







 OpenDiT作为开源项目,通过高性能的DiffusionTransformer提升文本到视频和图像生成效率,提供80%的训练速度提升和50%的内存消耗减少。它的开放态度推动了技术进步和小企业开发,形成良性循环。
OpenDiT作为开源项目,通过高性能的DiffusionTransformer提升文本到视频和图像生成效率,提供80%的训练速度提升和50%的内存消耗减少。它的开放态度推动了技术进步和小企业开发,形成良性循环。
Sora有了开源平替文生视频和图生视频:OpenDiT!作为一个开源项目,通过其高性能的Diffusion Transformer(DiT)实现,为文本到视频或文本到图像的生成应用带来了革命性的提升。

Sora有了开源平替:OpenDiT!作为一个开源项目,通过其高性能的Diffusion Transformer(DiT)实现,为文本到视频或文本到图像的生成应用带来了革命性的提升。相较于传统的生成方法,OpenDiT显著提高了训练速度,减少了内存消耗和通信量,为开发者和用户带来了实质性的好处。
• 训练速度提升80%
• 内存减少50%
• 通讯量减少50%以上
当前开源的力量越来越大了,OpenDiT作为一个开源项目,其重要性不仅仅体现在技术层面。虽然可能该开源项目无法和Sora进行对标,但是这种开放的态度不仅加速了技术的发展,也使得小型企业和个人开发者能够站在巨人的肩膀上,利用最前沿的技术解决实际问题。此外,开源社区的反馈和贡献进一步促进了OpenDiT的改进和优化,形成了一个良性的发展循环。

Installation
Prerequisites:
- Python >= 3.10
- PyTorch >= 1.13 (We recommend to use a >2.0 version)
- CUDA >= 11.6
We strongly recommend using Anaconda to create a new environment (Python >= 3.10) to run our examples:
conda create -n opendit python=3.10 -y
conda activate opendit
Install ColossalAI:
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
git checkout adae123df3badfb15d044bd416f0cf29f250bc86
pip install -e .
Install OpenDiT:
git clone https://github.com/oahzxl/OpenDiT
cd OpenDiT
pip install -e .
(Optional but recommended) Install libraries for training & inference speed up (you can run our code without these libraries):
# Install Triton for fused adaln kernel
pip install triton
# Install FlashAttention
pip install flash-attn
# Install apex for fused layernorm kernel
git clone https://github.com/NVIDIA/apex.git
cd apex
git checkout 741bdf50825a97664db08574981962d66436d16a
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./ --global-option="--cuda_ext" --global-option="--cpp_ext"
Usage
OpenDiT fully supports the following models, including training and inference, which align with the original methods. Through our novel techniques, we enable these models to run faster and consume less memory. Here’s how you can use them:
| Model | Source | Function | Usage | Optimize |
|---|---|---|---|---|
| DiT | https://github.com/facebookresearch/DiT | label-to-image | Usage | ✅ |
| OpenSora | https://github.com/hpcaitech/Open-Sora | text-to-video | Usage | ✅ |
Technique Overview
DSP [paper][doc]
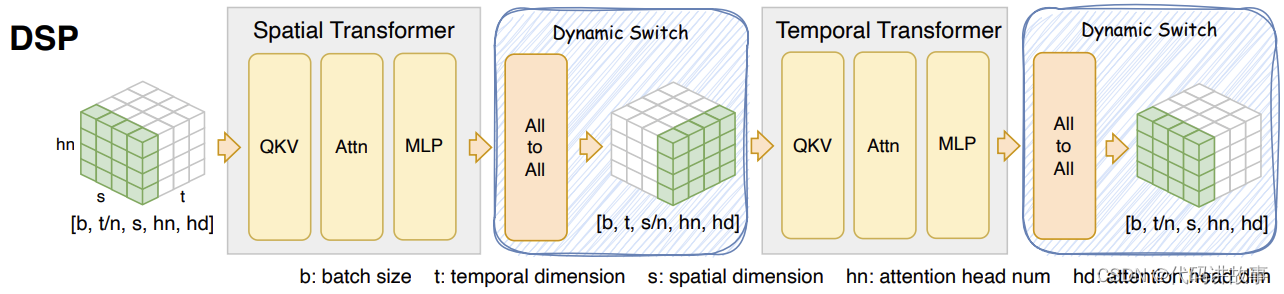
DSP (Dynamic Sequence Parallelism) is a novel, elegant and super efficient sequence parallelism for OpenSora, Latte and other multi-dimensional transformer architecture.
