







部分内容参考https://blog.csdn.net/Koala_Tree/article/details/78045596
二分类
输入x 是每个像素的RGB值,维数是64* 64 * 3
想要的输出是 y 0,1
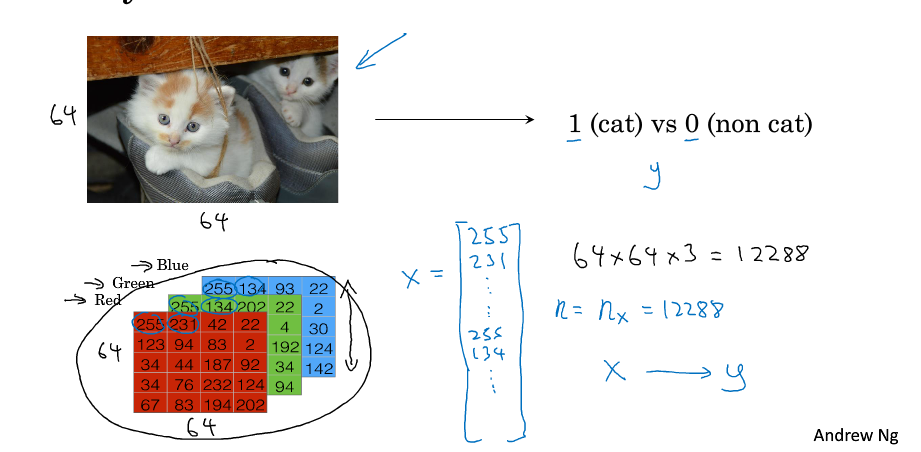
m 样本的数量
n 表示特征的数量
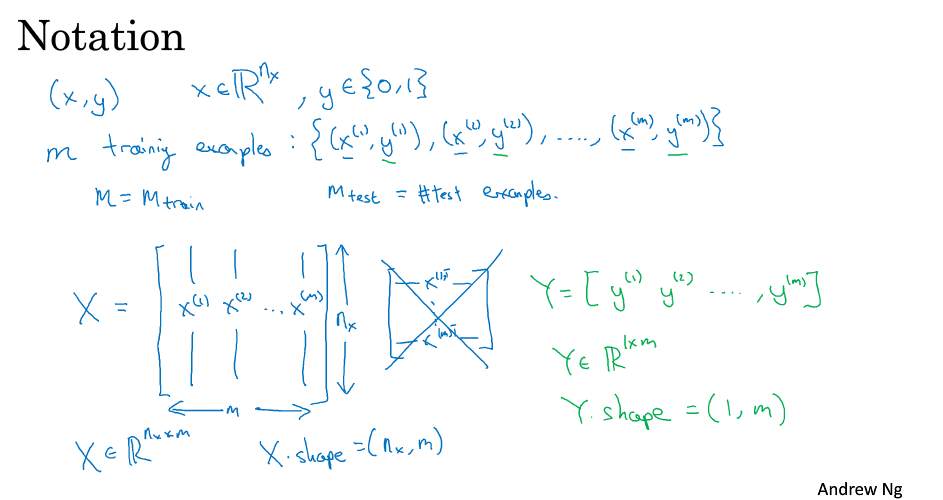
logistic 回归
逻辑回归的预测值在[0,1]之间,表示为1的概率
所以需要引入Sigmod函数
y
^
=
S
i
g
m
o
i
d
(
w
T
x
+
b
)
=
σ
(
w
T
x
+
b
)
\hat y = Sigmoid(w^{T}x+b)=\sigma(w^{T}x+b)
y^=Sigmoid(wTx+b)=σ(wTx+b)
logistic 回归损失函数
逻辑回归Loss Function
L
(
y
^
,
y
)
=
−
(
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
)
L(\hat y, y)=-(y\log\hat y+(1-y)\log(1-\hat y))
L(y^,y)=−(ylogy^+(1−y)log(1−y^))
逻辑回归 Cost Function
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
y
^
(
i
)
,
y
(
i
)
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
log
y
^
(
i
)
+
(
1
−
y
(
i
)
)
log
(
1
−
y
^
(
i
)
)
]
J(w,b)=\dfrac{1}{m}\sum_{i=1}^{m}L(\hat y^{(i)}, y^{(i)})=-\dfrac{1}{m}\sum_{i=1}^{m}\left[y^{(i)}\log\hat y^{(i)}+(1-y^{(i)})\log(1-\hat y^{(i)})\right]
J(w,b)=m1i=1∑mL(y^(i),y(i))=−m1i=1∑m[y(i)logy^(i)+(1−y(i))log(1−y^(i))]

