










OpenCV编程实现LeCun论文(Gradient-Based Learning Applied to Document Recognition)中的CNN
之前由于工程原因要实现LeCun中的CNN算法,在实现的过程中遇到了一些麻烦,但是对这些问题网上都没有清楚的解答。同时各个博客上所说都是大同小异,所以想写一篇博客对这些问题做一个较清楚全面的解释。另外这些问题都是我在实际编程实现该算法中遇到,并解决的,相信还是比较接地气的。如果在这博客中我说的还是不够清楚或者有不对的地方,望指教。
问题 1:公式的推导
下图就是LeCun论文中的结构图
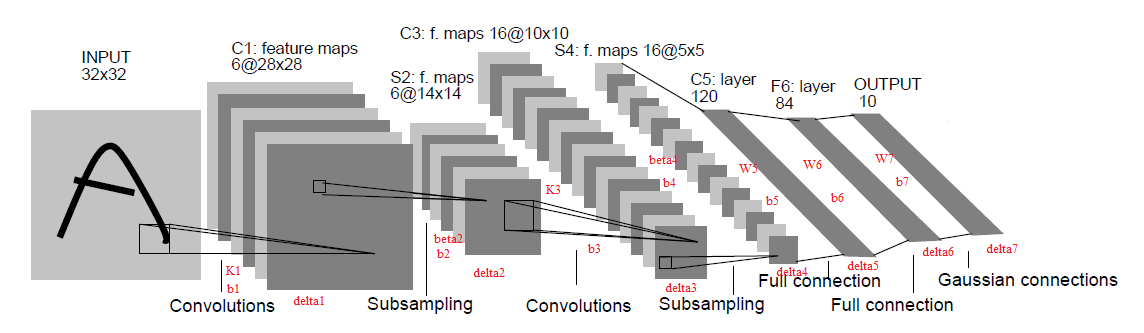
其中b1--b7为各层的偏置,delta1--delta7为各层的灵敏度,K1,K3为卷积核,beta2,beta4为池化层的系数。W5--W7是对应的权值。第五层也是卷积层,由于它也是全连接层,为了编程的方便,这里把所有的卷积核合并在一起得到W5。这里定义X1--X7为各层经过激发函数后的输出。
前向传播
C1:
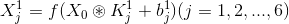
这里的卷积核的大小是5x5,用到6个卷积核,6个偏置,参数数目156个。
S2:
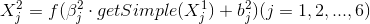
这里的getSimple是取样函数,其操作就是对指定的模板区域进行求和,LeCun的论文中用的是2x2的区域,进行无重叠的求和,且这里的beta是用的确定的值1/4,且不更新。即取平均值。理论上参数的数目是2*6 = 12个,但是由于beta不更新,只更新偏置b,故这里是6个参数。
C3:
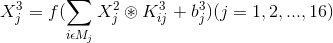
其中Mj为连接方式,见下图:
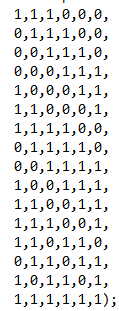
这是在代码中截下的图,在LeCun的论文中也有这个连接方式的说明,其中行表示卷积后的Feature Map,列表示上一层的Feature Map。 1表示连接,0表示不连接。每一列都是10个1,共有60个1,故这里有60个卷积核,同时,生成16个Feature Map,故有16个偏置,故共有60*25+16 = 1516个参数需要训练。
S4:
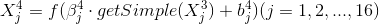
这里和第二层的池化层的运算方式是一样的,也是2x2的不重叠区域求平均,所以beta不用训练,只需要训练偏置,所以理论上参数的数目是2*16 = 32个,但是实际上只需要训练偏置就可以了,实际训练的参数是16个。
C5:
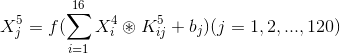
这里的连接方式是全连接,如果用C3中的连接矩阵来表示,就是一个120x16的矩阵,矩阵中的元素全是1,表示全连接。故有120*16 = 1920个卷积核,最后得到120个Feature Map(这里的特征map是当个元素),故有 120个偏置,故共有 1920*25 + 120 = 48120个训练参数。由于这里是全连接也可以将所有的卷积核合并为一个400x120的权值矩阵。将第四层中的输出变成一个列向量。变为如下图所示的公式。
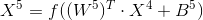
F6:
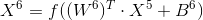
这里的W6是120x84的矩阵,F6有84个神经元,共84个偏置,故该层需要训练的参数数目是120*84+84 = 10164
OUTPUT:
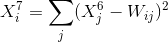
这里是径向基函数的输出方式。这里的W是预先设定好且并不更新。实质上这里的W是10个字符(0-9)的标准形式的列向列表示,由-1和1表示,与标准的字符越接近输出的X7的值越小。注意的是这一层没有权值的调节。
后向传播
后向传播中要确定两个问题,一是传输函数(激发函数)的形式,二是损失函数。这里出于简便原则采用的是均方差函数为损失函数,采用双曲余弦函数为激发函数。函数如下:
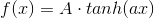
其中A = 1.7159 ,a = 2/3,下图是传输函数和其导数:
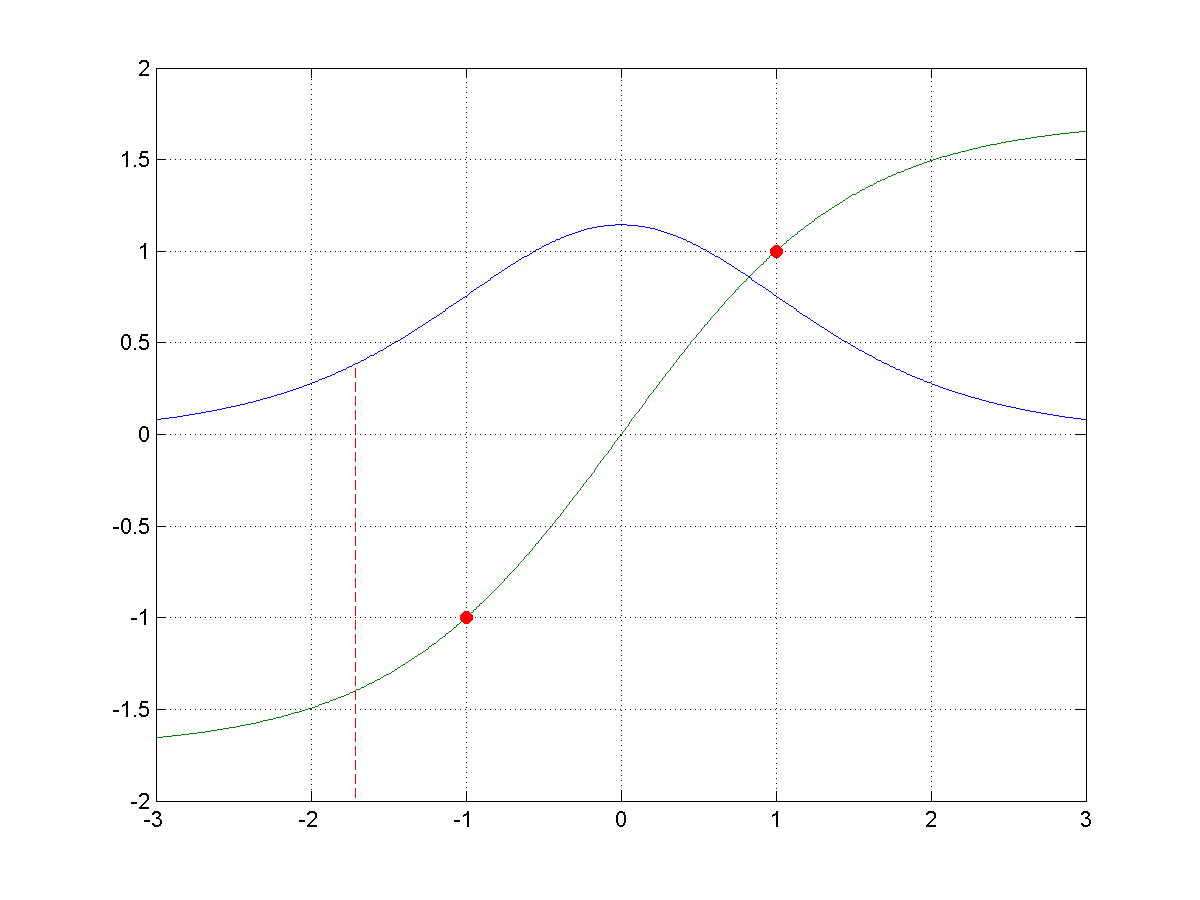
在[-1,1]区间内,导数依然较大,便于调节,使得收敛的速度更快,否则输出若在双曲余玄函数的两边是由于导数值太小,导致灵敏度小,误差反向传播的过程中,逐层损失,导致网络的权值调节速度慢。
引入新的符号: 表示各层中在进过激发函数之前的输出。
表示各层中在进过激发函数之前的输出。
表示各层中在进过激发函数之前的输出。
OUTPUT:
这一层没有权值的调节,所以这均方误差函数并不建立在这一层,而是建立在F6这一层。所以误差的反向传播从第六层开始。
F6:
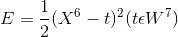
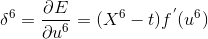
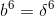
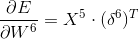
这里的t是目标输出,就是上面说的标准字符,是W7中的一列。注意这里都是矩阵运算。
C5:
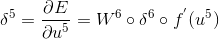
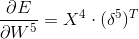
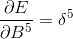
这里的“.”是矩阵运算,而“。”是阵列乘法运算,即相同维数的矩阵对应的元素相乘,得到同样维度的矩阵。
S4:
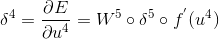
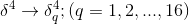
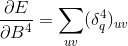
这里得到的灵敏度是列向量,需要转化为S4中Feature Map的大小的矩阵。对偏置的更新,需要一个求和,这里只对S4中的一个Feature Map的大小的灵敏度进行求和,对LeCun的论文中而言,就是对5x5的大小的矩阵进行求和。
