







关键词
hierarchical recurrent neural network
来源
arXiv 2016.06.02
问题
已有的 end2end 网络来做对话生成任务,存在着不能够把对话上下文考虑进去生成有意义的相应,这也就是说模型没有学到有用的高阶抽象表示。同时对于长距离的依赖也把握地不好,所以针对这些问题,本文提出了主动构造句子的高阶表示,利用 HRED 来做这一任务。
文章思路
本文模型中一个非常重要的假设是对话序列存在 high-level 的 coarse sequence representation 信息,将这种信息提取出来构造层次结构。构造 Coarse Sequence Representation 尝试了两种做法。
Noun Representation,就是提取文本中的名词。这是基于对话是话题导向的,而话题可以用名词来表示。用词性标注工具提取出文本中的名词,去掉停用词和重复的词,并且保持原始的词序,还添加了句子的时态。通过这个过程构造了一种表示原始文本的序列。
Activity-Entity Representation,提取文本中的动词和命名实体。这是针对 Ubuntu 语料的,这一语料需要抽取出与技术问题相关的领域知识。用词性标注工具提取文本中的动词,并标记为activity,然后从所有训练数据中构造了一个命名实体的词典,帮助提取原句中的命名实体。因为数据集是 ubuntu 对话数据集,会涉及到大量的 linux 命令,所以还构造了一个 linux 命令词典,以标记原句中的命令。同样地也添加了句子的时态。通过这个处理过程,构造了另外一种表示原始文本的序列。
两种处理方法将原句用一种关键词的形式表示出来,尤其是第二种方法针对 Ubuntu 数据集的特点,包含了非常多的特征进来。这样的表示本文称为 coarse sequence representation,包含了 high-level 的信息,比起单纯的 word by word sequence 具有更加丰富的意义。
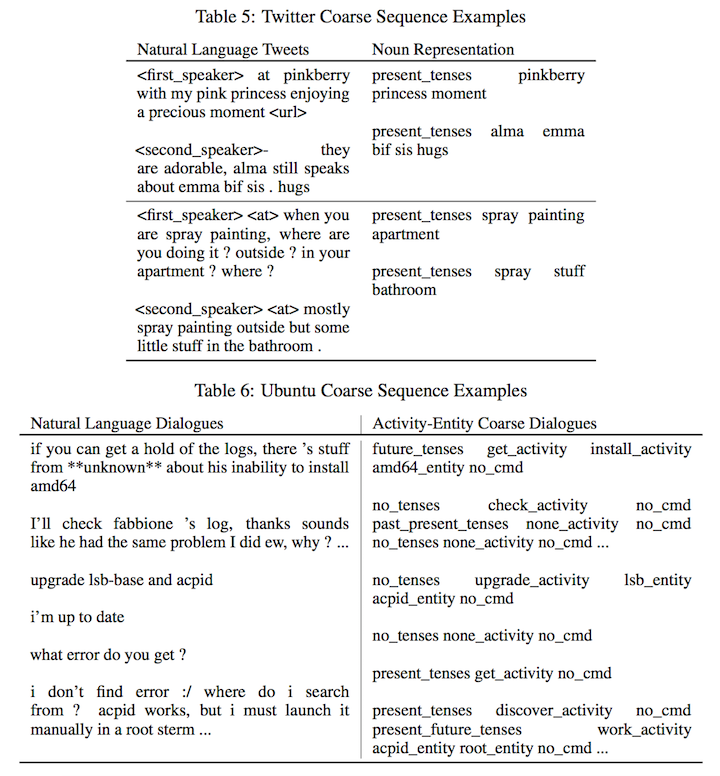
模型将对话语料构造成层次结构 high-level abstract sequence (Coarse Representation) 和 low-level sequence (Natural Language Representation),然后将高层次的信息编码到低层次中,帮助生成有效的相应。模型如下图
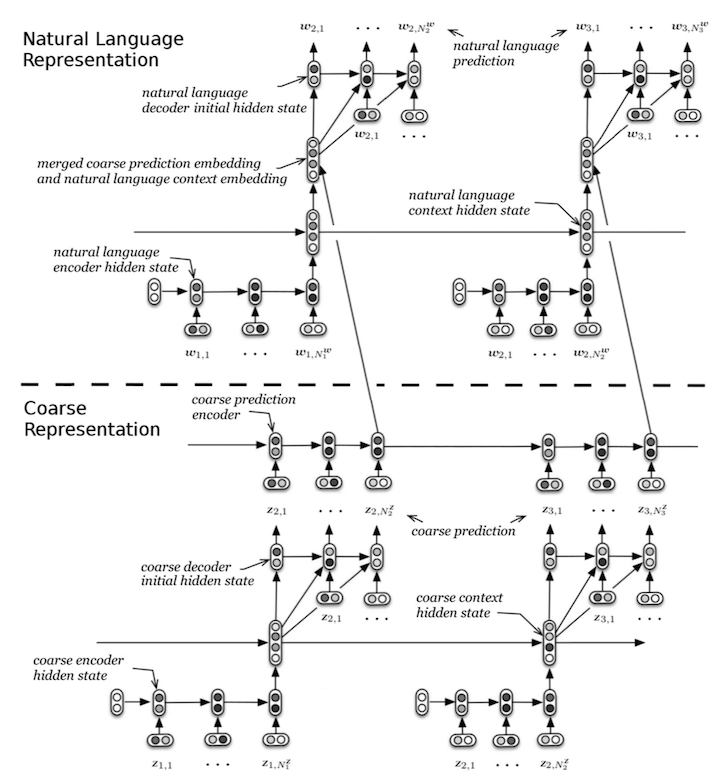
训练目标采用 high-levle 和 low-level 的联合概率:
不管是用自动评价指标还是人工评价,结果都表明了本文的模型效果比 baseline 要高出很多个百分点,远远好于其他模型。下面展示一个结果,是ubuntu数据集上的测试效果:

