







目录
一、前言
对于跨语言理解及与稀缺语言相关的迁移学习而言,一个评测数据集不可或缺。2018年,Facebook的提出了XNLI(Cross-Lingual Natural Language Inference)这个数据集,旨在提供一个统一的评测数据集以方便相关研究。NLI,也就是文本蕴涵,是自然语言理解(NLU)中的一项重要的基准任务,该任务是为了判断两句话之间的关系是否是蕴含(entailment)、矛盾(contradiction)和中立(neutral)三种中的一种。在论文中,Facebook还提出包括多个机器翻译任务、词袋及LSTM编码器在内的baseline。关于XNLI更多内容可参考Facebook论文:XNLI: Evaluating Cross-lingual Sentence Representations。
二、XNLI介绍
- 源数据集获取:
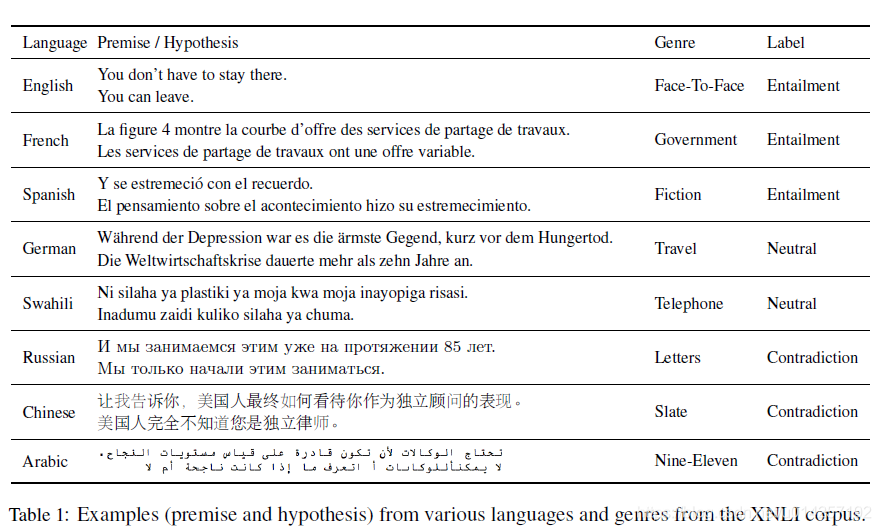
XNLI支持15种语言,数据集包含10个领域,分别是:Face-To-Face, Telephone, Government, 9/11, Letters, Oxford University Press (OUP), Slate, Verbatim, Government and fiction. 前九项来自开放美国国家语料库,fiction来自英文小说《Captain Blood》。每个领域包含750条样本,10个领域共计7500条人工标注的英文测试样本,组成了112500对英文--其他语种的标注对。每条数据样本,由两个句子组成,分别是前提和假设,前提和假设之间的关系,有entailment(蕴含)、contradiction(矛盾)、neutral(中立)三类,在标注过程中,XNLI的开发者使用了精细的投票规则,最大程度保证标注结果是无偏的。
- 目标数据集获取:
目标数据集是通过将英文数据集翻译成对应语种而得到的。这就产生了一个问题,即在将英文句子翻译成目标语种的后,句子间的对应关系是否会改变。通过实验,总体上两类语种之间的语义关系是一致的。一些XNLI的数据集样本见图一:
三、评测任务介绍
1、基于翻译的方法
Baseline-1:TRANSLATE TRAIN,将英文数据集翻译成目标语言,在翻译后的数据集的上训练模型;
Baseline-2:TRANSLATE TEST,在测试阶段,将目标语言翻译成为训练阶段所使用的语文,并在训练后的模型上进行测试;
2、基于跨语言表示的编码器
第一类评测任务和基于翻译,第二类方法基于与语言无关的统一Embedding。基于这种思想,作者提出了两类跨语言的句子编码器:
Baseline-3:X-CBOW,预训练的统一多语言句子级别的词向量,基于CBOW方式训练的词向量的平均得到;
