







鸣谢
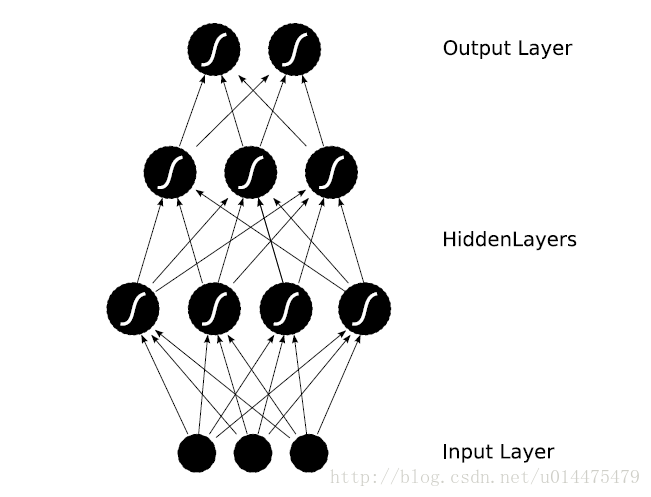
Deep Learning 近年来在各个领域都取得了 state-of-the-art 的效果,对于原始未加工且单独不可解释的特征尤为有效,传统的方法依赖手工选取特征,而 Neural Network 可以进行学习,通过层次结构学习到更利于任务的特征。得益于近年来互联网充足的数据,计算机硬件的发展以及大规模并行化的普及。本文主要简单回顾一下 MLP ,也即为Full-connection Neural Network ,网络结构如下,分为输入,隐层与输出层,除了输入层外,其余的每层激活函数均采用 sigmod ,MLP 容易受到局部极小值与梯度弥散的困扰,如下图所示:
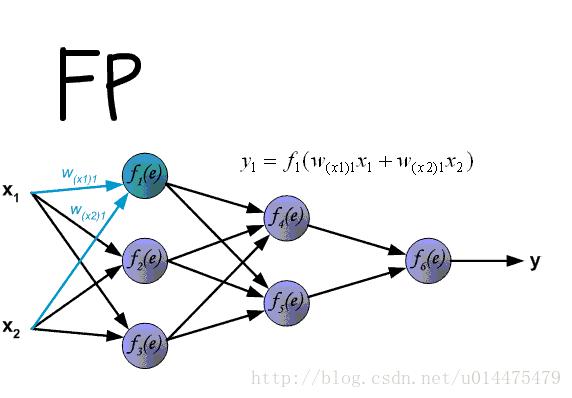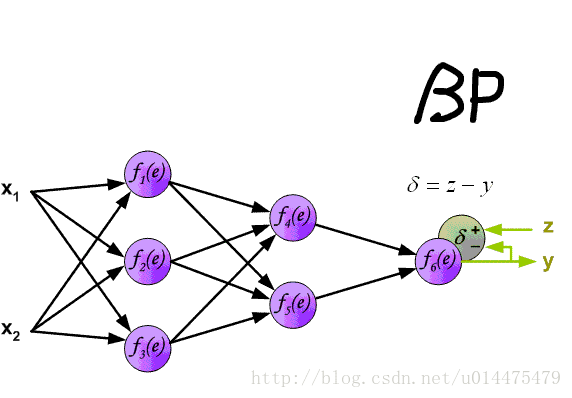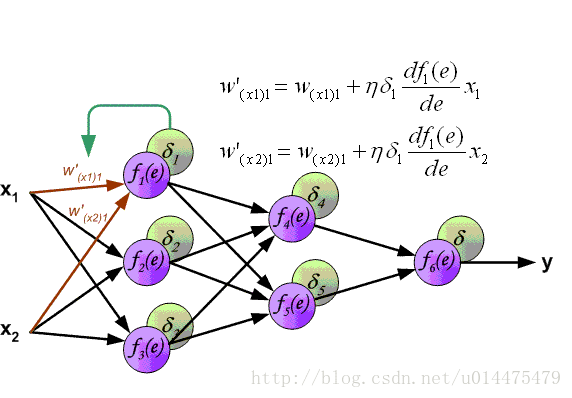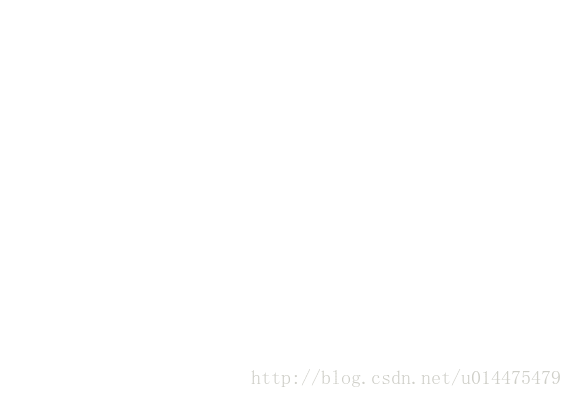
MLP 的 Forward Pass
MLP 的 BP 算法基于经典的链式求导法则,首先看前向传导,对于输入层有
I
个单元, 对于输入样本
ah=∑i=1Iwihxi
bh=f(ah)
这里函数 f 为 非线性激活函数,常见的有
bh=f(ah)
对于输出层,若采用二分类即 logisticregression ,则前向传导到输出层:
a=∑h′wh′hbh′
y=f(a)
这里 y 即为
O=−⎡⎣∑(x,z)zlogy+(1−z)log(1−y)⎤⎦
对于多分类问题,即输出层采用 softmax ,假设有 K 个类别,则输出层的第
ak=∑h′wh′kbh′
yk=f(ak)
则得到类别 k 的概率可以写作
O=∏(x,z)∏kyzkk
同理等价于极小化以下损失:
O=−∏(x,z)∏kyzkk
以上便是 softmax 的损失函数,这里需要注意的是以上优化目标 O 均没带正则项,而且
Backward Pass
有了以上前向传导的过程,接下来看误差的反向传递,对于
sigmod
来说,最后一层的计算如下:
a=∑hwh⋅bh
,
y=f(a)=σ(a)
这里
bh
为倒数第二层单元
h
的输出,
O=−[zlog(σ(a)+(1−z)log(1−σ(a))]
可得到如下的链式求导过程:
