







 本文介绍了端侧AI的发展及其在AIoT场景的优势,重点关注了TensorFlowLite、Caffe2和CoreML这三个移动端常用的AI框架,探讨了它们在性能、集成成本和模型支持方面的比较,并提供了TensorFlowLite在移动应用中的实际使用案例和优化技巧。
本文介绍了端侧AI的发展及其在AIoT场景的优势,重点关注了TensorFlowLite、Caffe2和CoreML这三个移动端常用的AI框架,探讨了它们在性能、集成成本和模型支持方面的比较,并提供了TensorFlowLite在移动应用中的实际使用案例和优化技巧。
1. 端侧 AI 介绍
AI 技术的两大分支:云侧,端侧
1.1 云侧
从终端采集和感知到的信息,包括声音、视频、图像等数据都通过网络传输到云中心侧进行后续处理。云侧的资源高度集中,存储和计算能力超群,并且具有很高的通用性
但是随着 AIoT(人工智能物联网)设备和数据的指数级爆发式增长,云侧的集中式计算模型慢慢暴露出了一些不足,像信息处理的实时性,网络条件制约,数据安全性这三大缺陷开始显现。
常用框架:Caffe,Theano,MXNet,Torch
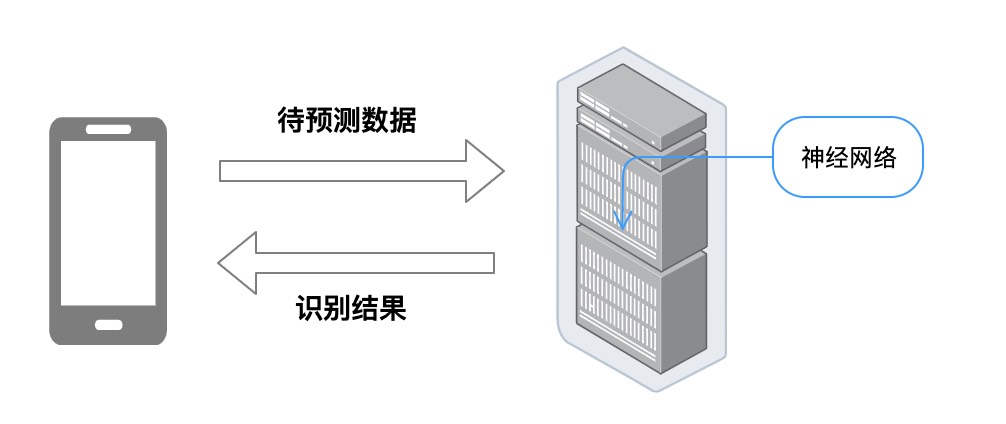
1.2 端侧
端侧也就是我们常说的边缘计算,这种模式可以更好的支持AIoT场景
端侧AI具有如下优点:
- AI 技术用于端侧可以第一时间对收集的数据进行处理,不需要通过网络上传到云侧的处理中心,极大加快了系统响应也减少了系统处理延迟;
- 端侧计算可以更高效的处理有价值的关键数据,其余的数据只是临时性的,在端侧结合 AI 能力,不仅可以更及时处理数据,而且减轻网络带宽的限制和缓解对中心侧数据存储的压力;
- 在端侧的 AI 技术可以高效地对用户的源数据进行处理,将一些敏感的数据进行清洗和保护,端侧设备只将 AI 处理后的结果上报云端。
常用框架:Caffe2、TensorFlow Lite、Core ML
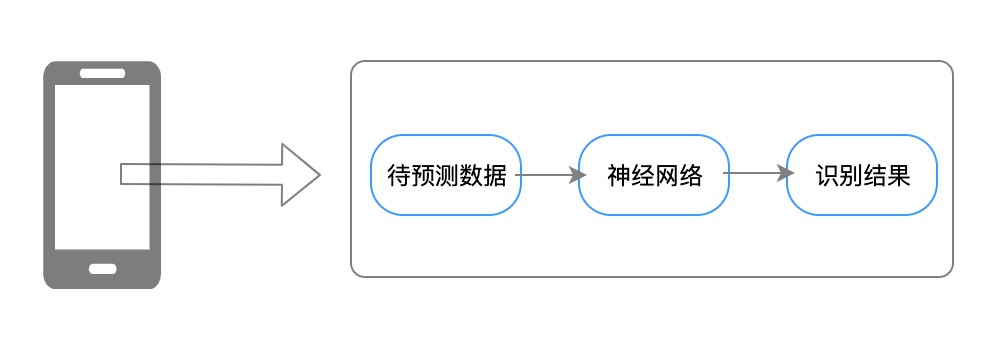
1.3 业内端侧 AI 案例
手淘千人千面:

