







文章目录
survival data
在本课中,我们将讨论生存数据(survival data)。为了能够建模生存,我们需要将数据处理为需要的格式。主要挑战是传感器数据,这是我们将要研究的一种特定形式的缺失数据(missing data)。
在处理医疗数据时,缺失的数据是一个常见且重要的问题。可以表现一个或多个变量中缺少数据。我们暂时还不讨论结果变量的缺失。

我们有一些患者的血压测量值(BP)缺失。这里我们用N/A表示缺失。
让我们来看看机器学习pipeline,然后我们将利用这些数据建立预测模型。因此,我们在机器学习管道中可能采取的第一步是创建train、testc数据集。

注意到这两个数据集都包含血压测量缺失的患者。在这个阶段,标准的下一步就是排除缺少数据的个人记录。因此,我们会说“我们不会使用患者10的数据,在测试集上也不会使用患者12的数据。”
但是,这种方法存在一个问题,以及它如何导致偏差模型。因此,在这个阶段,我们删除了missing data,现在我们继续构建分类器,试图根据年龄和血压预测死亡结果

由于我们在上一课中使用了随机森林分类器,因此我们将训练一个随机森林分类器并在测试集上对其进行评估。因此,我们看到随机森林分类器首先获得0.87的训练精度和0.84的测试精度。训练精度非常高,测试精度也相对较高(上图)。

现在,一个新的测试数据集到来了(上图),关于这个测试集,需要了解的是,这个测试集没有丢失数据。让我们假设它是通过与我们之前的数据集相同的研究设计获得的,但这一个我们没有缺失数据。现在我们在这个新的测试集上运行我们的随机森林模型。只有0.61的低精度。那么,发生了什么?
different distributions
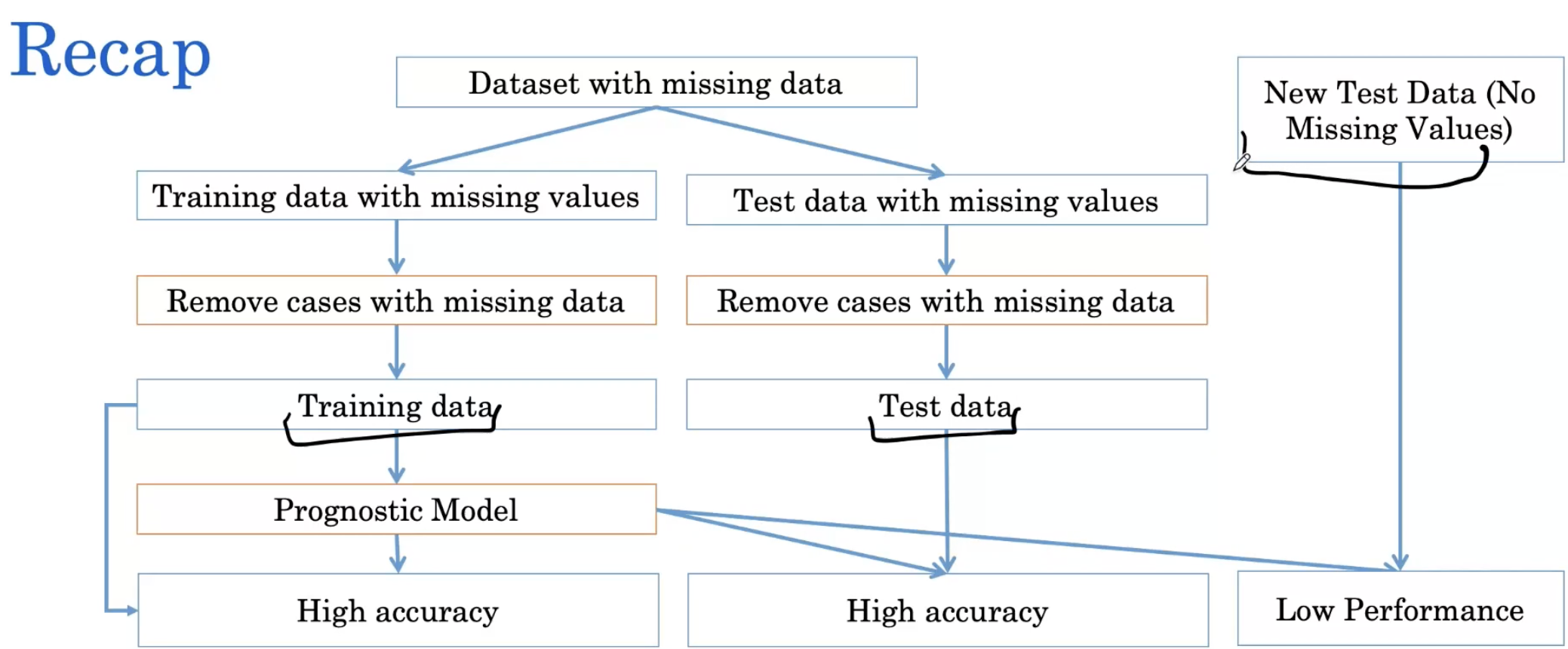
我们思考一下上一节中的pipeline做了什么。我们有一个缺失数据的数据集,我们创建了一个train-test split,我们的train数据有缺失值,test数据也有缺失值。所以我们只是从两者中删除了缺失数据的案例,这样我们就有了删除案例的train和test数据。
我们建立了一个预测模型,用年龄和血压预测死亡。我们在train数据中获得了很高的准确性。test数据也有很高的精度。在我们 new test数据集上没有缺失值,我们只是直接运行模型,它的性能很低。
那么为什么会发生这种情况呢?所以我们知道,我们可以看到训练数据和测试数据之间的差异,甚至旧测试数据和新测试数据之间存在差异的一个原因是分布不同。