C3:
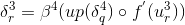
其中up表示按照池化的模板,将第四层的每个灵敏度的值以复制的方式扩展为第三层的灵敏度的值。
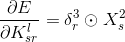
这里的运算 是相关运算,类似于卷积运算,不同的是这种运算不需要将卷积核旋转180度。
是相关运算,类似于卷积运算,不同的是这种运算不需要将卷积核旋转180度。
是相关运算,类似于卷积运算,不同的是这种运算不需要将卷积核旋转180度。
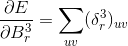
这里对偏置的更新同样是对第三层Feature map大小的矩阵进行求和。
整个求梯度的过程中,这里出现第一个难点:对卷积核求梯度如下图:
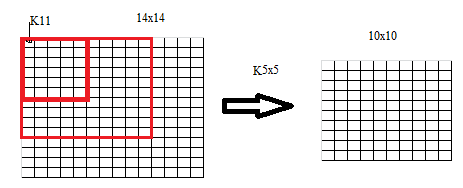
图中14x14的图与5x5的卷积核做卷积,得到10x10的结果,在这个过程中,取卷积核中的K11元素讨论,在该Feature Map中与K11相乘的元素为图中大的红色边框,同时得到结果中的每一值都有K11参与运算,所以10x10 的Feature Map中每一个元素对K11求导的值,就是14x14的Feature Map中大的红色框中对应的元素。所以对10x10的Feature Map中的所有值对K11求导的结果就是,10x10的Feature Map与上一层的大的红色框中的元素做阵列乘法,并将结果求和。得到K11的梯度。
Mat temp1,temp2;
flip(*(m_pDelta+connectionRow),temp1,-1);//旋转180度,做相关运算
conv2(*(plastLayer->m_cFeatureMapAfter+connectionCol),temp1,temp2,CONVOLUTION_VALID);
//对卷积核的更新
*(m_pConvolutionKernel+KernelIndex++) += -m_learningrate_kernel*temp2;
这一过程的部分C++代码如上,是借助了opencv实现的,其中conv2没有现成的函数,需要自己实现。这里也一同给出conv2的实现。
enum ConvolutionType
{
/* Return the full convolution, including border */
CONVOLUTION_FULL,
/* Return only the part that corresponds to the original image */
CONVOLUTION_SAME,
/* Return only the submatrix containing elements that were not influenced by the border */
CONVOLUTION_VALID
};
//卷积运算
void CCnnConv::conv2(const cv::Mat &img, const cv::Mat& ikernel, cv::Mat& dest, ConvolutionType type)
{
cv::Mat kernel;
//将ikernel旋转180度。
flip(ikernel,kernel,-1);
cv::Mat source = img;
if(CONVOLUTION_FULL == type)
{
source = cv::Mat();
const int additionalRows = kernel.rows-1, additionalCols = kernel.cols-1;
copyMakeBorder(img, source, (additionalRows+1)/2, additionalRows/2, (additionalCols+1)/2, additionalCols/2, cv::BORDER_CONSTANT, cv::Scalar(0));
}
cv::Point anchor(kernel.cols - kernel.cols/2 - 1, kernel.rows - kernel.rows/2 - 1);
int borderMode = cv::BORDER_CONSTANT;
filter2D(source, dest, img.depth(), kernel, anchor, 0, borderMode);
if(CONVOLUTION_VALID == type)
{
dest = dest.colRange((kernel.cols-1)/2, dest.cols - kernel.cols/2).rowRange((kernel.rows-1)/2, dest.rows - kernel.rows/2);
}
}这里在很多的博客和论文中也没有说清楚,主要是对卷积核的更新过程结果要不要旋转180度。这里作说明,如果之前对卷积核旋转180度时没有保存这个旋转,那么这里卷积核的梯度结果,同样不用旋转即conv2(X,rot180(delta), CONVOLUTION_ VALID)
。如何之前对卷积核的旋转覆盖了之前的卷积核,这里要加旋转180度即rot180(conv2(X,rot180(delta),
CONVOLUTION
_VALID))
S2:
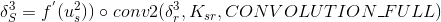
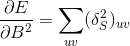
这里是第二个难点:

在知道l层的灵敏度,推出l-1层的梯度时,对l-1层的X11,X12,X13,……分别求导得到如下图结果
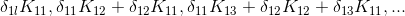
可以明显的看出delta和K在做卷积运算,卷积神经网络也因此得名。这里在一些论文和博客中也没有说清楚,这里在做卷积的卷积核实不需要旋转180度的,卷积运算本身就是将卷积核旋转180度后,做相关运算,所以这里的卷积核不需要旋转180度。
C1:
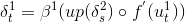
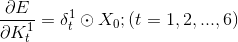
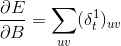