支付宝扫福:

以及京东、快手等都有端侧 AI 的业务落地。
2. 常用的 AI 框架
这边主要介绍移动端常用的 AI 框架:TensorFlow Lite、Caffe2、Core ML,然在移动端上可使用的还有 Bender、MXNet、NCNN、MNN 等。
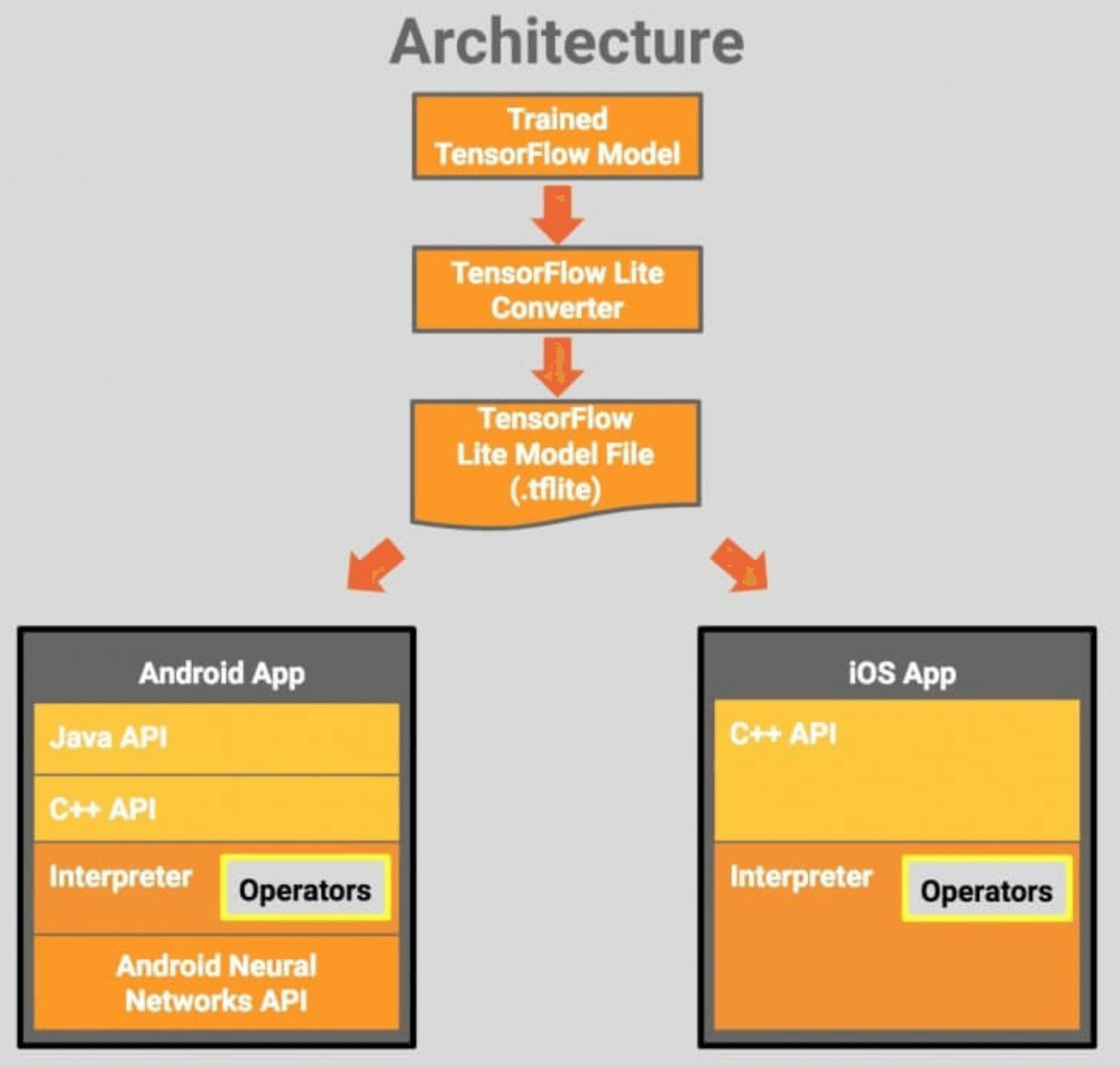
2.1 TensorFlow Lite (Google)