It achieves 3x speed for training and 2x speed for inference in OpenSora compared with sota sequence parallelism (DeepSpeed Ulysses). For a 10s (80 frames) of 512x512 video, the inference latency of OpenSora is:
| Method | 1xH800 | 8xH800 (DS Ulysses) | 8xH800 (DSP) |
|---|---|---|---|
| Latency(s) | 106 | 45 | 22 |
See its detail and usage here.
FastSeq [doc]
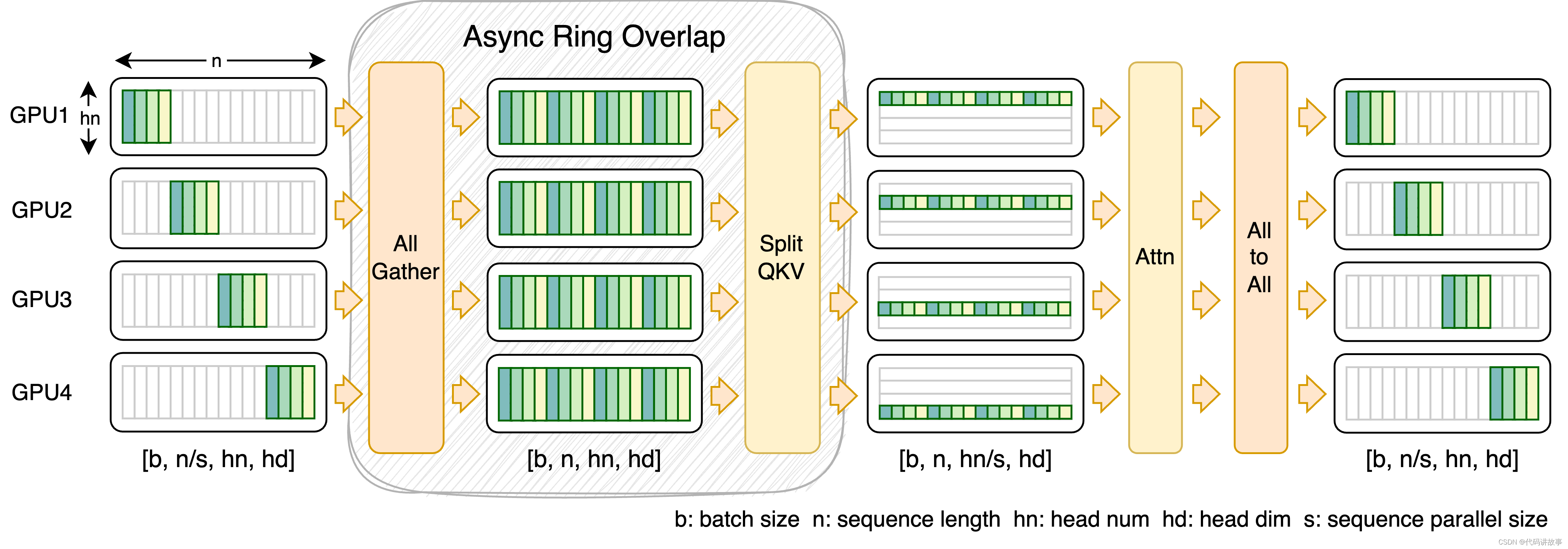
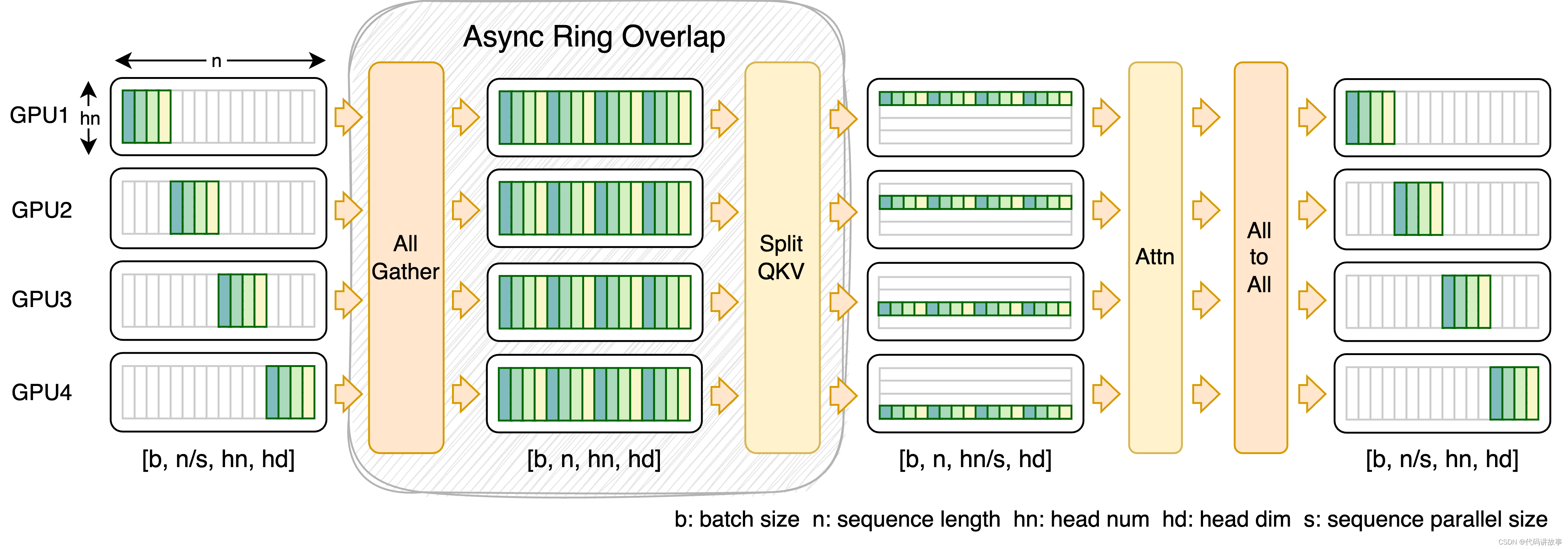
FastSeq is a novel sequence parallelism for large sequences and small-scale parallelism.
