






程序世界的barrier
同步屏障(Barrier)是并行计算中的一种同步方法。对于一群进程或线程,程序中的一个同步屏障意味着任何线程/进程执行到此后必须等待,直到所有线程/进程都到达此点才可继续执行下文。-wiki
关于barrier的理解
barrier字面意思是栅栏、屏障,它们起到隔离或者保护的作用。就好比特朗普要修建的墨西哥墙便是一种barrier。

image
CPU和编译器的乱序优化
接下来要讲的是Memory barrier,这个还得从头说起。CPU和编译器都会对程序做一定程度的优化,但是总会遵循一个原则:代码在单线程运行时不会改变程序的结果,有依赖关系的语句不会被重排。在提高性能的同时,也使得代码的执行过程与源码不太一样,多线程环境下能够观测到一些乱序现象。
-
CPU的内存乱序
以下两种特性造成了内存乱序-
乱序执行(out-of-orderexecution):
是指CPU允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理的技术。这样将根据个电路单元的状态和各指令能否提前执行的具体情况分析后,将能提前执行的指令立即发送给相应电路单元执行,在这期间不按规定顺序执行指令,然后由重新排列单元将各执行单元结果按指令顺序重新排列。采用乱序执行技术的目的是为了使CPU内部电路满负荷运转并相应提高了CPU的运行程序的速度。乱序执行的好处:
我们来看一个宏观上的例子:下载图片A->展示图片A->保存图片A->下载图片B->保存图片B
这个流程需要5个时钟周期
由于CPU可以同时处理多个指令,并且A和B没有依赖,于是优化为:下载图片A->展示图片A->保存图片A下载图片B->保存图片B
优化后只要3个时钟周期 -
CPU高速缓存(CPU caches):
为了提高运行速度,CPU内置多级高速缓存,我们常常听到的L1,L2...高速缓存,高速缓存的读写速度要远高于内存。在读写内存时,则是提前将内容载入到高速缓存或者将结果写入高速缓存,再由高速缓存写入主存(计算机内存),这样就减少CPU读写内存时的等待时间,但同时造成了内存读写的不同步,感官上形成了内存读写乱序。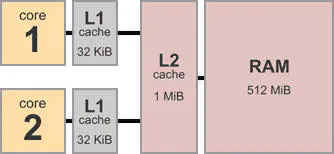
cpu-diagra
-
-
编译器指令重排
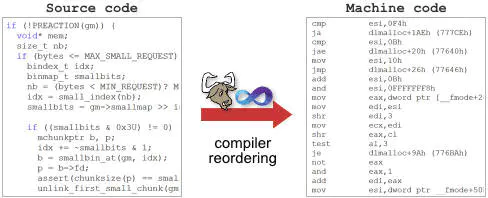
compiler-reordering
我们知道编译器的工作是把源代码转换为CPU可以读的机器代码,转换过程中编译器可以自主做很多优化工作。
编译优化举例:
* 公共子表达式删除(Common Subexpression Elimination)
```Objective-C
a = b * c + g; //----------> tmp = b * c;
d = b * c * e; // rewrite a = tmp + g;
// d = tmp * e;
```
* 死代码删除([Dead Code Elimination](https://en.wikipedia.org/wiki/Dead_code_elimination))
```Objective-C
int foo(void)
{
int a = 24;
int b = 25; /* Assignment to dead variable */
int c;
c = a * 4;
return c;
b = 24; /* Unreachable code */
return 0;
}
==>
int foo(void)
{
int a = 24;
int c;
c = a * 4;
return c;
}
```