梯度下降法
梯度下降是为了找到是的损失函数最小的w、b
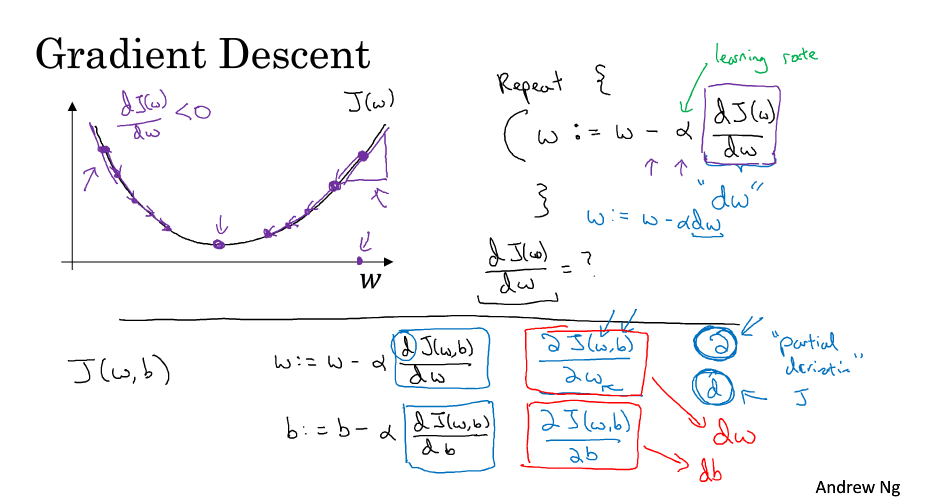
计算图

计算图计算梯度
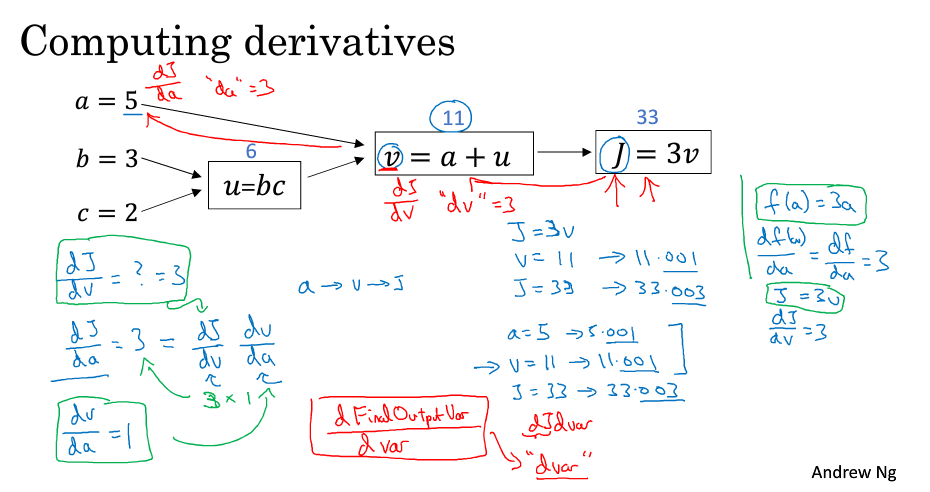
逻辑回归中的梯度下降
d
a
=
∂
L
∂
a
=
−
y
a
+
1
−
y
1
−
a
da = \dfrac{\partial L}{\partial a}=-\dfrac{y}{a}+\dfrac{1-y}{1-a}
da=∂a∂L=−ay+1−a1−y
d
z
=
∂
L
∂
z
=
∂
L
∂
a
⋅
∂
a
∂
z
=
(
−
y
a
+
1
−
y
1
−
a
)
⋅
a
(
1
−
a
)
=
a
−
y
dz = \dfrac{\partial L}{\partial z}=\dfrac{\partial L}{\partial a}\cdot\dfrac{\partial a}{\partial z}=(-\dfrac{y}{a}+\dfrac{1-y}{1-a})\cdot a(1-a)=a-y
dz=∂z∂L=∂a∂L⋅∂z∂a=(−ay+1−a1−y)⋅a(1−a)=a−y
d
w
1
=
∂
L
∂
w
1
=
∂
L
∂
z
⋅
∂
z
∂
w
1
=
x
1
⋅
d
z
=
x
1
(
a
−
y
)
dw_{1} = \dfrac{\partial L}{\partial w_{1}}=\dfrac{\partial L}{\partial z}\cdot\dfrac{\partial z}{\partial w_{1}}=x_{1}\cdot dz=x_{1}(a-y)
dw1=∂w1∂L=∂z∂L⋅∂w1∂z=x1⋅dz=x1(a−y)
d
b
=
∂
L
∂
b
=
∂
L
∂
z
⋅
∂
z
∂
b
=
1
⋅
d
z
=
a
−
y
db = \dfrac{\partial L}{\partial b }=\dfrac{\partial L}{\partial z}\cdot\dfrac{\partial z}{\partial b }=1\cdot dz=a-y
db=∂b∂L=∂z∂L⋅∂b∂z=1⋅dz=a−y

