







描述:采取了scrapy框架对途牛网旅游数据进行了爬取,刚开始练手,所以只爬了四个字段用作测试,分别是景点名称、景点位置、景点开放时间、景点描述,爬取结果存的是json格式。
部分数据:

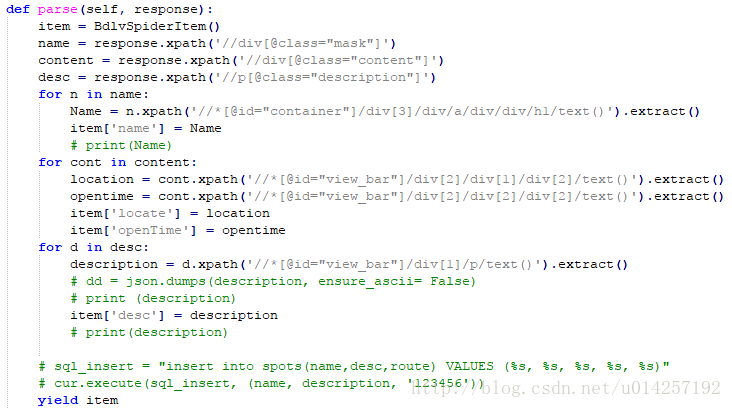
部分代码:
遇到的问题:start_urls是不能动态添加URL的,这个还需要研究,这里只是简单把所有待爬取的网址全扔进了start_urls里面,这是可行的,但是对网址的预处理就很耗时间了。然后是对汉字编码的处理,在scrapy中一开始传到json中的数据总是/uxxx类型的,这需要在pipeline.py、setting.py中都进行修改,具体修改如下:
在pipelines.py中,修改代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1594
1594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









