







- intra-temporal attention 在本文中的应用
(1)在input sequence上的应用
这个C t e ^e_t te对应文章中Figure1中的C1(在下文中标出)

(2)在output sequence上的应用
这里的C t d ^d_t td对应paper中Figure1中的C2(在下文中标出)

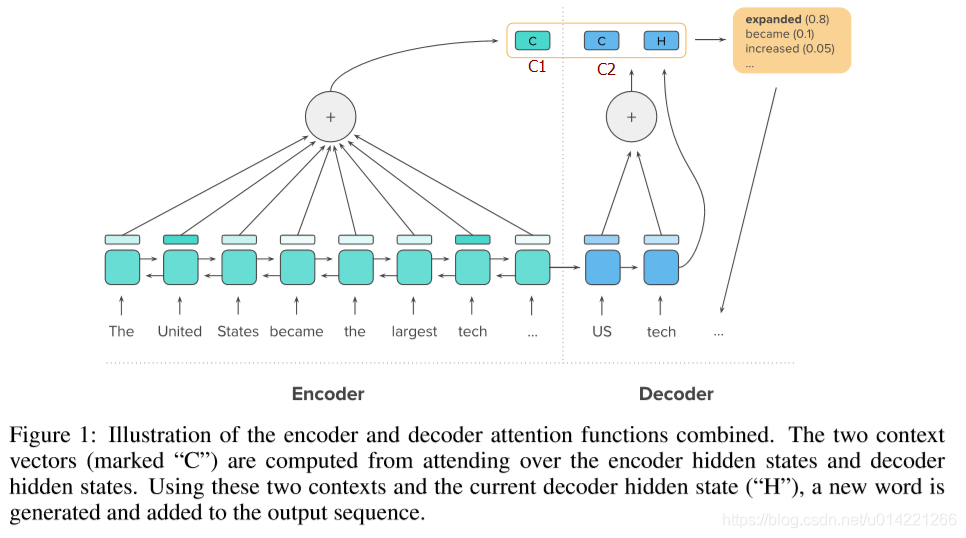
2. 生成还是copy
pointer network和copy 机制的目的是为了解决OOV词,首先计算出一个概率值
u
t
u_t
ut用来判断是是生成模式还是copy模式
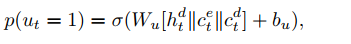
那么
p
(
u
t
=
0
)
p(u_t = 0)
p(ut=0) = 1-
p
(
u
t
=
1
)
p(u_t=1)
p(ut=1)
u
t
u_t
ut = 0时是生成模式,那么固定词汇集中词的概率分布是:
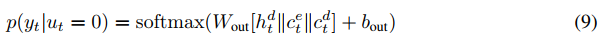
u
t
u_t
ut = 1时是copy模式,input sequence 中每个token的概率分布,其中
a
t
i
e
a^e_{ti}
atie在encode阶段已计算出。
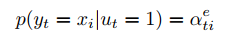
那么最终的概率分布计算公式如下:
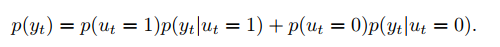
3. hybrid learning objective
maximum-likelihood training objective:
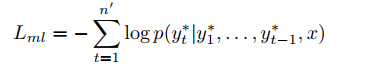
因为maximum-likelihood objective 只能计算唯一的一个序列,并且文本摘要的的评价标准是ROUGE,为了能将评价结果用于训练,并且ROUGE的公式是不可微的,所以提出了用RL中的Policy learning进行训练。本文中用了self-critical policy gradient training algorithm算法。此算法会在下篇博客中详细解释:
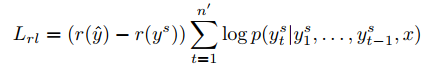
强化学习只是优化了ROUGE这样的评测标准,但不能保证输出的质量和可读性。于是结合了maximum-likelihood。两者结合作为训练目标。
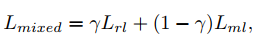
非常好的文章解释:
https://blog.csdn.net/youngair/article/details/78302794














 7107
7107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