到这里为止,公式就推完,知道了各层的前向传播的公式和后向传播的公式,编程起来就不那么复杂。但是要成功的搭建起卷积网络光知道公式是不行的,下面两个问题同样很重要。
初值
初值的确定是很重要的,否则网络将无法调节,本博客中的初值的确定的原则是,使各神经元输出(进过激发函数后)值在[-1,1]之间,图像中前景与背景的值,在LeCun论文中分别是定义的前景是1.7159,背景是-0.1,原则是图形像素的均值为0,方差为1。基于本博客中图片的实际情况,定的是前景像素值为1.0,背景像素值为-0.5。各个参数的初值是绝对值小于(1/该层参数数目)的随机数。例如卷积核是5x5的,初值就定位绝对值小于1/25 = 0.04 的随机数。其他的权值类似方式确定初值。这样设定以后出的结果都在0附近,这样调节会更快,更充分。
学习率
学习率的设定,和其梯度的量级有关,梯度量级大对应学习率要小。每次调整学习率乘以梯度的调整量的绝对值要小于(1/该层参数的数目)一个量级。这样可以避免参数值跑偏,当然如果加入正则化项,这些问题都是可以避免的。但是也增加的编程的复杂性,同时也打破了各层的相对独立性(对编程而言)。
下面给出了学习率对网络收敛速度影响的数据。
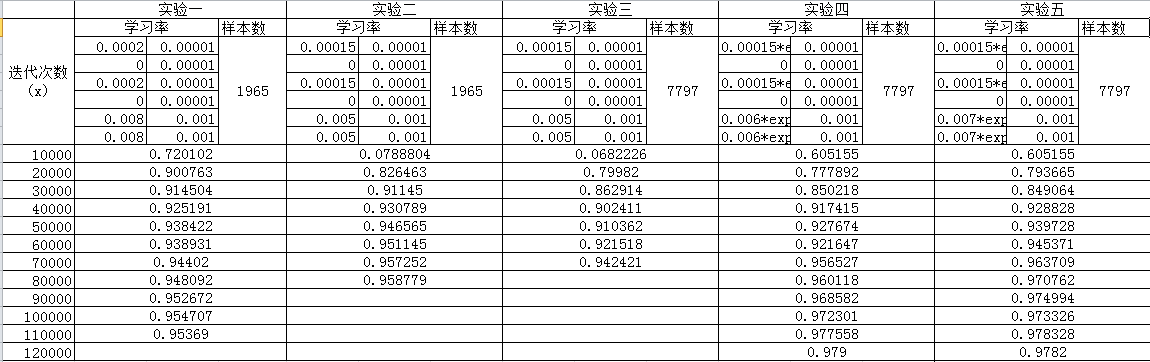
其中记录的数据是训练集上的识别率。
至于代码,本想也贴出来的,但是觉得把核心的公式和算法流程搞清楚,代码的书写就不那么难了,我当时在用C++(借助了opencv)写CNN的时候,用了两周的时间,其中有4天是推公式看论文,3天的时间写代码,1周的时间调试。网络的调试确实是最复杂的。在公式和算法保证正确的情况下,初始值和学习率是很重要的。调试的过程也是对其理解的过程,所以这里就不给出全部代码,还是自己好好写一个,再自己好好调试一下。这里只给出较麻烦的卷积类的代码。
//卷积层
class CCnnConv: public CILayer
{
public:
CCnnConv();
CCnnConv(double learningratekernel,double learningratebias);
~CCnnConv();
public:
//前向传播
virtual void ForwardPropagation(CILayer* pLastLayer);
//后向传播
virtual void BackPropagation(CILayer* pLastLayer,CILayer* pNextLayer);
void setParam(const cv::Mat& connectionMap,const cv::Mat& convKernelSize);
void setLearningrate(double learningratekernel,double learningratebias);
//卷积运算
static void conv2(const cv::Mat &img, const cv::Mat& ikernel, cv::Mat& dst, ConvolutionType type);
//保存数据
virtual void saveData(std::string layerName, ofstream& out);
//加载模型
virtual void loadModel(std::string layerName, ifstream& fin);
public:
//安全访问数据
const PMat& m_cFeatureMapBefore;
const PMat& m_cDelta;
const PMat& m_cFeatureMapAfter;
const int& m_cnumLocalFeatureMap;
const bool& m_cisFullConnection;
const PMat& m_cConvolutionKernel;
const cv::Size& m_csize;//卷积核的大小的引用
const cv::Mat& m_cconnectionMethod;
const cv::Mat& m_clastPoolVector;
const double& m_clearningrate_kernel;
const double& m_clearningrate_bias;
const PMat& m_cB;
private:
double m_learningrate_kernel; //卷积核的学习率
double m_learningrate_bias; //偏置的学习率
cv::Mat m_lastPoolVector; //这层仅仅是对全连接卷积层保存上一层的池化层的向量形式的输出
cv::Mat* m_pFeatureMapBefore; //本层特征映射在没有经过传输函数之前
cv::Mat* m_pFeatureMapAfter; //经过传输函数后的特征映射
int m_numLastFeatureMap; //上一层特征映射的数目
int m_numLocalFeatureMap; //本层或者是下一层特征映射的数目
cv::Mat m_connectionMethod; //卷积的连接方式
cv::Mat* m_pConvolutionKernel; //卷积核
cv::Mat* m_pDelta; //各层delta的值
cv::Mat* m_pB; //各层的偏置
bool m_isFullConnection; //记录是否是全连接
int m_numKernelPixel; //卷积核像素的数目
Size m_size; //卷积核的大小
};
/*卷积类的实现*/
CCnnConv::CCnnConv():
m_cFeatureMapAfter(m_pFeatureMapAfter),
m_cFeatureMapBefore(m_pFeatureMapBefore),
m_cDelta(m_pDelta),
m_isFullConnection(false),
m_cnumLocalFeatureMap(m_numLocalFeatureMap),
m_cisFullConnection(m_isFullConnection),
m_cConvolutionKernel(m_pConvolutionKernel),
m_csize(m_size),
m_cconnectionMethod(m_connectionMethod),
m_clastPoolVector(m_lastPoolVector),