* 指令调度(Instruction Scheduling):目前的CPU下面指令重排后,下一条指令不必等待前一条的结果, 从而减少了停顿
```Objective-C
load %r0, 0($mem0) // load %r0, 0($mem0)
mul %r1, %r1, %r0 //-----------> load %r2, 0($mem2)
store 0($mem1), %r1 // rewrite mul %r1, %r1, %r0
load %r2, 0($mem2) // mul %r3, %r3, %r2
mul %r3, %r3, %r2 // store 0($mem1), %r1
store 0($mem3), %r3 // store 0($mem3), %r3
```
Memory ordering wiki
编译器和CPU的各种优化会修改指令的执行时机,造成存储器访问顺序的变化;尽管如此,在单线程程序中,这些优化不会影响程序的运行结果,程序员也不需要关心优化对程序的影响。
但是在多线程情况下,编译器和多处理器没有办法自动发现线程间的协作关系。影响程序运行结果的是两点:一个是输入,它决定初始条件,一个是输出,它决定对外的结果,而计算机中的数据都以存储器为载体,所以最终各种优化带来的副作用表现为内存读写顺序与源码不一致。
这段代码是一个无锁编程的场景:
子线程处理任务,并在任务完成时将标记改为true,finished存在多线程访问,因此声明为原子类型,存取操作也是用原子操作。主线程自旋等待直到任务标记完成,接下来读取任务的结果,经过多次循环,产生了不可思议的结果,finished为true的情况下task的值竟然为0;
- (void)cpuReorderTest {
// Test at iPhone 6sPlus iOS 12.2
long long loop_count = 0;
while (1) {
__block atomic_bool finished = ATOMIC_VAR_INIT(false);
__block int task = 0;
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
task = 1;
// 标记任务为已执行
atomic_store_explicit(&finished, true, memory_order_relaxed);
while (arc4random()%10);
});
while (!atomic_load_explicit(&finished, memory_order_relaxed));
int task_now = task;
if (task_now != 1) {
NSLog(@"assert at %lld", loop_count);
assert(0);
}
loop_count++;
}
}
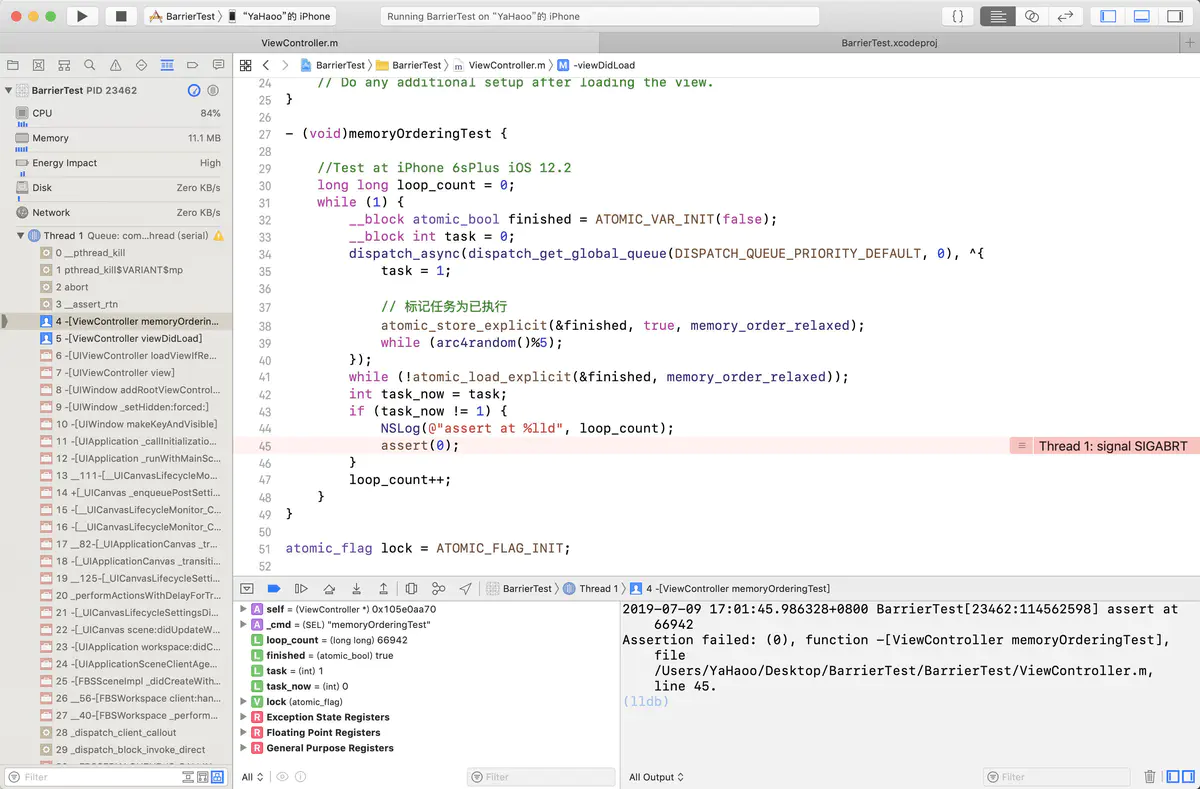
memoryOrdering
分析下原因,在多线程环境下,变量task和变量finished在处理器或者编译器眼里是两个独立的变量不存在任何联系,(尽管程序员认为它们是有关联的,task赋值发生在finished赋值之前,finished用来反映task的状态),因此在编译器和CPU在优化过程中没有义务保证task和finished的内存读写顺序和源码一致,目前我们对现象至少可以做几点归纳:
- 造成当前状况源于CPU的优化,因为debug情况下没有使用编译优化
- finished和task的赋值操作应该和代码不一致
- 在模拟器上运行没有问题,但是在手机上却能走到assert?
