







关键词
reading comprehension, gated attention, GRU
来源
arXiv 2016.06.05
问题
对于机器阅读理解的进步,可以采用 cloze-questions (类似于完形填空)的方法去进行评测。本文探索了用 deep learning 的方法探索更好的理解方法。
文章思路
这篇论文提出了如下图的 Gated-Attention Reader。每个标有Bi-GRU 字样的方块表示双向 GRU,从图中可以看出,一共运用了 K 层网络。
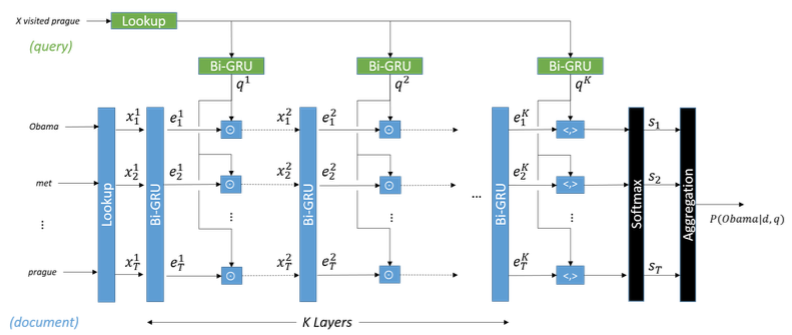
问题表示 每一层上,query 都是用前向和后向的 GRU 的 last hidden state 连接在一起来表示的。图中绿色方块表示对 query 进行编码的 GRU。
文档表示 对于 document,第一层双向 GRU 的输入是由文档中词向量构成。之后的层利用 Gated-Attention 机制,将文档中每个词的经过双向 GRU 处理输出的向量与 query 做 element-wise 乘法(也叫 Hadamard product)构成下一层网络的输入。图中蓝色方块表示对 query 进行编码的 GRU。
答案求解 将网络最后一层输出向量与问题向量做 inner product,然后把结果送到 soft-max 层得到概率值。最后将相同单词的概率值相加,也就是图中的 Aggregation 方块。(这里包含了一个假设,也就是出现次数越多的单词越可能成为答案,实验证明,这一假设基本成立。)
资源
论文地址:http://cn.arxiv.org/abs/1606.01549v1
相关工作
本文的工作主要借鉴了 Attention Sum (AS) Reader 和 Memory Networks。当网络的层数 K 变成 1 时,GA Reader 就和 AS reader 一样。
文中利用了 AS Reader 中的 pointer sum attention 机制来获得答案的分布,与此同时利用 Memory Networks 在多跳网络上可以进行推理的特性来设计网络。
简评
本文最大的贡献是提出了一个新的 attention 机制,以往的 attention 主要是对网络输出进行加权平均(权重是由文档和问题之间的 dot product 得到的),而本文中的 attention 是用文档和问题之间的 hadamard product 得到的的。
对于回答 cloze-questions ,文中提到只需要重视和问题有关的那一部分就可以找到答案,而 attention 机制恰好能满足这一点。另外,为了达到选择性重视文档中部分内容的效果,故而采取 gated 机制。
由此可以看出,attention 机制是与任务相关的,如何根据任务设计更好的 attention 是一个问题。















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