m_clearningrate_bias(m_learningrate_bias),
m_clearningrate_kernel(m_learningrate_kernel),
m_cB(m_pB)
{这里仅仅是初始化,在实际应用中还要自行设置
m_learningrate_kernel = 0.01;
m_learningrate_bias = 0.0001;
}
CCnnConv::CCnnConv(double learningratekernel,double learningratebias):
m_cFeatureMapAfter(m_pFeatureMapAfter),
m_cFeatureMapBefore(m_pFeatureMapBefore),
m_cDelta(m_pDelta),
m_isFullConnection(false),
m_cnumLocalFeatureMap(m_numLocalFeatureMap),
m_cisFullConnection(m_isFullConnection),
m_cConvolutionKernel(m_pConvolutionKernel),
m_csize(m_size),
m_cconnectionMethod(m_connectionMethod),
m_clastPoolVector(m_lastPoolVector),
m_clearningrate_bias(m_learningrate_bias),
m_clearningrate_kernel(m_learningrate_kernel),
m_cB(m_pB)
{
m_learningrate_kernel = learningratekernel;
m_learningrate_bias = learningratebias;
}
CCnnConv::~CCnnConv()
{
}
void CCnnConv::setLearningrate(double learningratekernel,double learningratebias)
{
m_learningrate_kernel = learningratekernel;
m_learningrate_bias = learningratebias;
}
void CCnnConv::loadModel(std::string layerName, ifstream& fin)
{
int numKernel = 0;
for(int i=0;i<3;i++)
{
string data,datakind,size,remindStr;
getline(fin,data,'\n');
datakind = data.substr(0,data.find_first_of(" "));
remindStr = data.substr(data.find_first_of(" ")+1,data.size());
if(datakind=="connectionMethod:")
{
size = data.substr(data.find_first_of(" ")+1,data.size());
int col,row,length;
m_provideFunction.strToNum(size,row,col);
length = row*col;
this->m_numLastFeatureMap = col;
this->m_numLocalFeatureMap = row;
m_connectionMethod = Mat(row,col,CV_8UC1);
uchar *pConnection = this->m_connectionMethod.ptr<uchar>(0);
int temp;
for(int i=0;i<length;i++)
{
fin>>temp;
if(temp == 1) numKernel++;
*(pConnection+i) = temp;
}
//去掉最后的换行符
getline(fin,data,'\n');
}
else if(datakind=="kernel:")
{
string isFullConnection = remindStr.substr(0,remindStr.find_first_of(" "));
size = remindStr.substr(remindStr.find_first_of(" ")+1,remindStr.size());
int row,col;
m_provideFunction.strToNum(size,row,col);
if(isFullConnection == "fullconnection")
{//全连接的卷积层
this->m_numKernelPixel = row/m_numLastFeatureMap;
m_pConvolutionKernel = new Mat(row,col,CV_64FC1);
int length = row*col;
double *pConvolution = m_pConvolutionKernel->ptr<double>(0);
for(int i=0;i<length;i++)
{
fin>>*(pConvolution + i);
}
//类指针必须要初始化
this->m_pFeatureMapBefore = new Mat();
this->m_pFeatureMapAfter = new Mat();
this->m_isFullConnection = true;
m_lastPoolVector = Mat(row,1,CV_64FC1);//400*1
}
else
{//非全连接的卷积层
this->m_numKernelPixel = row*col;
m_pConvolutionKernel = new Mat[numKernel];
for(int kernelIndex=0;kernelIndex < numKernel;kernelIndex++)
{
*(m_pConvolutionKernel + kernelIndex) = Mat(row,col,CV_64FC1); //初始化
double *pKernel = (m_pConvolutionKernel + kernelIndex)->ptr<double>(0);