http://Tensorflow.org/mobile/tflite
谷歌于美国时间 2017 年 11 月 14 日正式发布 TensorFlow Lite 预览版,这一框架主要用于移动端和嵌入式设备,顾名思义,相较于 TensorFlow,TensorFlow Lite 是一个轻量化版本。这个开发框架专门为机器学习模型的低延迟推理做了优化,专注于更少的内存占用以及更快的运行速度。
TensorFlow Lite 具备以下三个重要功能:
- 轻量级:支持机器学习模型的推理在较小二进制数下进行,能快速初始化/启动
- 跨平台:可以在许多不同的平台上运行,现在支持 Android 和 iOS
- 快速:针对移动设备进行了优化,包括大大减少了模型加载时间、支持硬件加速
设计结构:
2.2 Caffe2 (Facebook)

http://Caffe2.ai/
2017 年 4 月 19 日 Facebook 发布了一款全新的开源深度学习框架—Caffe2,它最大的特点就是轻量、模块化和可扩展性,即一次编码,到处运行。说得更直白一点,就是 Caffe2 可以方便地为手机等移动终端设备带来 AI 加持,让 AI 从云端走向终端。
Caffe2 本来就是基于 caffe 开发的,Caffe 基于 C++ 开发,所以可以很自然地移植到移动端,目前 Caffe2 已经全部并入 Pytorch。两者的区别就是 PyTorch 是为研究而开发,更加灵活。Caffe2 是专为移动生产环境而开发,更加高效。
2.3 Core ML (Apple)