m个样本的梯度下降


向量化
深度学习中,应该避免使用for循环,而使用向量化,提高程序运行速度

a=np.random.rand(1000000)
b=np.random.rand(1000000)
%time c=np.dot(a,b)
Out:
Wall time: 1.01 ms
%%time
c=0
for i in range(1000000):
c +=a[i]*b[i]
Out:
Wall time: 381 ms
向量化逻辑回归
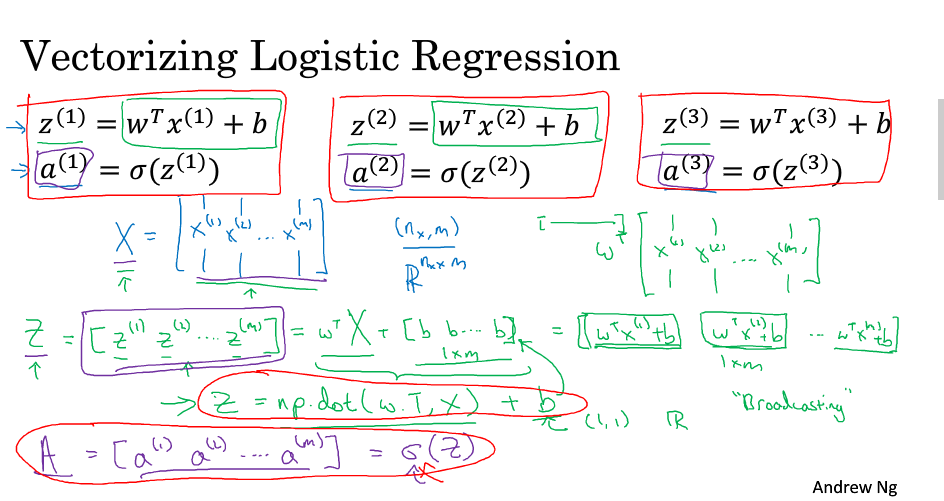
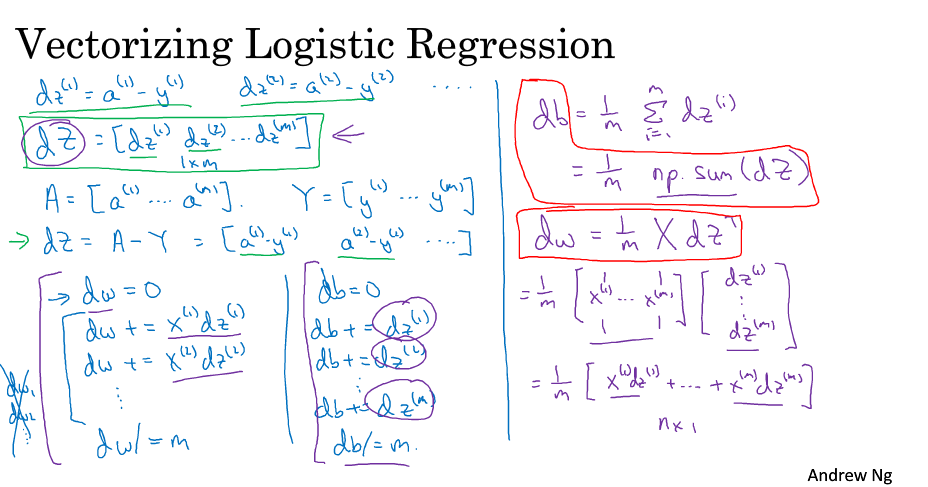

