







主要内容:
- Overfitting(问题)
- 判断和防止overfitting 的方式
——————————————————————————————————
过度拟合的模型往往不能进行一般化推广(generalization)
拟合问题需要在两个方面进行权衡
需要注意的是 如果用来训练的数据和测试的数据是同样的,那么这样的检验是没有意义的,就像 "Table Model" 一样
一般我们会将数据集分为training/testing(holdout) 两个部分
 注: 在python中可以这样做Code
注: 在python中可以这样做Codefrom sklearn.cross_validation import train_test_split Xtrain, Xtest, ytrain, ytest = train_test_split(X, y)
识别 overfitting 的方式
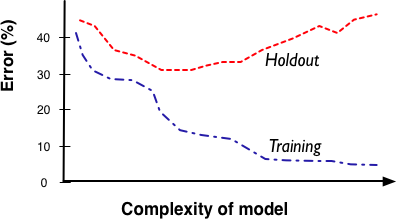
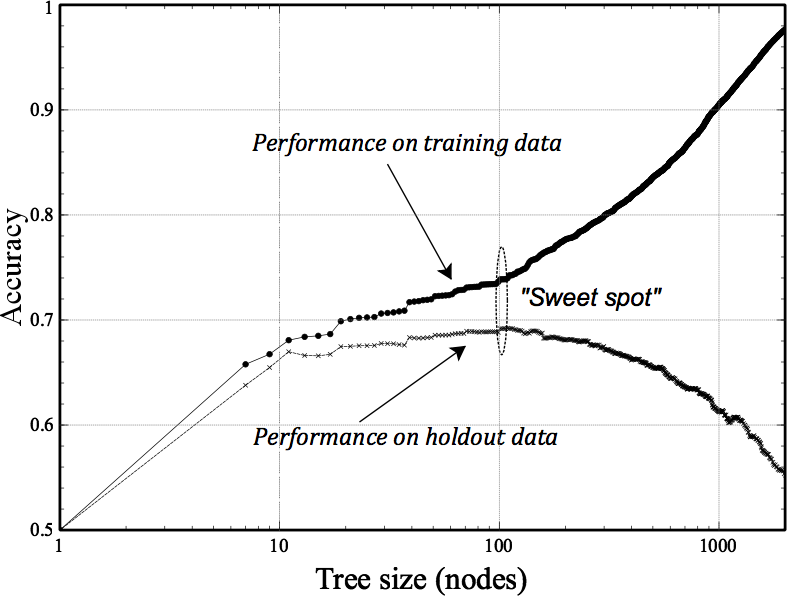
- Fitting graph(模型误差与模型复杂度的图像)
基于两个模型类型讨论 Overfitting
- Tree induction problem
- 模型的复杂程度与节点的数量相关
- Numeric model (Mathematical Functions)
- 变量的数量与模型的复杂度相关
- 直观的例子:
二维情况下,两个点可以用一条直线拟合
三维情况下,三个点可以用一个平面拟合
……
- 随着维度的增加,我们可以拟合任意数量的点(模型的参数就会变得很多)
此时很容易过拟合(我们需缩减特征(attributes)数量来防止过拟合)
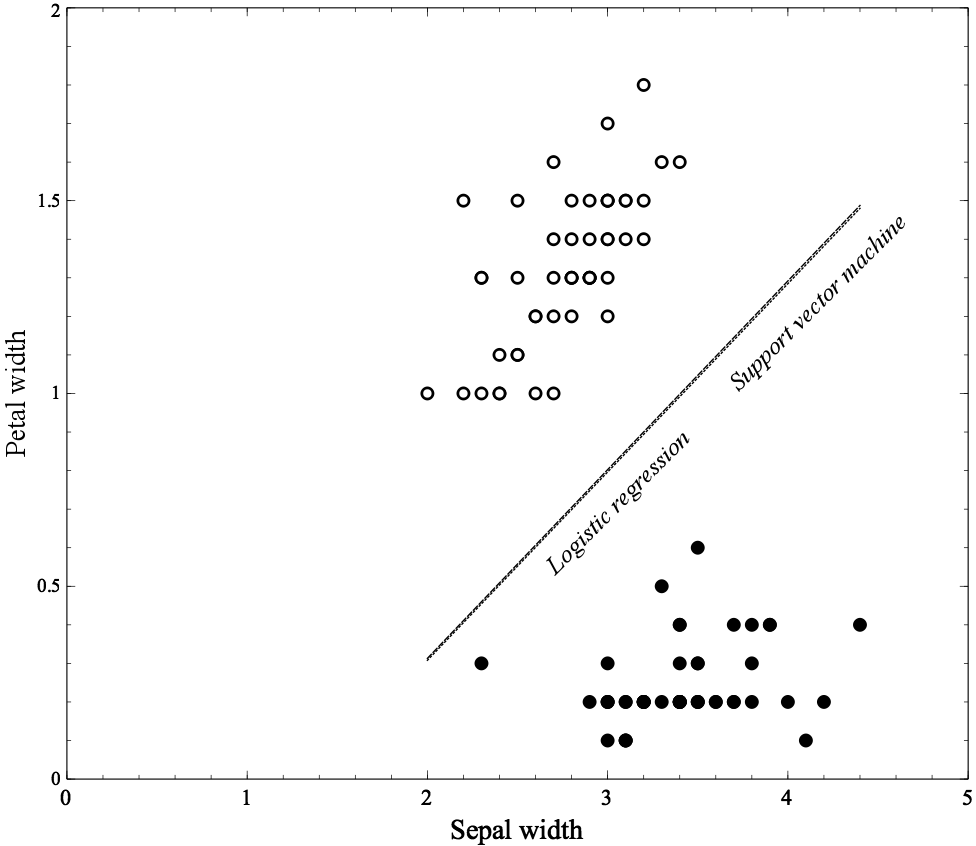
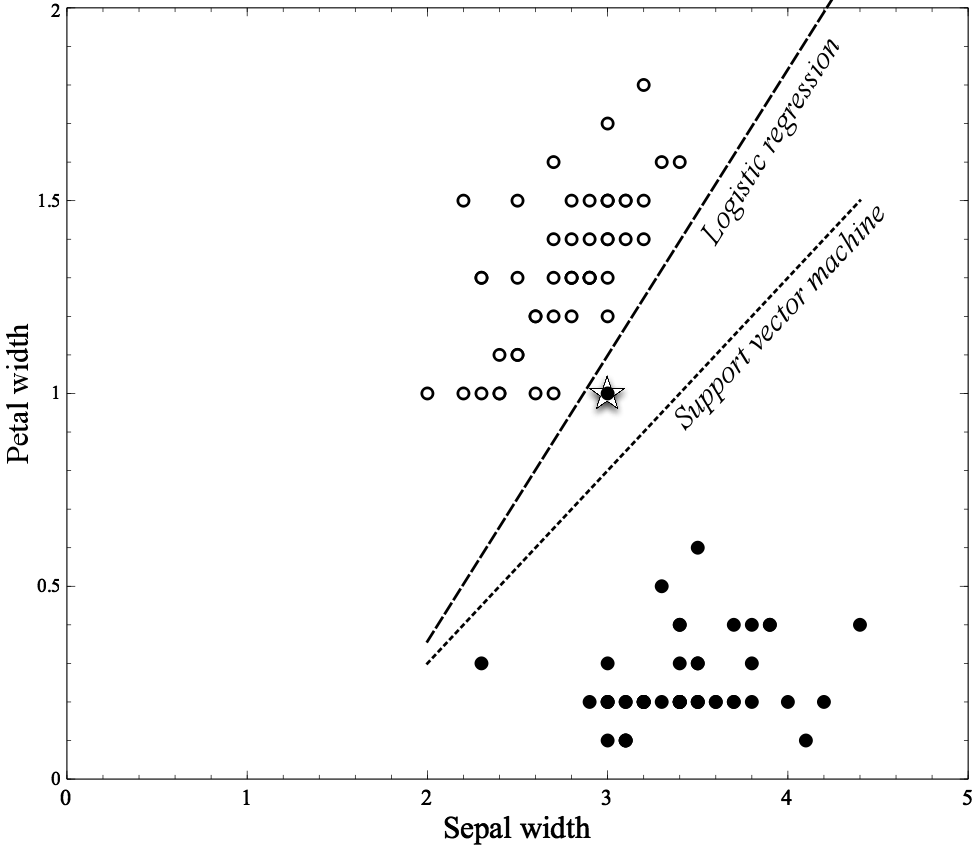