Baseline-4: X-BiLSTM,多语言语料上训练的BiLSTM编码器;对于该Baseline,作者提出了两种方法来提取特征,对每个隐单元,使用初始和最终的隐状态作为表示,或者使用最大的隐状态作为特征,不同方法的Baseline分别记作X-BiLSTM-last和X-BiLSTM-max;
在这几个Baseline中,涉及到其他的一些重要概念,介绍如下:
- Multilingual Word Embedding
该文的主要是在句子层面做一些跨语言的研究,以往的跨语言工作大多集中在词级别,词级别的Embedding对齐方法,基本思想是基于n对多语言映射字典Embedding表示,学习到两种语言之间的映射关系,如下:
其中,d是Embedding的维度,X,Y分别是维度为(d,n)的矩阵。这个公式可以理解为,通过最小化映射字典Embedding之间的距离,使得在新的Embedding空间中,具有相同意义的词向量之间的距离更近。通过对X和Y作SVD分解,可以得到U和V,进一步可以得到最小化Embedding距离的参数矩阵W。
关于跨语言的Embedding研究,可以去参考Mikel Artetxe(主页:http://www.mikelartetxe.com/)这位大神的文章。该大神过去几年,从监督到无监督,研究Cross-Embedding的工作,连续几年发了多篇顶会,并且开源了相关代码(https://github.com/artetxem/vecmap),复用简单。
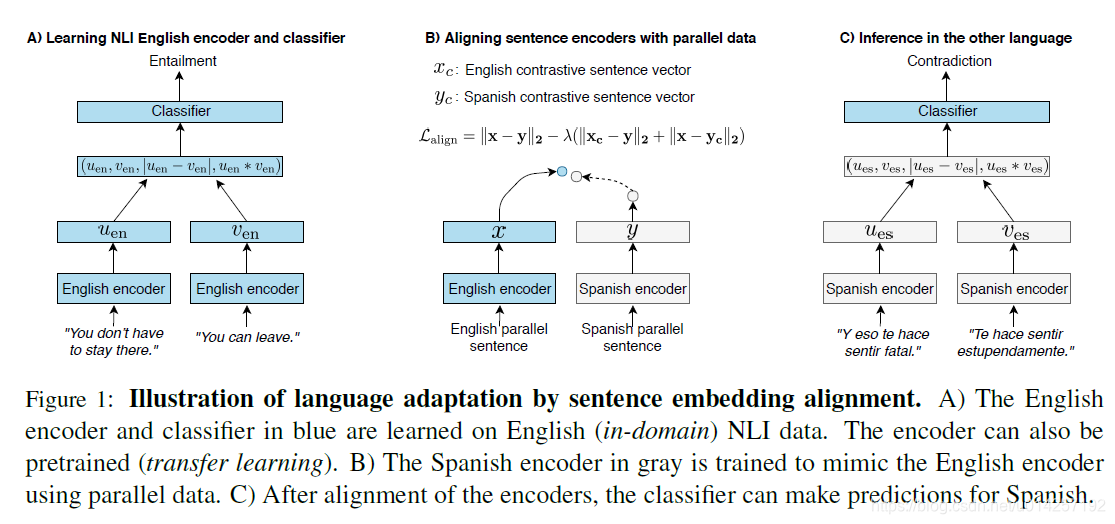
- Aligning Sentence Embeddings
句子Embedding对齐。作者在英文上预训练好一个编码器,然后最小化以下损失函数,来得到目标语言上的编码器:
x,y分别代表两类语言的句子Embedding,第一项使用L2范数计算相似度,第二项我理解的是加入正则,使得相似度计算结果更加鲁棒。和
分别表示负采样,
控制正则的系数。具体的对齐细节见下图:
四、实验
在各个baseline上,实验结果为:
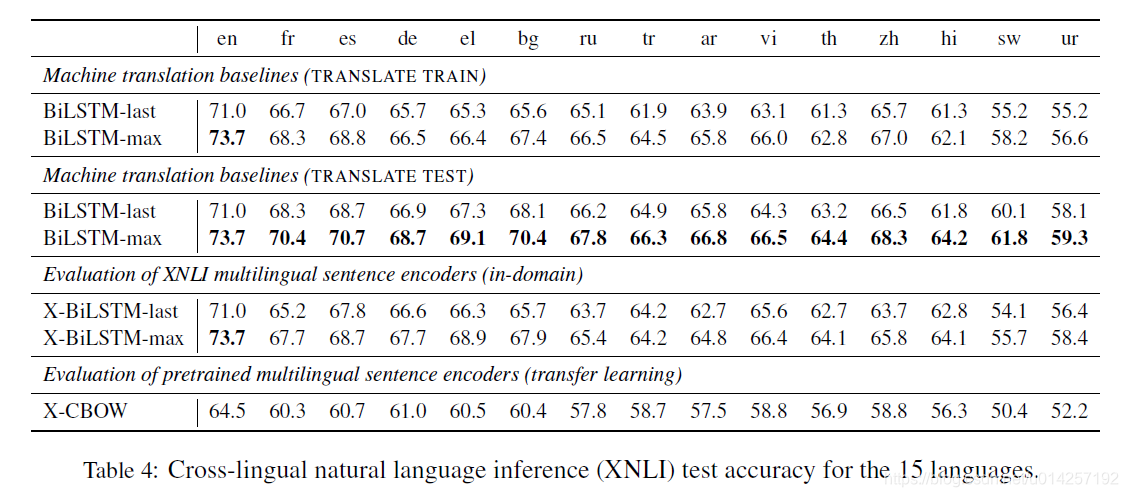
从实验结果,主要可以得出以下几点结论:
- 在基于翻译的方法中,TRANSLATE TEST的方式优于基于TRANSLATE TRAIN的方式,即将目标测试集翻译成为训练模型所采用的语言的效果,优于将训练集翻译成为目标语言进行训练再评测;
- 在各个Baseline上,BiLSTM编码器使用最大的隐状态而不是最后的隐状态作为特征,效果更好;
- 基于翻译的方法比基于跨语言表示的方法,在效果上要更好,但是在一些跨语言任务中,实时翻译的成本高,基于跨语言表示的方法,提供了一些替代的解决方案。
XNLI的介绍就先到这里啦,有什么疑问欢迎关注公众号联系,一起讨论,共同进步~


















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