for(int pixelIndex=0; pixelIndex<m_numKernelPixel; pixelIndex++)
{
fin>>*(pKernel+pixelIndex);
}
}
this->m_pFeatureMapBefore = new Mat[m_numLocalFeatureMap];
this->m_pFeatureMapAfter = new Mat[m_numLocalFeatureMap];
}
getline(fin,data,'\n');
}
else if(datakind=="bias:")
{
m_pB = new Mat(m_numLocalFeatureMap,1,CV_64FC1);
double *pB = m_pB->ptr<double>(0);
for(int i = 0;i<m_numLocalFeatureMap;i++)
{
fin>>*(pB+i);
}
getline(fin,data,'\n');
}
}
}
void CCnnConv::saveData(std::string layerName, ofstream& out)
{
out<<layerName<<"\n";
out<<"connectionMethod:"<<" ";
int row = m_cconnectionMethod.rows;
int col = m_cconnectionMethod.cols;
char rowstr[4],colstr[4];
itoa(row,rowstr,10);
itoa(col,colstr,10);
out<<rowstr<<"x"<<colstr<<endl;
const uchar *pConnection = m_cconnectionMethod.ptr<uchar>(0);
int length = row*col;
for(int i=0;i<length;i++)
{//保存卷积连接方式
out<<(int)(*(pConnection+i))<<" ";
}
out<<endl;
if(m_isFullConnection)
{//全连接与非全连接的卷积层只有卷积核不同
out<<"kernel:"<<" "<<"fullconnection"<<" ";
int krow = m_cConvolutionKernel->rows;
int kcol = m_cConvolutionKernel->cols;
char krowstr[4],kcolstr[4];
itoa(krow,krowstr,10);
itoa(kcol,kcolstr,10);
out<<krowstr<<'x'<<kcolstr<<endl;
int klength = krow*kcol;
double *pKernel = m_pConvolutionKernel->ptr<double>(0);
for(int i=0;i<klength;)
{
out<<*(pKernel+i)<<" ";
i++;
if(i%kcol==0)
out<<endl;
}
}
else
{
out<<"kernel:"<<" ";
int krow = m_cConvolutionKernel->rows;
int kcol = m_cConvolutionKernel->cols;
char krowstr[4],kcolstr[4];
itoa(krow,krowstr,10);
itoa(kcol,kcolstr,10);
out<<krowstr<<'x'<<kcolstr<<endl;
int klength = krow*kcol;
int kernelIndex = -1;
for(int i=0;i<length;i++)
{
if(*(pConnection+i) == 1)
{
kernelIndex++;
double *pKernel = (m_cConvolutionKernel + kernelIndex)->ptr<double>(0);
for(int j=0;j<klength;j++)
{
out<<*(pKernel+j)<<' ';
}
out<<endl;
}
}
}
out<<"bias:"<<endl;
double *pBias = m_cB->ptr<double>(0);
for(int i=0;i<row;i++)
{
out<<*(pBias+i)<<' ';
}
out<<endl;
}
//设置参数
void CCnnConv::setParam(const cv::Mat& connectionMap,const cv::Mat& convKernelSize)
{
if(connectionMap.channels()!=1||convKernelSize.channels()!=1)return;
m_isEmpty = false;
connectionMap.copyTo(m_connectionMethod);
//计算卷积后的map数目
int sum=0;
m_size = convKernelSize.size();
const uchar *pConnectionMap = connectionMap.ptr<uchar>(0);
int row = connectionMap.rows,col = connectionMap.cols;
int length = row*col;
for(int i=0;i<length;i++)
{
if(*(pConnectionMap+i)==1)sum++;
}
//卷积核中像素的数目
this->m_numKernelPixel = convKernelSize.rows*convKernelSize.cols;
this->m_numLastFeatureMap = connectionMap.cols;
this->m_numLocalFeatureMap = connectionMap.rows;
if(sum!=length || col==1)
{//该卷积层不是全连接层全连接的上一层不可能是输入层
this->m_pConvolutionKernel = new cv::Mat[sum];
for(int i=0;i<sum;i++)
{//初始化卷积核
Mat temp = Mat(convKernelSize.size(),CV_64FC1);