Memory models
多线程环境下,普通代码往往发生的各种各样的非预期的Memory ordering,取决于处理器和和使用的工具链(软件层面用于控制编译和CPU乱序问题的工具,比如,C11中引入的stdatomic.h,apple的OSAtomic.h)。Memory models的作用就是定义运行时CPU会产生何种乱序,或者工具链可以实现何种乱序控制(具体下来就是一组原子操作和内存屏障方法)。
对于内存来说,操作分为读(Load)和写(Store),Memory ordering就是读写操作的组合:LoadLoad,StoreStore,LoadStore,StoreLoad
以cpuReorderTest代码发生的状况为例:
解释1StoreStore乱序:
我们是先Store``task,再Store``finished,由于高速缓存的存在,实际可能是Store``finished先写入成功,Store``task后写入成功,于是就形成了asset的状况,这里两个变量的写入顺序和源码不一致,可以认为是StoreStore乱序。
在硬件层面不同的CPU,允许不同程度的内存乱序:
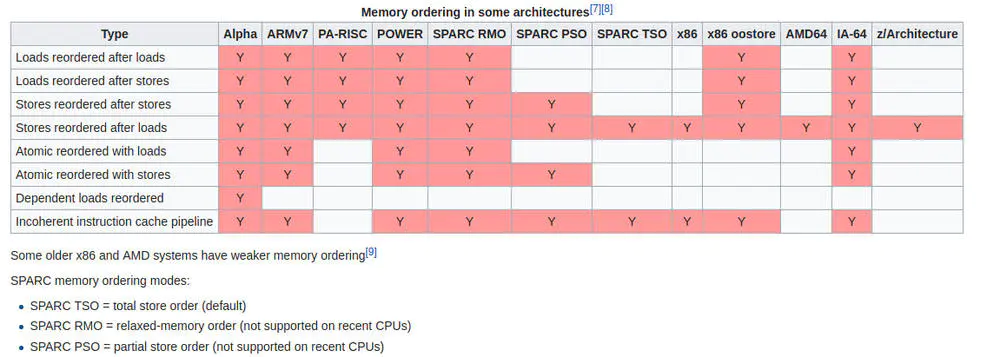
569506-9212c5b887c
从上图看出ARM处理器允许大部分乱序(weak memory model),而X86则允许少部分乱序(strong memory model),也就是说,在ARM上能被观测到异常的代码,可能不做任何处理就可以在X86上正常运行。
如何解决乱序问题呢,系统提供了一些工具链,在软件层面制定了Memory Model规范,程序员通过工具链中的同步设施(各种内存屏障(Memory Barrier)和Atomic指令)来标记多个线程间的协作关系。
Memory barrier
Memory barrier我们可能不是很熟悉,多线程开发中,我们用的最多的是各种锁或者信号量,锁和信号量内部都会用到Memory barrier来对内存排序进行约束。
// acquire和release便是指定了不同的内存序
long
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
......
}
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
long value = os_atomic_inc2o(dsema, dsema_value, release);
......
}
-
OSAtomic
OSAtomic是Apple提供的api,其中大部分是原子操作函数,原子操作函数有一个普通版本和一个barrier版本,前者使用的memory_order_relaxed后者是memory_order_seq_cstOSATOMIC_INLINE
int32_t
OSAtomicAdd32(int32_t __theAmount, volatile int32_t __theValue)
{
return (OSATOMIC_STD(atomic_fetch_add_explicit)(
(volatile _OSAtomic_int32_t) __theValue, __theAmount,
OSATOMIC_STD(memory_order_relaxed)) + __theAmount);
}
//
// barrier版本
OSATOMIC_INLINE
int32_t
OSAtomicAdd32Barrier(int32_t __theAmount, volatile int32_t __theValue)
{
return (OSATOMIC_STD(atomic_fetch_add_explicit)(
(volatile _OSAtomic_int32_t) __theValue, __theAmount,
OSATOMIC_STD(memory_order_seq_cst)) + __theAmount);
}
......