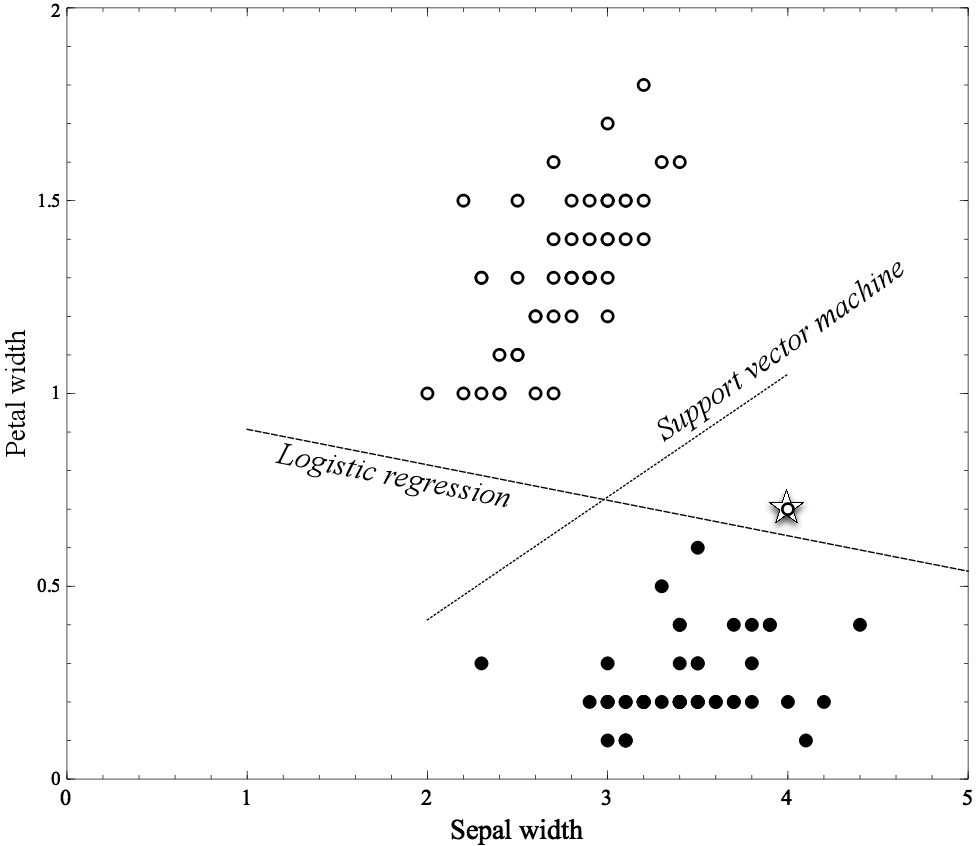
SVM 与 Logistics Regression 的比较
- 模型敏感性
SVM对个别样本更不敏感(相对逻辑斯蒂模型)
过度拟合的劣势
- 一个完全记忆式的模型是无用的,它不能被一般化
- 当一个模型过度复杂时,它很容易去利用那些看似正确实则无用的(spurious)关系
Overfitting 识别的进一步分析
- 前面提及的fitting graph 是利用Holdout-Evaluation 的方式来判断,这个只是的单次的检验(single test)
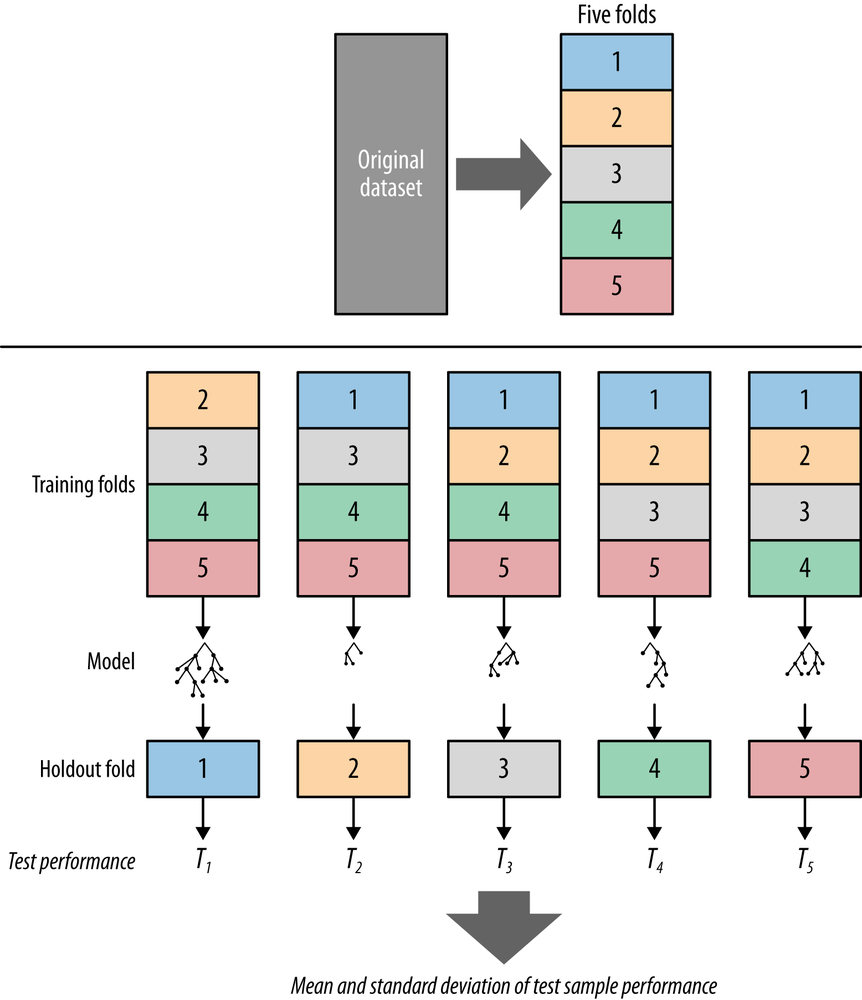
- 在此基础上,我们得到 Cross-Validation 用来防止过度拟合
- Cross-Validation 本质上是应用不同split的方式,多次进行Holdout-Evaluation
- Cross-Validation 原理图
Further idea : Buliding a modeling "labortory"
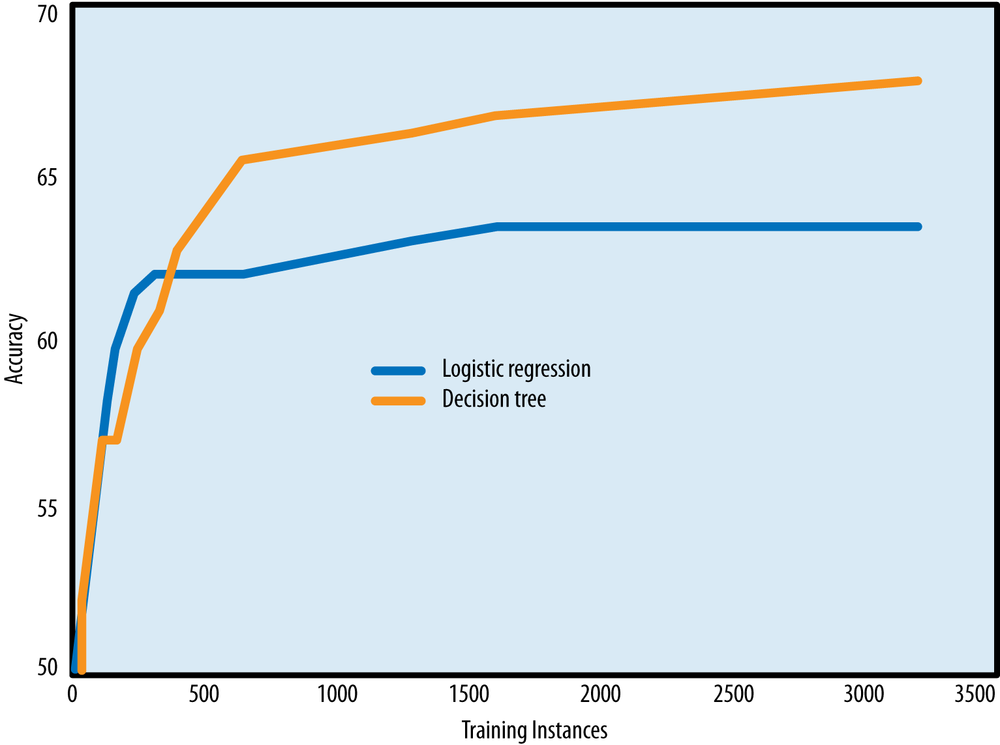
Learning curves (学习曲线)
- 模型一般化表现和训练集数量的图像
Logistics regression 和 decision tree 的学习曲线
- 从图中可以看出,学习曲线初期比较陡,然后,增长速率逐渐放缓,到后期基本平坦了(边际递减)
- 要合理分析当前自己的数据数量对于使用的模型而言处于哪个水平,依据学习曲线来做出是否继续在数据量上做投资的决策
避免 Tree induction 过拟合的方式
- 在树过于大之前便停止生长
- 每个叶中至少需要多少个数据(threshold)
- 如何判断这个阈值(threshold)是重点【可以考虑用假设检验/P-值】
- 等树生长到足够大之后进行修剪