我们可以查看输入变量的分布。在这里,我们将关注年龄优先。但是假设我们有很多变量,我们可以用其他多个变量重复这个分析。在左边,我们有我们的旧测试集,或者我们的原始测试集.这两张图之间的主要区别在于40岁以下的人群。与我们的新测试集相比,我们的旧测试集中年龄小于40岁的患者数量要少得多。

所以现在我们可以问一个问题,我们是否可能在40岁以下的患者身上表现很差,但我们没有看到?因为我们这里没有足够的例子,而我们这里有很多例子。让我们看看当我们在这条分隔线的左边和右边求值时会发生什么。
当我们观察年轻患者时,我们得到的准确度只有55%。新旧数据的结果一样。不同的是,左边40岁以下患者很少,右边40岁以下的患者很多。当所有患者的准确度加起来求平均,新数据的总体精确度就会低于旧数据
缺失数据案例
从上面可以看到,新旧数据的准确度不一样的原因就是数据分布不同,对于40岁以下的患者,我们表现不佳。什么原因造成的呢?有没有可能,当我们放弃缺失病例时,我们放弃了许多年轻患者?
为了验证这一点,我们可以绘制出血压测量不完整的病例踢掉前后测试集的分布图。
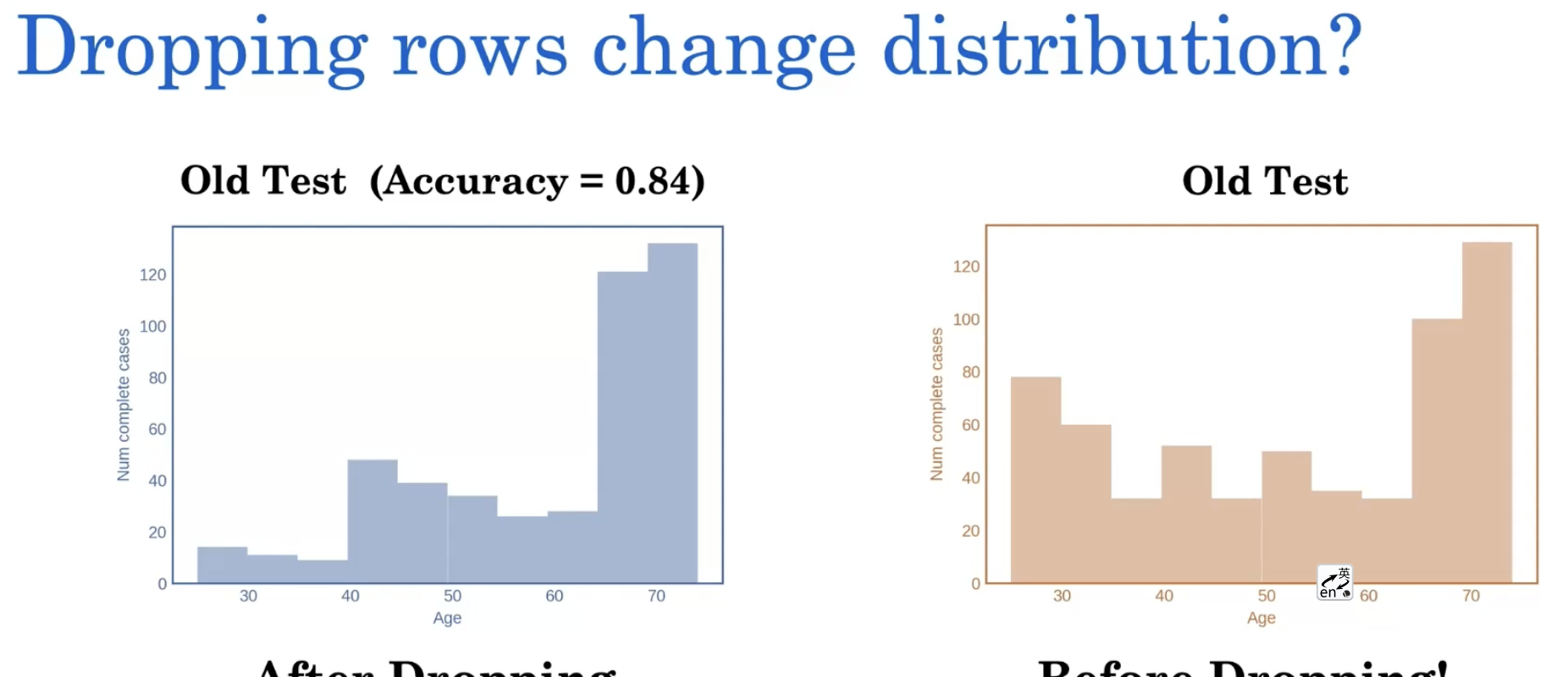
我们可以看到原本数据集有很多年轻患者,在我们减少了血压测量缺失的病例后,我们消除了很多年轻患者。为什么会发生这种情况?这种情况可能发生的一个原因是,在诊所里,医生可能不会定期记录年轻患者的血压,但可能是老年患者日常护理的一部分。有很多这样的模式会导致数据的系统性丢失,比如当人们年轻或真正年老时,丢失数据的频率可能会更高,我们需要警惕这些模式,以便建立不带偏见的模型。在以后的课程中,我们将学习缺失数据机制,以及如何以更系统的方式思考缺失数据。
为什么数据会缺失?缺失有几种类型

让我们谈谈为什么数据会丢失。现在,为了确定完整的案例分析是否会导致偏差,了解数据缺失的原因是有帮助的。大致有三类缺失数据:完全随机缺失、随机缺失和非随机缺失。
Missing Completely at Random
什么是完全随机缺失?想象一下,一位医生正在决定是否记录血压测量值,他们决定的方式是每次患者进来时,他们都掷硬币。如果硬币是正面的,他们会记录血压。如果硬币是反面的,那么他们就不会记录血压。

现在,有了这个机制,我们可以想一想,对于血压缺失者和血压未缺失者,不同年龄组的频率,我们的图表会是什么?