this->m_provideFunction.initParamByRand(temp,0.04);
temp.copyTo(*(m_pConvolutionKernel+i));
}
this->m_pB = new Mat(row,1,CV_64FC1);
//初始化偏置
this->m_provideFunction.initParamByRand(*(m_pB),0.001);
//本层得到的特征映射
this->m_pFeatureMapBefore = new Mat[m_numLocalFeatureMap];
this->m_pFeatureMapAfter = new Mat[m_numLocalFeatureMap];
this->m_pDelta = new Mat[m_numLocalFeatureMap];//各灵敏度申请空间
}
else
{//该卷积层是全连接层
m_isFullConnection=true;
m_lastPoolVector = Mat(m_numKernelPixel*m_numLastFeatureMap,1,CV_64FC1);//(25*16)*1:400*1
int size = convKernelSize.rows*convKernelSize.cols;
int wrow = size*m_numLastFeatureMap;
int wcol = m_numLocalFeatureMap;
this->m_pConvolutionKernel = new Mat(wrow,wcol,CV_64FC1);//将全连接的卷积核连接成一个大的权矩阵
this->m_pB = new Mat(m_numLocalFeatureMap,1,CV_64FC1);
//初始化参数
m_provideFunction.initParamByRand(*(m_pConvolutionKernel),0.0025);
m_provideFunction.initParamByRand(*(m_pB),0.001);
this->m_pFeatureMapBefore = new Mat();
this->m_pFeatureMapAfter = new Mat();
m_pDelta = new Mat();
}
}
//前向传播
void CCnnConv::ForwardPropagation(CILayer* pLastLayer)
{
CCnnPool* plastLayer = (CCnnPool*)pLastLayer;
if(m_numLastFeatureMap == 1)//INPUT层的数据
{
double *pB = m_pB->ptr<double>(0);
Mat temp;
for(int i=0;i<m_numLocalFeatureMap;i++)
{
//激发函数(传输函数)之前
flip(*(m_pConvolutionKernel+i),temp,-1); //旋转180度
conv2(*(plastLayer->m_cFeatureMapAfter),temp,*(m_pFeatureMapBefore+i),CONVOLUTION_VALID);
cout<<*(plastLayer->m_cFeatureMapAfter)<<endl;
*(m_pFeatureMapBefore+i) = *(m_pFeatureMapBefore+i)+*(pB+i); 加上偏置
cout<<*(m_pFeatureMapBefore+i)<<endl;
//经过激发函数(传输函数)之后
//cout<<*(plastLayer->m_cFeatureMapAfter)<<endl;
//cout<<*(m_pFeatureMapBefore+i)<<endl;
int length = m_pFeatureMapBefore->rows*m_pFeatureMapBefore->cols;
*(m_pFeatureMapAfter+i) = Mat(m_pFeatureMapBefore->size(),CV_64FC1);
double *pFeatureMapBefore = (m_pFeatureMapBefore+i)->ptr<double>(0);
double *pFeatureMapAfter = (m_pFeatureMapAfter+i)->ptr<double>(0);
for(int index=0;index<length;index++)
{
*(pFeatureMapAfter+index) = A*tanh(aaa*(*(pFeatureMapBefore+index)));
//*(pFeatureMapAfter+index) = tanh((*(pFeatureMapBefore+index)));
}
}
//cout<<temp<<"\n\n"<<endl;
//cout<<*(m_pFeatureMapAfter)<<endl;
}
else
{
if(m_isFullConnection)
{//如果该卷积层是全连接的,上一层的map的大小必须和卷积核的大小是相同的
double * pLocalFeatureMap = m_lastPoolVector.ptr<double>(0);
for(int i=0;i<m_numLastFeatureMap;i++)
{//将上一层的卷积核都向量化
const double *pLastFeatureMap = (*(plastLayer->m_cFeatureMapAfter+i)).ptr<double>(0);
for(int j=0;j<m_numKernelPixel;j++)
{
*(pLocalFeatureMap+i*m_numKernelPixel+j) = *(pLastFeatureMap+j);
}
}
//400*120->120*400, (120*400)*(400*1)
*(m_pFeatureMapBefore) = ((*(this->m_pConvolutionKernel)).t())*m_lastPoolVector+*(m_pB);
cout<<"5 layer;before"<<*(m_pFeatureMapBefore)<<endl;
//经过传输函数(激发函数)过后
