







关键词
Memory Networks,CBT dataset
来源
arXiv 2015.11.07 (published at ICLR 2016)
问题
探索统计模型如何利用更广的上下文来做预测
文章思路
Memories 和 Queries 表示 考虑三种形式:
- Lexical Memory 在 document 中每个词的 one-hot representation 代表一个 memory,并且将时间特征加入 embedding 中以反应位置信息。在 query 中 memory 采用要预测的词前 n 个词来表示。
- Window Memory 在 document 中以候选答案为中心开一个窗口,用这个窗口内的词表示 memory。实验中采用了 bag of words 和 每个 window 采用一个字典的方式编码,后者效果更好。在 query 中采用以要预测的词开一个窗口。
- Sentential Memory: 在 document 中每个句子对应一个 memory。同时使用 End-To-End Memory Networks 提出的 Positional Encoding 来对词的位置进行编码。在 query 中采用整个句子的 bag of words。
答案预测 利用上面提到的几种 memeory,将相关工作中的 End-To-End Memory Networks 相应的 memeory 做替换,可以得出答案。
self-supervision for window memories 在实验中发现,多跳网络只在 Lexical Memory 中起作用。于是尝试使用更简单的,单跳网络(答案只使用一个 memory)来利用更强的信息来学习。
Memory supervision 用以下方式推断:因为在训练时知道正确的答案,我们假设在 window memory 中正确的 support memory 所对应的候选答案就是正确的。通常不止一个 memory 包含正确的答案,模型自己通过 query 计算后选择得分最高的那一个答案。
资源
论文地址:https://arxiv.org/abs/1511.02301
数据地址:http://fb.ai/babi/
相关工作
数据集构造 文中构造了 CBT 这样一个数据集,其中的数据均来自 Project Gutenberg,使用了其中的与孩子们相关的故事,这是为了保证故事叙述结构的清晰,从而使得上下文的作用更加突出。选用文章中连续的 21 句话,前 20 句作为document,将第 21 句中去掉一个词之后作为 query,被去掉的词作为 answer,并且给定10个候选答案,每个候选答案是从document 和 query 中随机选取的相同词性的词。并且提供四类评测:Named Entities, Common Nouns, Verbs and Prepositions.
End-To-End Memory Networks 在单层模型中模型将 document 中的每一个 word 保存为一个 memory m(i),每个memory 本质上就是一个向量,这一点与 embedding 是一回事,只是换了一个名词。另外每个 word 还与一个输出向量 c(i)相关联。可以理解为每个 word 表示为两组不同的 embedding A 和 C。同样的道理,query 中的每个单词可以用一个向量来表示,即对应着另一个 embedding B。
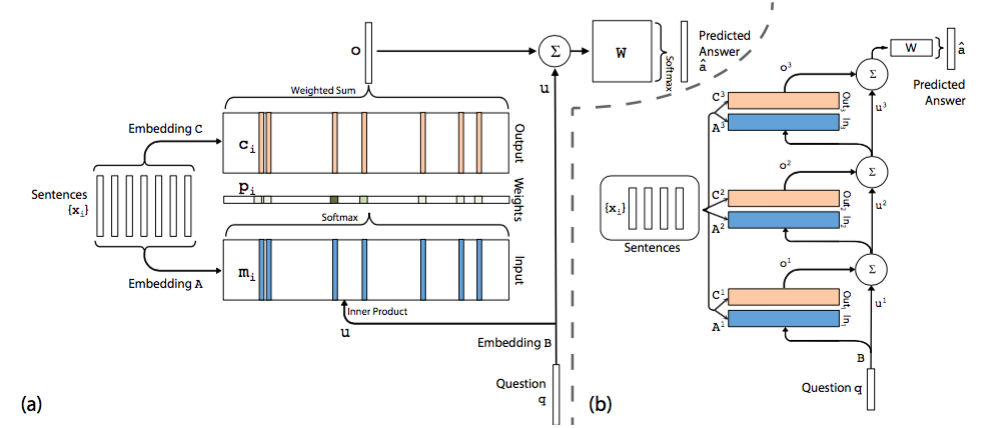
在 Input memory 表示层,用 query 向量与 document 中每个单词的 m(i) 作内积,再用 softmax 归一化得到一组权重,这组权重就是 attention,即 query 与 document 中每个 word 的相关度。
接下来,将权重与 document 中的另一组 embedding c(i) 作加权平均得到 Output memory 的表示。这一步也称作 support memory。
最后,利用 query 的表示和 output memory 的表示去预测answer。
根据单层模型的结构,非常容易构造出多层模型。每一层的 query 表示等于上一层 query 表示与上一层输出 memory 表示的和。每一层中的 A 和 C embedding 有两种模式,第一种是邻接,即 A(k+1) = C(k),依次递推;第二种是类似于 RNN 中共享权重的模式,A(1) = A(2) = … = A(k),C(1) = C(2) = … = C(k)。其他的过程均和单层模型无异。
简评
实验说明传统的 N-gram 方法和 LSTM RNNLM 从 query本身出发就可以非常准确地预测出 Verbs 和 Preposition,不需要借助过多的 document context,但是对于前两类却束手无策。因此本文提出了用Memory Network来解决这个问题。
但是并不是所有的 Memory Network 都起作用,实验结果表明 以候选答案为中心的 window memory 表现最好。而 window memory 加上 self-supervision (在训练时利用 max 函数而不是加权平均做 hard attention selection) 在 Named Entities, Common Nouns 表现突出。
另外,Memory Networks 最大的特点是能够扩展成多跳,这可以提供推理能力。















 2417
2417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