由于我们没有决定是否通过查看患者的年龄来记录血压测量值,我们预计这两种分布非常相似。因此,假设我们所观察的患者在所有年龄段都是均匀分布的,我们预计对于那些血压没有缺失的患者,我们也会看到类似的均匀分布。当然,这不一定要统一。
请注意,对于完全随机缺失的患者,任何特定患者血压缺失的概率是恒定的。它仅仅是0.5。

这就是完全随机丢失,不依赖于任何事物。对于完全随机缺失的情况,我们之前所做的完整案例分析不会导致偏差模型。所以我们希望,当我们完全丢失随机数据时,我们不会创建偏差模型。但大多数缺失并不是完全随机的。
Missing at Random

什么是随机缺失?上面是我们正在处理的场景。因此,如果患者年龄大于40岁,医生都会测量血压。但是如果患者年龄小于40岁,那么医生会掷硬币。如果硬币掉到头上,他们会记录血压,如果没有,他们不会记录血压。
现在,这可能有几个原因。这可能是因为医生认为老年人应该经常做血压检查,而年轻患者只需要偶尔做。这里需要认识到的重要一点是,我们现在有一个条件,它决定了我们是否在抛硬币,然后决定我们是否在记录血压。

让我们模拟一下。比如说,对于第一个患者,我们可以看到他们的年龄小于40岁,所以我们要投掷硬币。所以让我们假设第一个,硬币翻转是反面的。所以我们不会记录血压。对于第二个患者,年龄大于55岁,所以没有硬币翻转,我们只记录他们的血压。对于第三个患者,他们的年龄小于40岁,所以再次,我们将进行硬币翻转,正面则将记录患者的血压等。
需要认识的最重要的一点是,当患者年龄超过40岁时,我们根本不做掷硬币运动,我们总是记录血压。因此,让我们想想血压缺失患者和血压未缺失患者的年龄频率发生了什么。
血压测量值丢失的概率不是恒定的,对每个人来说都不一样。其中一个简单的例子是,如果年龄小于40岁,我的血压缺失的概率是0.5,年龄大于40岁的患者他们的血压测量缺失的概率为零,因为我们总是记录。

因此,随机缺失是指缺失仅取决于可用信息。这里可用的信息是年龄,年龄完全决定了缺失的概率。
Missing Not at Random

这里是缺失的非随机场景。在不随机缺失的情况下,医生要做的是看看门外是否还有其他病人在等着。如果没有其他患者等待,那么就有足够的时间为每个人记录血压。但是,如果有其他患者在等待,那么就有一个掷硬币,如果翻转到正面,我们会记录血压。如果没有,不要记录血压。
请注意,患者是否在等待并不是传统上作为研究的一部分收集的变量。这在我们最终收到的任何数据中都是无法观察到的。

由于不是随机丢失的,不可观察变量的困难在于我们根本看不到它们。因此,是否还有其他患者在等待并不是我们得到的最终数据集的一部分,因为它根本就没有被记录。我们最终得到的是一组缺失血压值的数据集,其中有一个缺失机制,这里没有记录。
因此,我们不能仅仅通过观察这个数据来判断数据实际上是不是随机缺失的。因为这看起来与我们在数据完全随机丢失的情况下看到的非常相似。因此,我们的数据丢失不是随机的,主要区别在于数据丢失的概率,没有记录血压的概率,不是恒定的。事实上,如果在我们的情况下有其他患者在等待,则血压记录丢失的概率为0.5,而如果没有其他患者在等,则血压测量丢失的概率是0。

但请记住,他们的患者是否等待的是不可用的信息,而这里的缺失取决于不可用信息。这不是随机缺失的。
我们讨论了三种缺失数据类别,完全随机缺失、随机缺失和非随机缺失。然而,不幸的是,我们通常无法确定数据是否真的是随机缺失,或者数据缺失是否取决于未观察到的预测因素。然而,重要的是要了解不同的可能丢失的数据类别,以了解如果我们删除丢失的case,我们将如何导致偏差模型。
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