```
除了原子操作函数,还提供了一个OSMemoryBarrier函数
```Objective-C
OSATOMIC_INLINE
void
OSMemoryBarrier(void)
{
OSATOMIC_STD(atomic_thread_fence)(OSATOMIC_STD(memory_order_seq_cst));
}
```
普通版本的原子函数使用的内存排序约束为memory_order_relaxed含义是不约束内存排序,相对于前后的代码而言,当前原子操作可能被提前或者延迟。而barrier版本使用的是memory_order_seq_cst则表示执行到当前原子操作代码时,之前的读写操作都完成了,之后的读写操作还没开始,严格保证代码间的相对顺序。
- stdatomic/atomic
作为底层功能代码,C11和C++11标准对原子同步原语这块做了统一定义,避免不同平台使用不同的实现,目前OSAtomic已经标记为deprecated,直接使用C11或C++11的接口。
stdatomic中的原子操作函数,可以指定memory order,它是一个枚举类型typedef enum memory_order { memory_order_relaxed = __ATOMIC_RELAXED, memory_order_consume = __ATOMIC_CONSUME, memory_order_acquire = __ATOMIC_ACQUIRE, memory_order_release = __ATOMIC_RELEASE, memory_order_acq_rel = __ATOMIC_ACQ_REL, memory_order_seq_cst = __ATOMIC_SEQ_CST } memory_order;
-
memory_order_relaxed
表示不约束内存读写顺序,仅仅保证操作的原子性和修改的顺序性
(A线程修改后,改动对于B线程不是立即可见,常用于不需要考虑线程关系的场景,比如多线程操作计数器) -
memory_order_consume
该类型配合读来使用,当前线程中,当前consume操作之后的所有的对于当前原子变量的读和写都被限定在当前consume操作之后。当前线程可以看到其他线程在release相同原子变量之前的所有关于当前原子变量的内存写入操作。例如:其他线程计算得到结果r=1,并且紧接着release原子变量f=a(a.status等于"finished"),标识任务完成,那么当前线程consume变量f并且当f存时,一定有status == "finished",但是此时并不能保证r=1,因为consume不能保证r的读取顺序,r的读取理论上可能先于f的读取。
-
memory_order_acquire
该类型配合读来使用,当前线程中,当前acquire操作之后的所有的读和写都被限定在当前原子变量的acquire操作之后。当前线程可以看到其他线程在release相同原子变量之前的所有内存写入操作。例如:其他线程计算得到结果r=1,并且紧接着release变量f=1,标识任务完成,那么当前线程acquire变量f并且当f==1时,一定能读取到其他线程的结果r=1;
-
memory_order_release
该类型配合写入使用,当前线程中,release操作之前的所有的读和和写都被限定在release之前,其他线程在acquire相同原子变量后可以看到当前线程的所有写入操作, 其他线程在consume相同原子变量时可以看到当前线程对于该变量的写入操作,acquire和consume和release组合使用的区别是,其他线程可以看到当前线程在release之前的所有修改,另一个是只能看到当前线程对于当前原子变量的修改 -
memory_order_acq_rel
该类型配合读写改函数使用,因为函数包含三个操作,没办法只用acquire或者release。例如:
atomic_compare_exchange_strong,相当于读使用acquire和写使用release。 -