int length = m_pFeatureMapBefore->rows*m_pFeatureMapBefore->cols;
*(m_pFeatureMapAfter) = Mat(m_pFeatureMapBefore->size(),CV_64FC1);
double *pFeatureMapBefore = (m_pFeatureMapBefore)->ptr<double>(0);
double *pFeatureMapAfter = (m_pFeatureMapAfter)->ptr<double>(0);
for(int index=0;index<length;index++)
{
*(pFeatureMapAfter+index) = A*tanh(aaa*(*(pFeatureMapBefore+index)));
*(pFeatureMapAfter+index) = tanh(*(pFeatureMapBefore+index));
}
//cout<<"第五层after"<<*(m_pFeatureMapAfter)<<endl;
}
else
{
int kernelIndex=0;
//卷积后图像的行和列的大小
int afterrow = plastLayer->m_cFeatureMapAfter->rows - m_pConvolutionKernel->rows + 1;
int aftercol = plastLayer->m_cFeatureMapAfter->cols - m_pConvolutionKernel->cols + 1;
for(int numFeatureMap=0;numFeatureMap<m_numLocalFeatureMap;numFeatureMap++)
{//本层的特征map的数目
uchar *pConnectionMethod = this->m_connectionMethod.ptr<uchar>(numFeatureMap);
//本层的特征map赋初值
*(m_pFeatureMapBefore + numFeatureMap) = Mat::zeros(afterrow,aftercol,CV_64FC1);
for(int numLastFeatureMap=0;numLastFeatureMap<m_numLastFeatureMap;numLastFeatureMap++)
{//上一层的特征map的数目
Mat result;
if(*(pConnectionMethod+numLastFeatureMap)==1)
{
Mat temp;
flip(*(this->m_pConvolutionKernel+kernelIndex),temp,-1);//将卷积核旋转180度
conv2(*(plastLayer->m_cFeatureMapAfter+numLastFeatureMap),
temp,result,CONVOLUTION_VALID);
kernelIndex++; //卷积的索引加一
*(m_pFeatureMapBefore + numFeatureMap) += result;
}
}
//经过激发(传输)函数之前
*(m_pFeatureMapBefore + numFeatureMap) += m_pB->at<double>(numFeatureMap);
cout<<*(plastLayer->m_cFeatureMapAfter+0)<<endl;
cout<<*(m_pFeatureMapBefore + numFeatureMap)<<endl;
int Length = m_pFeatureMapBefore->rows*m_pFeatureMapBefore->cols;
*(m_pFeatureMapAfter+numFeatureMap) = Mat(m_pFeatureMapBefore->size(),CV_64FC1);
double *pFeatureMapBefore = (m_pFeatureMapBefore+numFeatureMap)->ptr<double>(0);
double *pFeatureMapAfter = (m_pFeatureMapAfter+numFeatureMap)->ptr<double>(0);
for(int index=0;index<Length;index++)
{
*(pFeatureMapAfter+index) = A*tanh(aaa*(*(pFeatureMapBefore+index)));
*(pFeatureMapAfter+index) = tanh((*(pFeatureMapBefore+index)));
}
}
//cout<<"kernel:: "<<*(this->m_pConvolutionKernel)<<endl;
//cout<<*(m_pFeatureMapAfter)<<endl;
}
}
}
//后向传播
void CCnnConv::BackPropagation(CILayer* pLastLayer,CILayer* pNextLayer)
{
if(m_isFullConnection)
{
CCnnPool* plastLayer = (CCnnPool*)pLastLayer;
CCnnFull* pnextLayer = (CCnnFull*)pNextLayer;
*m_pDelta = ((pnextLayer->m_cW)*(*(pnextLayer->m_cDelta))).mul
(Aa*(1-AA*(*(m_pFeatureMapAfter)).mul(*(m_pFeatureMapAfter))));
*m_pDelta = ((pnextLayer->m_cW)*(*(pnextLayer->m_cDelta))).mul
((1-(*(m_pFeatureMapAfter)).mul(*(m_pFeatureMapAfter))));
//cout<<*m_pDelta<<endl;
Mat dW = m_clastPoolVector*((*(m_pDelta)).t()); //400*120
//梯度下降调节权值
*m_pConvolutionKernel += -m_learningrate_kernel*dW;
//调节偏置
*m_pB += -m_learningrate_bias*(*m_pDelta);