https://developer.apple.com/documentation/coreml
苹果在 2017WWDC 大会更新 iOS 11 时一并推出了面向开发者的全新机器学习框架——Core ML,声称能让本地数据处理愈加方便快捷。据介绍,Core ML 提供支持人脸追踪、人脸检测、地标、文本检测、条码识别、物体追踪、图像匹配等任务的 API。
Core ML 是一个基础机器学习框架,能用于众多苹果的产品,包括 Siri、相机和 QuickType。据官方介绍,Core ML 带来了极速的性能提升和机器学习模型的轻松整合,能将众多机器学习模型集成到 APP 中。它不但有 30 多种层来支持广泛的深度学习,而且还支持诸如树集成、SVM 和广义线性模型等标准模型。
对比:
| # | 集成成本 | 库文件大小 | 模型支持程度 | 速度 |
|---|---|---|---|---|
| Caffe2 | 一般 | 良好 | 优秀 | 一般 |
| TensorFlow Lite | 一般 | 良好 | 优秀 | 优秀 |
| NCNN | 优秀 | 优秀 | 良好 | 优秀 |
3. 初识 TensorFlow Lite
部落推荐帖子重排需求,server 端选择的训练输出的是 TensorFlow 模型,那么 Android、iOS 就需要使用 TensorFlow Lite。选择 TensorFlow Lite 我觉得是基于以下几点:
- 跨平台,双端都支持
- 模型大小,目前压缩后的模型大小为 5.6M,属于适中水平,当然需要采用动态下发的方式
- 框架大小,引入 TensorFlow Lite 会对包大小增加 3.2M,不过 58同城 App 之前已接入过 TensorFlow Lite
- 对移动设备做了大量的优化,同时支持硬件加速
- 流行程度
TensorFlow Lite 教程文档:
https://tensorflow.google.cn/lite/guide
3.1 创建 TensorFlow Lite 模型
你可以通过以下方式生成 TensorFlow Lite 模型:
- 使用现有的 TensorFlow Lite 模型:若要选择现有模型,请参阅 TensorFlow Lite 示例。模型可能包含元数据,也可能不含元数据。
- 创建 TensorFlow Lite 模型:使用 TensorFlow Lite Model Maker,利用您自己的自定义数据集创建模型。默认情况下,所有模型都包含元数据。
- 将 TensorFlow 模型转换为 TensorFlow Lite 模型:使用 TensorFlow Lite Converter 将 TensorFlow 模型转换为 TensorFlow Lite 模型。在转换过程中,你可以应用量化等优化措施,以缩减模型大小和缩短延时,并最大限度降低或完全避免准确率损失。默认情况下,所有模型都不含元数据。
3.2 运行推断
推断是指在设备上执行 TensorFlow Lite 模型,以便根据输入数据进行预测的过程。可以通过以下方式运行推断,具体取决于模型类型:
- 不含元数据的模型:使用 TensorFlow Lite Interpreter API。在多种平台和语言(如 Java、Swift、C++、Objective-C 和 Python)中均受支持。
- 包含元数据的模型:您可以使用 TensorFlow Lite Task 库以利用开箱即用的 API,也可以使用 TensorFlow Lite Support 库构建自定义的推断流水线。
3.3 输入输出介绍
移动应用开发者通常会与类型化的对象(如位图)或基元(如整数)进行交互。在设备端运行机器学习模型的 TensorFlow Lite 解释器使用的是 ByteBuffer 形式的张量 (Tensor)。
基于张量 (Tensor) 的输入与输出格式是一样的:
| 参数 | 说明 |
|---|---|
| index | 张量的索引 |
| name | 张量的名称 |
| DataType | FLOAT32, INT32, UINT8, INT64, STRING, BOOL, INT8 |
| shape | 张量的维度,类似二维数组的几行几列 |
| buffer | 输入或输出流 |
| QuantizationParams | 量化参数 |
3.4 运算符与选择运算符
TensorFlow Lite 已经内置了很多运算符,并且还在不断扩展,但是仍然还有一部分 TensorFlow 运算符没有被 TensorFlow Lite 原生支持。这些不被支持的运算符会给 TensorFlow Lite 的模型转换带来一些阻力。
所以 TensorFlow Lite 新增了一个支持 TensorFlow select 运算符的 Android AAR:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-with-select-tf-ops:0.1.100'
}
性能
如果 TensorFlow Lite 模型是同时混合使用内置运算符和 TensorFlow select 运算符进行转换的,那么模型依然可以使用针对 TensorFlow Lite 的优化以及内置的优化内核。
下表列出了在 Pixel 2 上 MobileNet 的平均推断时间。表中的时间是 100 次运行的平均时间。
| 编译 | 推断时间 (milliseconds) |
|---|---|
| Only built-in ops (TFLITE_BUILTIN) | 260.7 |
| Using only TF ops (SELECT_TF_OPS) | 264.5 |
二进制文件大小
| 编译 | C++ 二进制文件大小 | Android APK 大小 |
|---|---|---|
| Only built-in ops | 796 KB | 561 KB |
| Built-in ops + TF ops | 23.0 MB | 8.0 MB |

















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