memory_order_seq_cst
该类型是一个复合类型,写操作时使用release,读使用acquire,读写改操作使用acq_rel
使用acquire和release实现一个自旋锁,acquire的特点是,下面的读写不能越过acquire,release的特点是上面的读写不能越过release,这样acquire和release就把关键代码给包裹起来了,代码块中的读写都被限制在区域内。
#include <stdatomic.h>
#include <pthread.h>
atomic_flag lock = ATOMIC_FLAG_INIT;
- (void)lock {
while (atomic_flag_test_and_set_explicit(&lock, memory_order_acquire)) {
pthread_yield_np();
}
}
- (void)unlock {
atomic_flag_clear_explicit(&lock, memory_order_release);
}
- (void)spinLockTest {
//Test at iPhone 6sPlus iOS 12.2
__block unsigned long long count = 0;
long long loop = 10000000;
void (^add)(void) = ^{
for (long long i = 0; i < loop; i++) {
[self lock];
count++;
[self unlock];
}
[self lock];
NSLog(@"%lld", count);
[self unlock];
};
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
add();
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
add();
});
}
Dispatch barrier
Dispatch barrier是GCD中的一组函数,Memory barrier侧重于内存粒度的控制,而dispatch barrier侧重于宏观上的任务约束。
支持并发的队列在执行任务时,任务的执行时间线会产生重叠,如下图,同一个时间内,Task 1,2,3在同时执行,有利于发挥多核优势,但容易引起数据竞争。
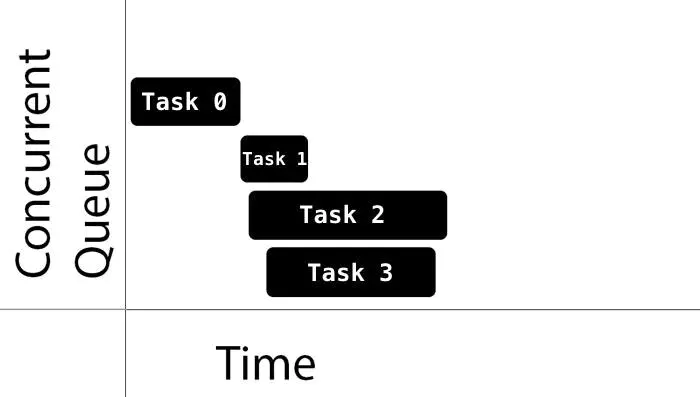
Concurrent-Queue-Swift
对于一个串行队列,任务执行的时间线是有序的,一个时刻只有一个任务在运行,缺点是不能充分利用多核资源。
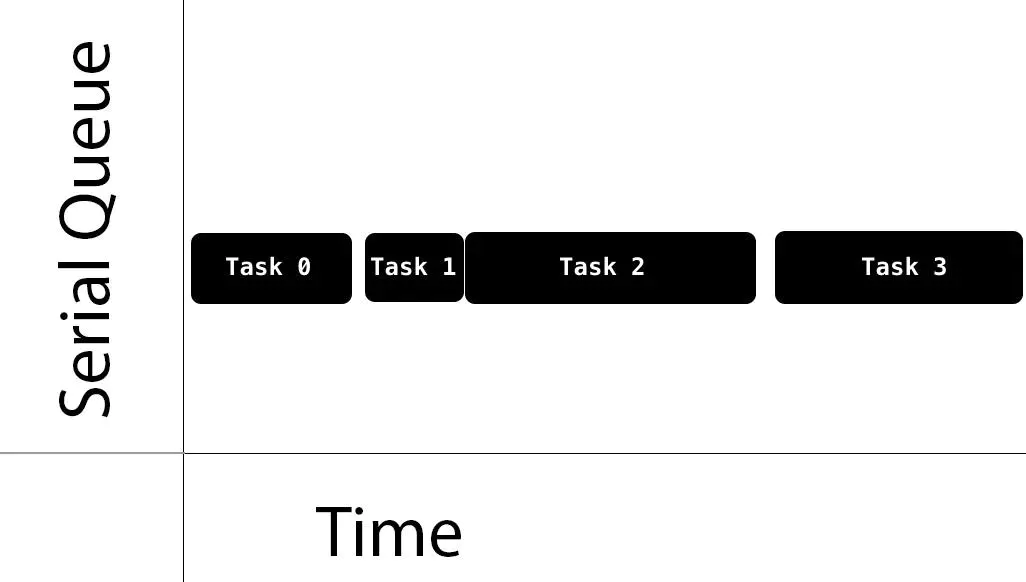
Serial-Queue-Swift
dispatch barrier则较好地结合了二者的优势,可并发可独占。向队列中插入barrier任务时,会等当前正在执行的任务执行完,再去执行barrier任务,barrier任务从等待执行到执行结束这段时间内新进的任务都会被排在barrier任务之后执行。
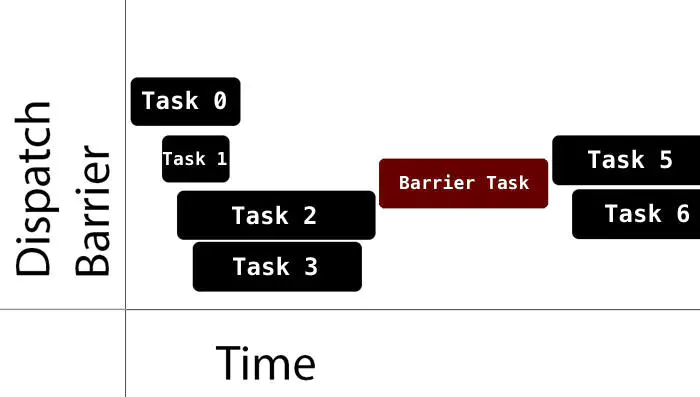
Dispatch-Barrier-Swift
注意点:队列必须要支持并发,并且提交的队列不能是global queue,否则和dispatch_async()/dispatch_sync()效果一样。
- (void)dispatchBarrierTest {
__block int count = 0;
dispatch_queue_t queue = dispatch_queue_create("", DISPATCH_QUEUE_CONCURRENT);
// 对count进行读写
[NSTimer scheduledTimerWithTimeInterval:0.2 repeats:YES block:^(NSTimer * _Nonnull timer) {
