式 来筛选节点。
下面简单介绍 XPath 的语法,如果想了解更多的规则 w3school
- 绝对路径和相对路
绝对路径:用/表示从根节点开始选取。
相对路径:用//表示选择任意位置的节点,而不考虑它们的位置。
另外,可以使用*(通配符)来表示未知的元素。除此之外,还有两个选取节点的标 记(.和…),前者用于选取当前节点,后者用于选取当前节点的父节点。
- 选择分支定位
比如存在多个元素,想唯一定位,可以使用[]来选择分支,分支的下标从 1 开始,相关的规则如下
/tr/td[1]:取第一个td
/tr/td[last()]:取最后一个td
/tr/td[last()-1]:取倒数第二个td
/tr/td[position()<3]:取第一个和第二个td
/tr/td[@class]:选取拥有class属性的td
/tr/td[@class='xxx']:选取拥有class属性为xxx的td
/tr/td[count>10]:选取 price 元素的值大于10的td
- 选择属性
还可以通过多个属性定位,比如可以这样写
/tr/td[@class='xxx'][@value='yyy']或者/tr/td[@class='xxx' and @value='yyy']
- 常用函数
除了 last()、position(),还有以下常用函数
contains(string1,string2):如果前后匹配则返回 True;否则返回 False。
text():获取元素的文本内容。
starts-with():从起始位置匹配字符串。
- 轴
当上面的操作都不能定位时,可以考虑根据元素的父节点或兄弟节点来定位,这时就 会用到 XPath 轴,利用轴可定位某个相对于当前节点的节点集,语法为轴名称::标签名,可 选参数如下表
可选参数表
| 轴 名 称 | 作 用 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等) |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)及当前节点本身 |
| attribute | 选取当前节点的所有属性 |
| child | 选取当前节点的所有子元素 |
| descendant | 选取当前节点的所有后代元素(子、孙等) |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)及当前节点本身 |
| following | 选取文档中当前节点的结束标签之后的所有节点 |
| following-sibling | 选取当前节点之后的所有兄弟节点 |
| namespace | 选取当前节点的所有命名空间节点 |
| parent | 选取当前节点的父节点 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点 |
| preceding-sibling | 选取当前节点之前的所有同级节点 |
| self | 选取当前节 |
















 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