//cout<<"5:"<<endl<<dW<<endl;
//cout<<"dB:"<<(*m_pDelta)<<endl;
}
else
{非全连接层
CCnnPool* plastLayer = (CCnnPool*)pLastLayer;
CCnnPool* pnextLayer = (CCnnPool*)pNextLayer;
int row = m_pFeatureMapAfter->rows;
int col = m_pFeatureMapAfter->cols;
for(int i=0;i<m_numLocalFeatureMap;i++)
{//求解灵敏度
Mat temp;
resize((*(pnextLayer->m_cDelta+i)),temp,Size(col,row),0,0,0);
*(m_pDelta+i) =(pnextLayer->m_cBeta->at<double>(i))*temp.mul(Aa*(1-AA*(*(m_pFeatureMapAfter+i)).mul(*(m_pFeatureMapAfter+i))));
*(m_pDelta+i) =(pnextLayer->m_cBeta->at<double>(i))*temp.mul(1-(*(m_pFeatureMapAfter+i)).mul(*(m_pFeatureMapAfter+i)));
}
if(debugtimes>DEBUGTIMES)
{
cout<<1-AA*(*(m_pFeatureMapAfter)).mul(*(m_pFeatureMapAfter))<<endl<<endl;
cout<<*(pnextLayer->m_cBeta)<<endl<<endl;
cout<<*(pnextLayer->m_cDelta)<<endl<<endl;
cout<<*(m_pDelta)<<endl;
}
uchar *pKernelMap = m_connectionMethod.ptr<uchar>(0); //卷积的连接方式
int lenght = m_connectionMethod.rows*m_connectionMethod.cols;
const int unit = m_connectionMethod.cols; //上一层的featureMap的数目
int KernelIndex=0; //当前用到的卷积核的索引
for(int i =0;i<lenght;i++)
{
if(*(pKernelMap+i) == 1)
{//为1表示有这个连接
int connectionCol = i%unit;
int connectionRow = i/unit;
Mat temp1,temp2;
flip(*(m_pDelta+connectionRow),temp1,-1); //旋转180度,做相关运算
conv2(*(plastLayer->m_cFeatureMapAfter+connectionCol),temp1,temp2,CONVOLUTION_VALID);
//对卷积核的更新
*(m_pConvolutionKernel+KernelIndex++) += -m_learningrate_kernel*temp2;
if(debugtimes>DEBUGTIMES)
{
cout<<"dKernel:"<<temp2<<endl;
cout<<"kernel: "<<*(m_pConvolutionKernel+KernelIndex-1)<<endl;
}
}
}
Mat dB = Mat::zeros(m_numLocalFeatureMap,1,CV_64FC1); //求偏置的偏导
double *pdB = dB.ptr<double>(0);
for(int i=0;i<m_numLocalFeatureMap;i++)
{
Scalar s = sum(*(m_pDelta+i));
*(pdB+i) = s.val[0];
}
//对偏置的更新
*m_pB += -m_learningrate_bias*dB;
if(debugtimes>DEBUGTIMES)
{
cout<<*m_pDelta<<endl;
cout<<"dB"<<dB<<endl;
cout<<"m_B"<<*m_pB<<endl;
}
}
}
//卷积运算
void CCnnConv::conv2(const cv::Mat &img, const cv::Mat& ikernel, cv::Mat& dest, ConvolutionType type)
{
cv::Mat kernel;
//将ikernel旋转180度。
flip(ikernel,kernel,-1);
cv::Mat source = img;
if(CONVOLUTION_FULL == type)
{
source = cv::Mat();
const int additionalRows = kernel.rows-1, additionalCols = kernel.cols-1;
copyMakeBorder(img, source, (additionalRows+1)/2, additionalRows/2, (additionalCols+1)/2, additionalCols/2, cv::BORDER_CONSTANT, cv::Scalar(0));
}
cv::Point anchor(kernel.cols - kernel.cols/2 - 1, kernel.rows - kernel.rows/2 - 1);
int borderMode = cv::BORDER_CONSTANT;
filter2D(source, dest, img.depth(), kernel, anchor, 0, borderMode);
if(CONVOLUTION_VALID == type)
{
dest = dest.colRange((kernel.cols-1)/2, dest.cols - kernel.cols/2).rowRange((kernel.rows-1)/2, dest.rows - kernel.rows/2);
}
}















 24
24

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