if (arc4random()%3 != 0) {
dispatch_async(queue, ^{
NSLog(@"read \tcount:%d", count);
});
}
else {
dispatch_barrier_async(queue, ^{
count++;
NSLog(@"write \tcount:%d", count);
});
}
}];
}
多线程问题分析
- 多线程Data race,释放正在使用的对象,经验中,多线程崩溃问题大多数属于此类问题
- (void)dataRaceTestReleaseObjectInUse {
// 释放了正在使用的对象
// Test at iPhone 6sPlus iOS 12.2 or
// MacOS 10.14.5 simulator iPhoneSE 12.2
long long loop_count = 0;
while (1) {
__block NSObject *task = nil;
__block BOOL didFinishe = NO;
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
while (arc4random()%2);
if(!task) {
task = [[NSObject alloc]init];
}
didFinishe = YES;
});
while (arc4random()%2);
if(!task) {
task = [[NSObject alloc]init];
}
while (!didFinishe) {
[task description];
}
loop_count++;
}
}
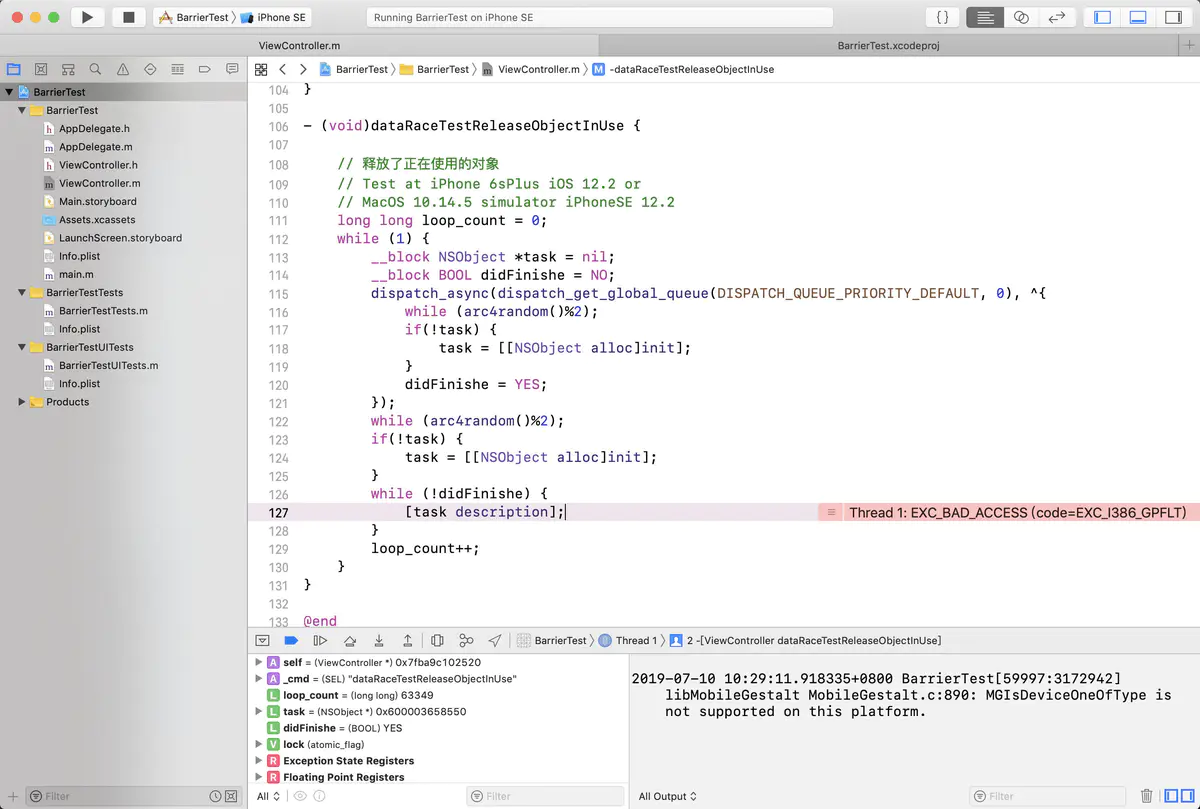
releaseObjectInUse
原因分析:
if(!task) {
task = [[NSObject alloc]init];
}
该代码逻辑,极端情况下两个线程可能同时走到,当主线程调用[task description]过程中,子线程调用了task = [[NSObject alloc]init],主线程正在使用的task对象内存会被立即释放,继续使用将会造成内存访问错误。
解决方案:1、避免多线程访问,2、子线程需要读取的数据可以通过临时变量传入,避免直接访问,3、对公共变量的访问加锁
- 多线程Data race,造成读写不符合预期,比如我们的计数器变量有时候不准确或者值异常。
- (void)dataRaceTestNotMeetExpectations {
// 数据竞争导致的读写结果不符合预期
// MacOS 10.14.5 simulator iPhone4s 12.2(32位)
__block long long ts = 1;
dispatch_async(dispatch_queue_create("", DISPATCH_QUEUE_CONCURRENT), ^{
while (1) {
ts = 1;
while (arc4random()%2);
}
});
dispatch_async(dispatch_queue_create("", DISPATCH_QUEUE_CONCURRENT), ^{
while (1) {
ts = -1;
while (arc4random()%2);
}
});
while (1) {
long long a = ts;
assert(a == 1 || a == -1);
usleep(100);
}
}
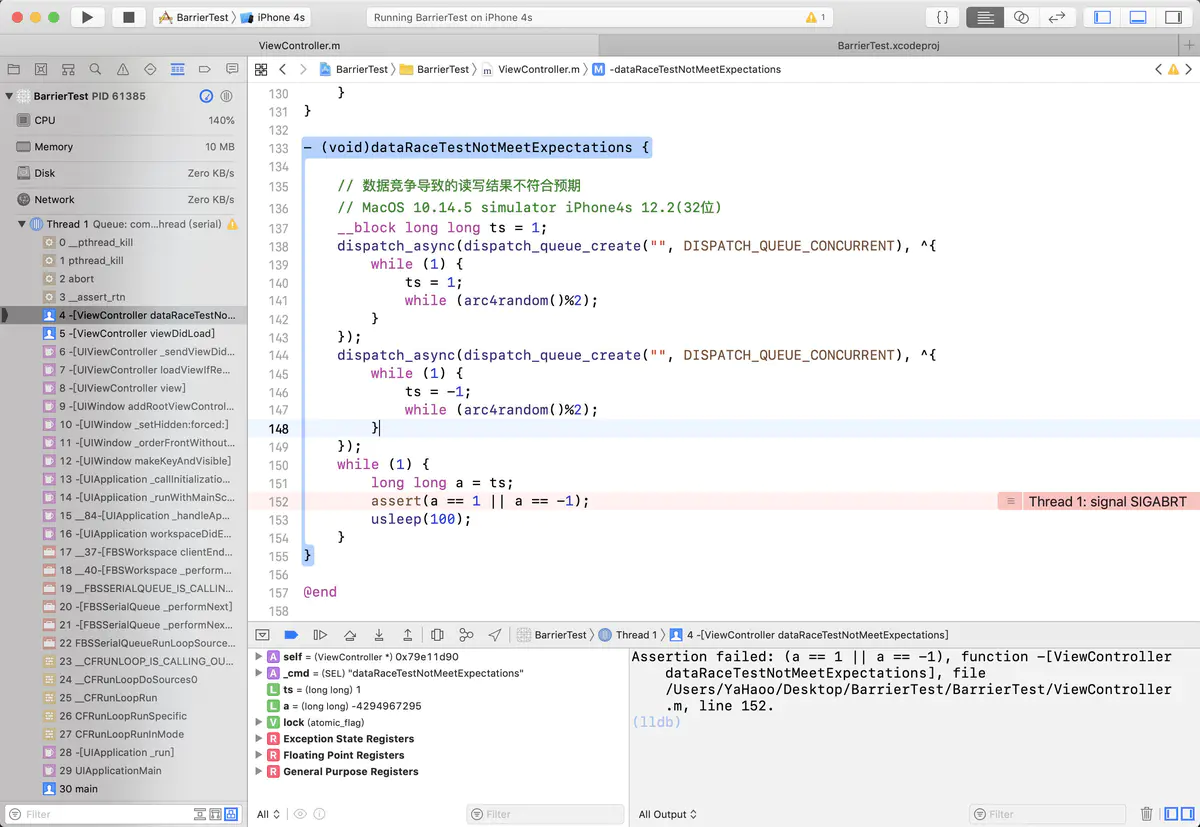
notMeetExpectations
发现a读到的是个-4294967295,我们对比下这几个值的二进制
1

binary1
-1

binary-1
-4294967295

binaryerro
很明显可以看到-4294967295是-1的高32位+1的低32位也就是ts变量被写了一半的结果。在64位机器上则没有问题,推测是64机器对于64位的读写是原子的中间没有中断,而32位机器则需要分两步完成。