It focuses on minimizing sequence communication by employing only two communication operators for every transformer layer, and we an async ring to overlap AllGather communication with qkv computation. See its detail and usage here.
DiT Reproduction Result
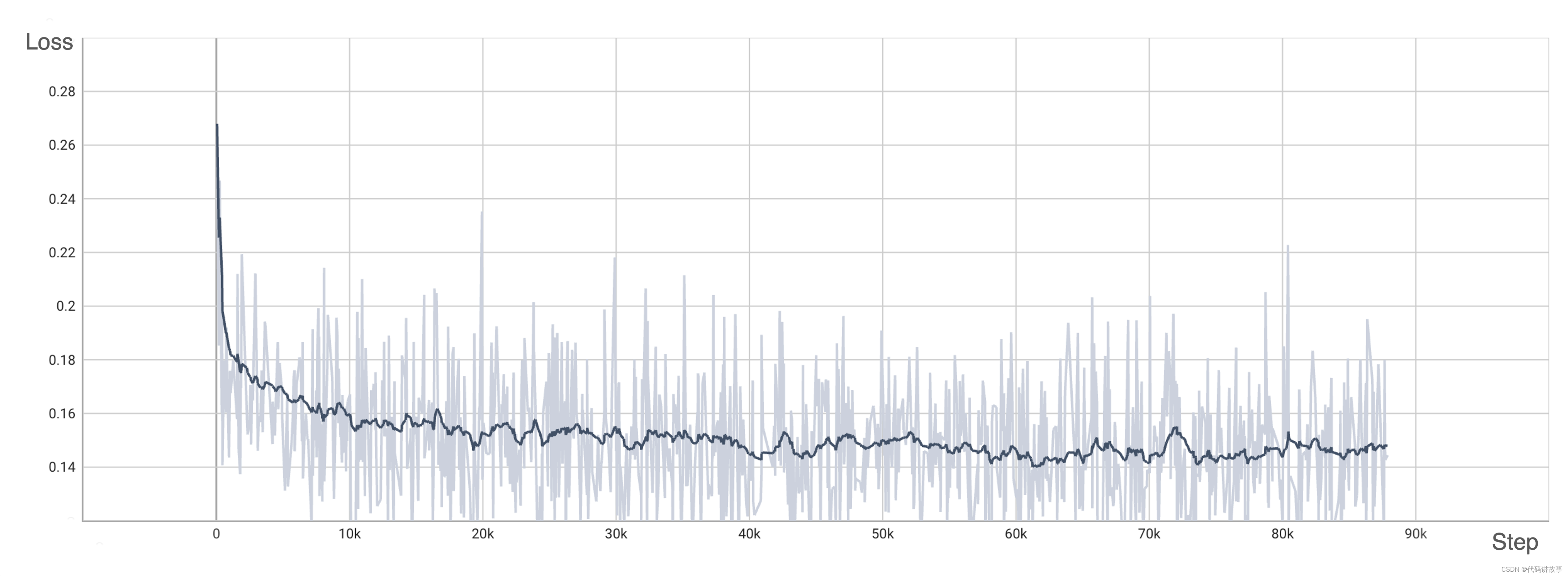
We have trained DiT using the origin method with OpenDiT to verify our accuracy. We have trained the model from scratch on ImageNet for 80k steps on 8xA100. Here are some results generated by our trained DiT:

Our loss also aligns with the results listed in the paper:
To reproduce our results, you can follow our instruction.