提示:在numpy进行矩阵操作时,可以使用assert语句进行判断,已检查语句的正确性
logistic损失函数
y
^
=
σ
(
w
T
x
+
b
)
σ
(
z
)
=
1
1
+
e
−
z
\hat y =\sigma(w^{T}x+b) \\\sigma(z)=\dfrac{1}{1+e^{-z}}
y^=σ(wTx+b)σ(z)=1+e−z1
y
^
\hat y
y^可以看做y=1的概率
当y=1时
P
(
y
∣
x
)
=
y
^
P(y|x)=\hat y
P(y∣x)=y^
当y=0是
P
(
y
∣
x
)
=
1
−
y
^
P(y|x)=1-\hat y
P(y∣x)=1−y^
即
P
(
y
∣
x
)
=
y
^
y
(
1
−
y
^
)
(
1
−
y
)
P(y|x)=\hat y^{y}(1-\hat y )^{(1-y)}
P(y∣x)=y^y(1−y^)(1−y)
log
P
(
y
∣
x
)
=
log
[
y
^
y
(
1
−
y
^
)
(
1
−
y
)
]
=
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
\log P(y|x)=\log\left[\hat y^{y}(1-\hat y )^{(1-y)}\right]=y\log\hat y+(1-y)\log(1-\hat y)
logP(y∣x)=log[y^y(1−y^)(1−y)]=ylogy^+(1−y)log(1−y^)

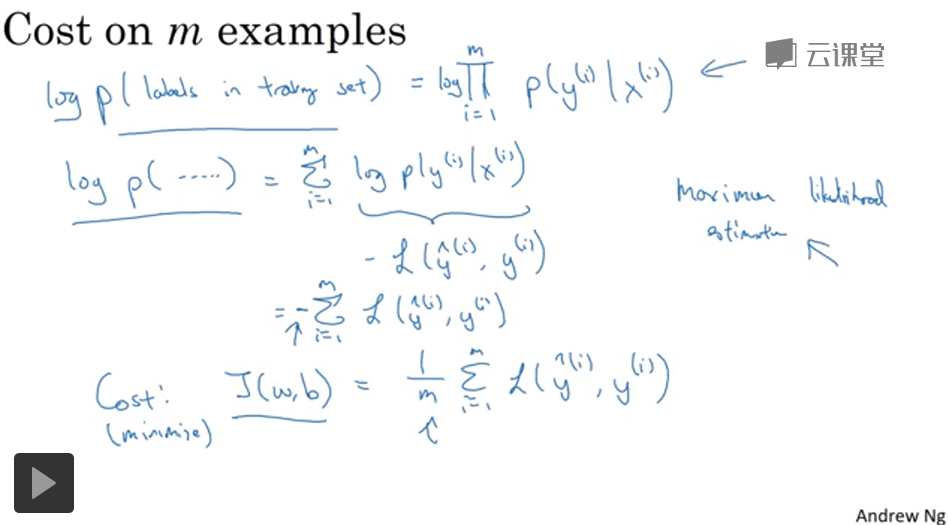















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