这也提醒我们,对于基本数据类型变量的多线程读写并非是安全的,大部分情况下看起来没问题,但是并不代表没有问题,因为多线程的安全性与硬件与操作系统有太大的关系,标准的做法是使用原子库提供的原子类型变量,当我们对技术细节不是十分有把握的情况下,不要过分追求无锁编程,建议关键代码加锁处理。
3.dispatch_group存在的bug,至少在iOS11上dispatch_group是不安全的,目前测试发现iOS12上已经修复。
- (void)dispatchGroupTest {
// Test at iPhone 6s iOS 11.3
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t queue = dispatch_queue_create("queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_semaphore_t s1 = dispatch_semaphore_create(1);
dispatch_semaphore_t s2 = dispatch_semaphore_create(1);
for (long long i = 0; ; i++) {
__block atomic_int dd;
atomic_init(&dd, 0);
// Add task 1
dispatch_group_async(group, queue, ^{
while (arc4random()%100);
dispatch_semaphore_wait(s1, DISPATCH_TIME_FOREVER);
atomic_fetch_add_explicit(&dd, 1, memory_order_seq_cst);
dispatch_semaphore_signal(s1);
});
// Add task 2
dispatch_group_async(group, queue, ^{
while (arc4random()%100);
dispatch_semaphore_wait(s2, DISPATCH_TIME_FOREVER);
atomic_fetch_add_explicit(&dd, 1, memory_order_seq_cst);
dispatch_semaphore_signal(s2);
});
// Waiting for all tasks to be done.
dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
long long ddd = atomic_load_explicit(&dd, memory_order_seq_cst);
// Generally the two tasks did finished when the code ran here and "dd" should be 2. But after several million cycles, the following conditions can be met.
if (ddd != 2) {
// Call “dispatch_semaphore_wait” to block the thread of the task in the group which is not start, so that we can observe the details of thread call.
dispatch_semaphore_wait(s1, DISPATCH_TIME_FOREVER);
dispatch_semaphore_wait(s2, DISPATCH_TIME_FOREVER);
// I found that there is indeed a task in the group that has not been executed.