可以看的出本文模型生成的结果效果比其他模型好很多。
资源
论文地址:http://cn.arxiv.org/abs/1606.00776v2
数据及地址:
- Twitter http://www.iulianserban.com/Files/TwitterDialogueCorpus.zip
- Ubuntu http://cs.mcgill.ca/~jpineau/datasets/ubuntu-corpus-1.0/
相关工作
-
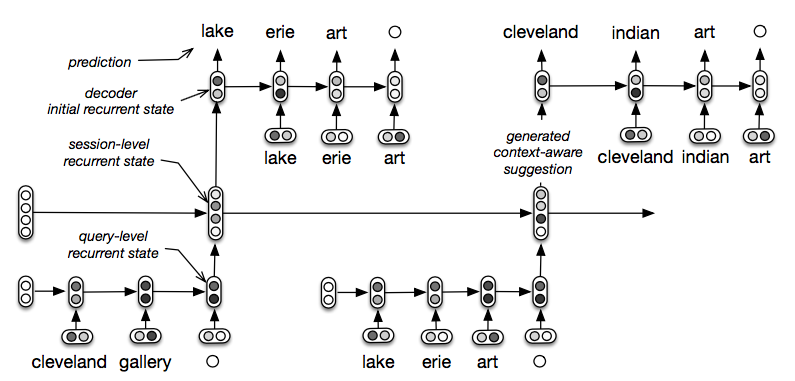
Hierarchical Recurrent Encoder-Decoder
-
分成三个模块,这篇论文主要是说信息检索的,以检索为例:
- encoder RNN 负责将词的序列编码成一个向量(一次查询中词)
- context RNN 将上面产生的向量作为输入更新隐层状态,反应此时的全局信息。(query 序列)
- decoder RNN 在 context RNN 的条件下解码生成一个词序列。
HRED 模型适合对结构化离散序列编码的几个原因:
- 很自然地捕捉到我们想要建模的序列的层次结构
- context RNN 就像 memory 一样可以记住长距离信息
- 这种结构使得关于模型参数的目标函数更加稳定,帮助传播对于优化方法来说最重要的训练信号
简评
本文模型并不是一个纯粹的数据驱动的模型,在初始的阶段需要做一些非常重要的数据预处理,正是这个预处理得到的序列表示给本文的好结果带来了保证。















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