- 修剪枝叶,直到任何改动都会降低正确率
Nest cross-Validation
- 对训练数据集进行再划分,以此来优化模型(例如选择参数,选择特征数量(features))
- Cull the feature set (example: SFS【sequence forward selection】)
 Regularization
Regularization- 重点是构造一个带惩罚(penalty)的目标函数,并最优化
-
- 扩展:
- 将二范数惩罚函数与最小二乘法结合在一起就可以得到岭回归
- 将一范数惩罚函数与最小二乘法结合在一起就可以得到lasso方法
The problem of multiple comparison is the underlying reason for overfittingSidebar: Beware of “multiple comparisons”
Consider the following scenario. You run an investment firm. Five years ago, you wanted to have some marketable small-cap mutual fund products to sell, but your analysts had been awful at picking small-cap stocks. So you undertook the following procedure. You started 1,000 different mutual funds, each including a small set of stocks randomly chosen from those that make up the Russell 2000 index (the main index for small-cap stocks). Your firm invested in all 1,000 of these funds, but told no one about them. Now, five years later, you look at their performance. Since they have different stocks in them, they will have had different returns. Some will be about the same as the index, some will be worse, and some will be better. The best one might be a lot better. Now, you liquidate all the funds but the best few, and you present these to the public. You can “honestly” claim that their 5-year return is substantially better than the return of the Russell 2000 index.
So, what’s the problem? The problem is that you randomly chose the stocks! You have no idea whether the stocks in these “best” funds performed better because they indeed are fundamentally better, or because you cherry-picked the best from a large set that simply varied in performance. If you flip 1,000 fair coins many times each, one of them will have come up heads much more than 50% of the time. However, choosing that coin as the “best” of the coins for later flipping obviously is silly. These are instances of “the problem of multiple comparisons,” a very important statistical phenomenon that business analysts and data scientists should always keep in mind. Beware whenever someone does many tests and then picks the results that look good. Statistics books will warn against running multiple statistical hypothesis tests, and then looking at the ones that give “significant” results. These usually violate the assumptions behind the statistical tests, and the actual significance of the results is dubious.


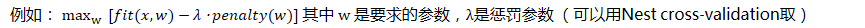















 2243
2243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