NSLog(@"loop: %lld", i);
assert(0);
}
}
}
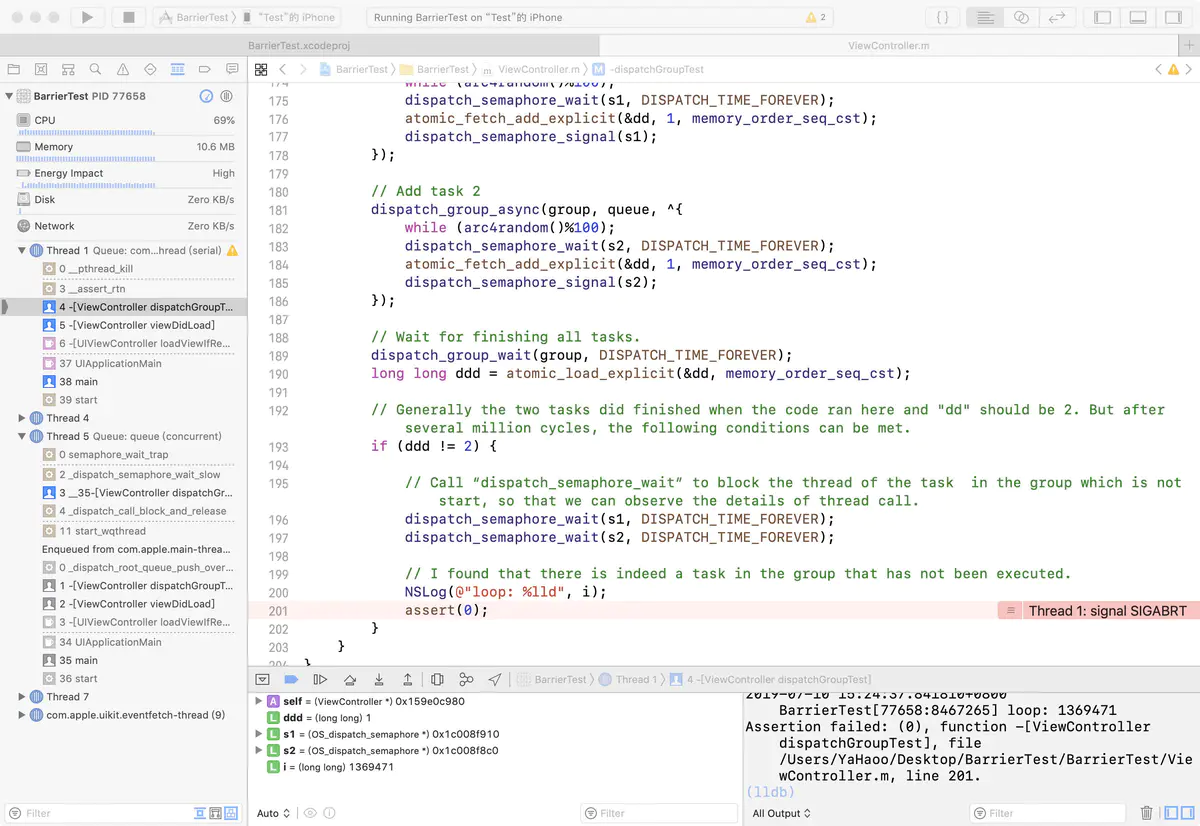
dispatchGroup
理论上来讲ddd一定会是2,但是在iPhone 6s iOS 11.3环境下,大概百万次循环后,跑出了1的结果。进入asset时,通过调用栈发现,另一个线程确实还没有完成任务。
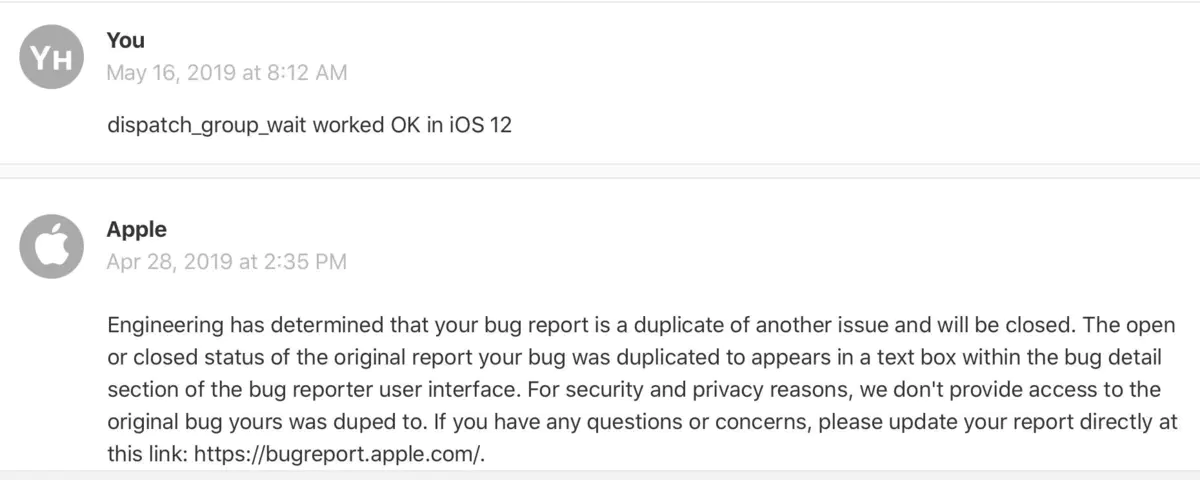
bugReport
目前得到苹果的回复是说该问题已经被报告过,并且已测试发现iOS12已经修复。
引用:
https://preshing.com/20120930/weak-vs-strong-memory-models/#strong
https://en.cppreference.com/w/cpp/atomic/memory_order#Release-Consume_ordering
https://preshing.com/20120913/acquire-and-release-semantics/

















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