Acknowledgement
We extend our gratitude to Zangwei Zheng for providing valuable insights into algorithms and aiding in the development of the video pipeline. Additionally, we acknowledge Shenggan Cheng for his guidance on code optimization and parallelism. Our appreciation also goes to Fuzhao Xue, Shizun Wang, Yuchao Gu, Shenggui Li, and Haofan Wang for their invaluable advice and contributions.
This codebase borrows from:
- OpenSora: Democratizing Efficient Video Production for All.
- DiT: Scalable Diffusion Models with Transformers.
- PixArt: An open-source DiT-based text-to-image model.
- Latte: An attempt to efficiently train DiT for video.
以下是10个免费开源的可以用来将文字或图片转换成视频的工具或项目,以及它们的功能介绍和访问链接:
-
OpenShot Video Editor
- 功能介绍:OpenShot是一个简单且功能强大的视频编辑软件,支持多轨时间线、视频效果、音频编辑等。
- 访问链接:OpenShot
-
Shotcut
- 功能介绍:Shotcut是一个跨平台的视频编辑软件,提供丰富的视频和音频编辑功能,支持多种格式。
- 访问链接:Shotcut
-
Kdenlive
- 功能介绍:Kdenlive是一个非线性视频编辑软件,提供多轨和节点视频编辑功能,适合专业视频制作。
- 访问链接:Kdenlive
-
Olive Video Editor
- 功能介绍:Olive是一个非线性视频编辑器,支持多轨时间线、合成、动态图形和音频编辑。
- 访问链接:Olive Video Editor
-
Flowblade
- 功能介绍:Flowblade是一个快速、可定制的视频编辑器,设计灵感来源于电影剪辑。
- 访问链接:Flowblade
-
HitFilm Express
- 功能介绍:HitFilm Express是一个视频编辑软件,提供专业级别的编辑和合成工具,适合制作特效视频。
- 访问链接:HitFilm Express
-
Blender
- 功能介绍:虽然Blender主要是一个3D建模和动画软件,但它也提供了强大的视频编辑和合成功能。
- 访问链接:Blender
-
Natron
- 功能介绍:Natron是一个开源的合成软件,类似于Nuke,适合用于视频后期制作和视觉效果。
- 访问链接:Natron
-
VLC Media Player
- 功能介绍:VLC不仅是一个媒体播放器,它也提供了视频编辑功能,如剪辑和合并视频。
- 访问链接:VLC Media Player
-
FFmpeg
- 功能介绍:FFmpeg是一个强大的命令行工具,用于处理多媒体文件,包括视频和音频的转换、剪辑和编码。
- 访问链接:FFmpeg
虽然上述工具大多数都提供了将图片和视频编辑成所需格式的功能,但它们可能不直接支持“文字生成视频”这一特定功能。对于将文字转换为视频,可能需要结合使用文本转语音(TTS)工具和视频编辑软件。另外,一些开源的AI模型,如GPT-2或Stable Diffusion,可以用于生成文本描述或图像,然后结合上述工具使用。



















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











