







关键词
real natural language traning data, nerual model
来源
arXiv 2015.06.10 (published at NIPS 2015)
问题
针对阅读理解缺乏大规模训练数据集,构建了相应的数据集。同时尝试利用神经网络模型解决机器阅读理解问题。
文章思路
文章中提出了三种神经网络模型,分别如下:
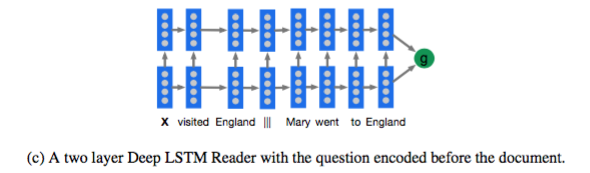
Deep LSTM
其实就是用一个两层 LSTM 来 encode query||document 或者document||query,然后用得到的表示做后续工作。
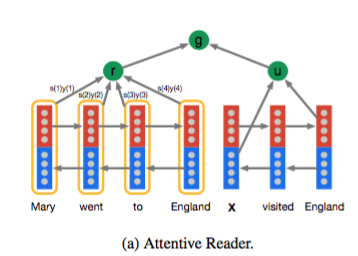
Attentive Reader
这一模型分别计算 document 和 query,然后通过一个额外的前馈网络把他们组合起来。
document 部分利用双向 LSTM 来 encode,每个 token 都是由前向后向的隐层状态拼接而成,而 document 则是利用其中所有 token 的加权平均表示的,这里的权重就是 attention,利用 query 部分就是将双向 LSTM 的两个方向的最终状态拼接表示而来。
最后利用 document 和 query 做后续工作。
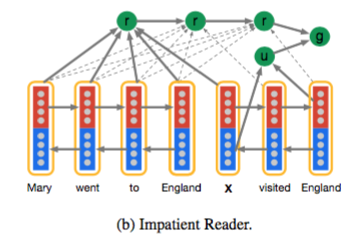
Impatient Reader
这一模型和 attentive reader 类似,但是每读入一个 query token 就迭代计算一次 document 的权重分布。
最终的结果,在 CNN 语料中,第三种模型 Impatient Reader 最优,Attentive Reader 效果和 Impatient Reader 差不太多。在 Daily Mail 语料中,Attentive Reader 最优。
资源
论文地址:https://arxiv.org/abs/1506.03340
数据集地址:https://github.com/deepmind/rc-data
相关工作
文章借鉴了自动文摘任务,将新闻文本作为 document,将相对应的摘要作为 query。同时为了防止只根据 query 上下文就推断出答案而不需要阅读的问题,将实体匿名化并重新排列,最终结果如下:

简评
文章提供一个比较大的数据集,并且指出 CNN 语料要比 Daily Mail 阅读理解难度要低一些。同时给了三个 baseline 神经网络模型。















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