∂O∂wh=∂O∂a⋅∂a∂wh
显而易见对于后半部分 ∂a∂wh 为 bh ,对于前半部分 ∂O∂a :
∂O∂a=−∂[z log(σ(a))+(1−z)log(1−σ(a))]∂a=−[zσ(a)−1−z1−σ(a)]σ′(a)=−[zσ(a)−1−z1−σ(a)]σ(a)(1−σ(a))=σ(a)−z=y−z
以上,便得到了 logistic 的残差,接下来残差反向传递即可,残差传递形式同 softmax ,所以先推倒 softmax 的残差项,对于单个样本, softmax 的 log 损失函数为:
O=−∑izilogyi
其中:
yi=eai∑jeaj
根据以上分析,可以得到 yk′ 关于 ak 的导数:
∂yk′∂ak=⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪∑i≠keaj⋅eak∑jeaj⋅∑jeajeak′⋅eak∑jeaj⋅∑jeaj=yk(1−yk) k′=k=−yk′yk k≠k
现在能得到损失函数 O 对于
∂O∂ak=∂[−∑izilogyi]∂ak=−∑izi⋅∂logyi∂ak=−∑izi1yi∂yi∂ak=−zk(1−yk)−∑i≠kzi1yi(−yiyk)=−zk+zkyk+∑i≠kziyk=−zk+yk(∑izi)=yk−zk
这里有 ∑izi=1 ,即只有一个类别。 到这一步, softmax 与 sigmod 的残差均计算完成,可以用符号 δ 来表示,对于单元
δj=∂O∂aj
这里可以得到 softmax 层向倒数第二层的残差反向传递公式:
δh=∂O∂bh⋅∂bh∂ah=∂bh∂ah∑k∂O∂ak⋅∂ak∂bh=f′(ah)∑kwhkδk
其中 ak=∑hwhkbh ,对于 sigmod 层,向倒数第二层的反向传递公式为:
δh=∂O∂bh⋅∂bh∂ah=∂bh∂ah⋅∂O∂a⋅∂a∂bh=f′(ah)whδ
以上公式的 δ 代表
δh=f′(ah)∑h′=1hl+1whh′δh′
整个过程可以看下图:
最终得到关于权重的计算公式:
∂O∂wij=∂O∂aj∂aj∂wij=δjbi
至此完成了 backwark pass 的过程,注意由于计算比较复杂,有必要进行梯度验证。对函数 O 关于参数















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









