






1.fp32、fp16、bf16是谁发明的?有什么差别和联系?
fp32、fp16、bf16分别称为单精度浮点数、半精度浮点数、半精度浮点数,其中fp16是intel提出的,bf16是nvidia提出的,fp16和bf16所占存储空间是fp32的一半。
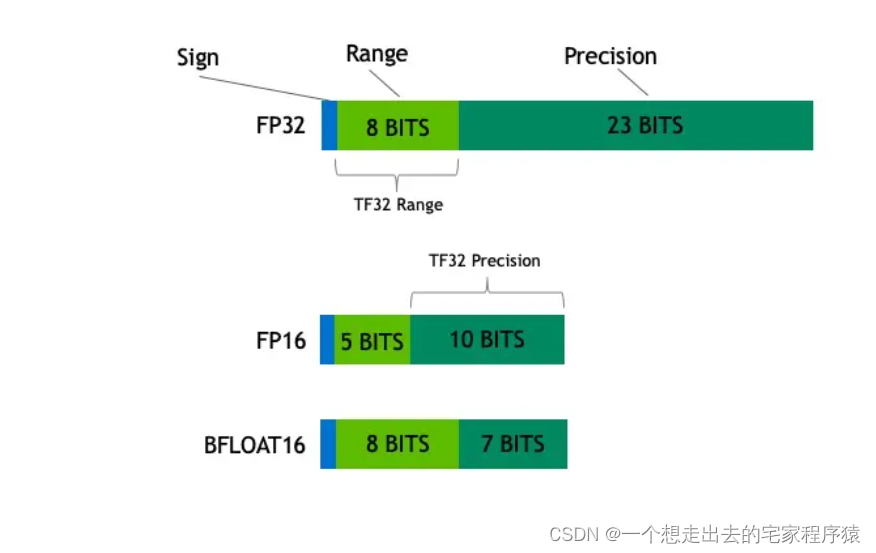
2.三者的数据范围是什么?
fp16的动态范围是5.96E−8~ 65504,bf16的动态范围是9.2E−41~3.38E38,fp32的动态范围是1.4E-45 ~ 3.40E38,可以看出bf16的数值范围几乎和fp32的范围一样大,这样可以避免fp16容易上、下溢的问题。但是其损失了精度,因为它有8个指数位、尾数位只有7位,而fp16有5个指数位,10个尾数位(也叫小数位)。
3.混合精度是什么?为什么会出现?
最好的是采用fp32单精度,但电脑性能有限,完全采用半精度会出现数据溢出和舍入误差的问题,因此引入了混合精度。
数据溢出这里不再详述,主要讲一下舍入误差。上述三种数据类型的间隔单位即计算的最小正值是不一样的,间隔单位的大小取决于一个小值是否被舍弃,如表达一个数值+1.4E-45,采用fp32,这个小值会被看到,但是bf16,由于其间隔单位是9.2E−41,这个小值就会被舍弃。
那么什么是混合精度呢?就是通过一些设计,使得我们可以享受半精度的优点,又可以避免上述的问题。
这种方法主要是用于解决舍入误差的问题。我们使用 fp32 权重作为精确的 “主权重 (master weight)”进行备份,而其他所有值(weights,activations, gradients)均使用 fp16 进行计算以提高训练速度,最后在梯度更新阶段再使用半精度的梯度更新单精度的主权重,这样当很小的梯度*学习率后要跟权重(fp32的)做运算时,就不会被舍弃了。
由于 fp16 混合精度大大减少了内存需求, 并可以实现更快的速度, 因此只有在在此训练模式下表现不佳时, 才考虑不使用混合精度训练。 通常, 当模型未在 fp16 混合精度中进行预训练时, 会出现这种情况。 这样的模型可能会溢出, 导致loss为NaN。 如果是这种情况, 使用完整的 fp32 模式。

















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









