







Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
Pandas 主要引入了两种新的数据结构:DataFrame 和 Series。
-
Series: 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。

-
DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。
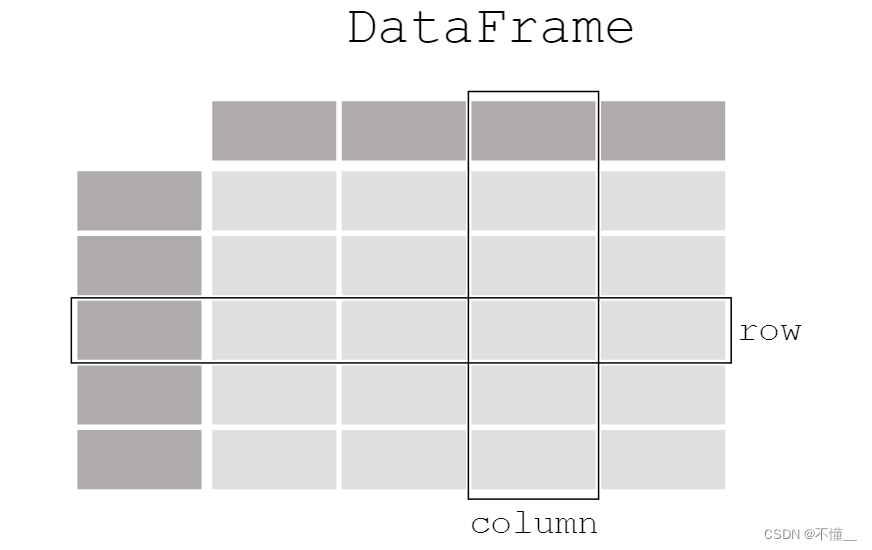
DataFrame 可视为由多个 Series 组成的数据结构: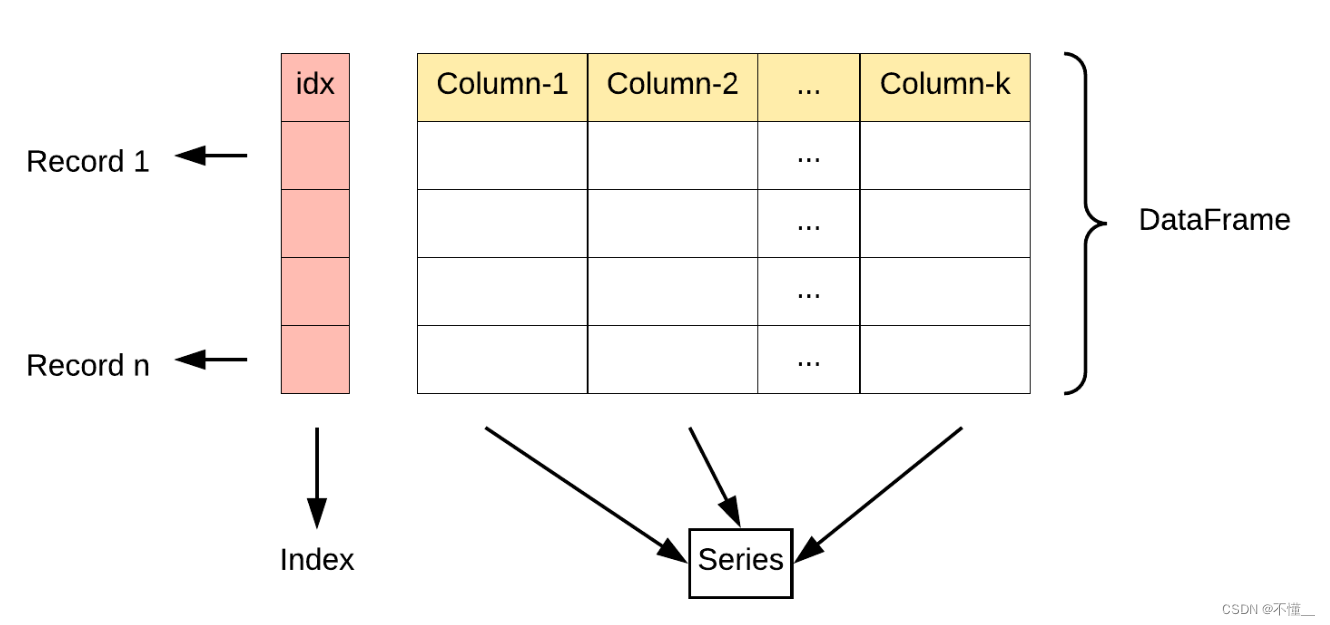
Pandas 提供了丰富的功能,包括:
-
数据清洗:处理缺失数据、重复数据等。
-
数据转换:改变数据的形状、结构或格式。
-
数据分析:进行统计分析、聚合、分组等。
-
数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
一、Pandas 应用
Pandas 在数据科学和数据分析领域中具有广泛的应用,其主要优势在于能够处理和分析结构化数据。
以下是 Pandas 的一些主要应用领域:
-
数据清洗和预处理: Pandas被广泛用于清理和预处理数据,包括处理缺失值、异常值、重复值等。它提供了各种方法来使数据更适合进行进一步的分析。
-
数据分析和统计: Pandas使数据分析变得更加简单,通过DataFrame和Series的灵活操作,用户可以轻松地进行统计分析、汇总、聚合等操作。从均值、中位数到标准差和相关性分析,Pandas都提供了丰富的功能。
-
数据可视化: 将Pandas与Matplotlib、Seaborn等数据可视化库结合使用,可以创建各种图表和图形,从而更直观地理解数据分布和趋势。这对于数据科学家、分析师和决策者来说都是关键的。
-
时间序列分析: Pandas在处理时间序列数据方面表现出色,支持对日期和时间进行高效操作。这对于金融领域、生产领域以及其他需要处理时间序列的行业尤为重要。
-
机器学习和数据建模: 在机器学习中,数据预处理是非常关键的一步,而Pandas提供了强大的功能来处理和准备数据。它可以帮助用户将数据整理成适用于机器学习算法的格式。
-
数据库操作: Pandas可以轻松地与数据库进行交互,从数据库中导入数据到DataFrame中,进行分析和处理,然后将结果导回数据库。这在数据库管理和分析中非常有用。
-
实时数据分析: 对于需要实时监控和分析数据的应用,Pandas的高效性能使其成为一个强大的工具。结合其他实时数据处理工具,可以构建实时分析系统。
Pandas 在许多领域中都是一种强大而灵活的工具,为数据科学家、分析师和工程师提供了处理和分析数据的便捷方式。
二、Pandas 安装
安装 pandas 需要基础环境是 Python,Pandas 是一个基于 Python 的库,因此你需要先安装 Python,然后再通过 Python 的包管理工具 pip 安装 Pandas。
使用 pip 安装 pandas:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas 三、Pandas 数据结构 - Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
-
索引: 每个
Series都有一个索引,它可以是整数、字符串、日期等类型。如果没有显式指定索引,Pandas 会自动创建一个默认的整数索引。 -
数据类型:
Series可以容纳不同数据类型的元素,包括整数、浮点数、字符串等。
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,但具有标签(索引),使得数据在处理和分析时更具灵活性。
以下是关于 Pandas 中的 Series 的详细介绍: 创建 Series: 可以使用 pd.Series() 构造函数创建一个 Series 对象,传递一个数据数组(可以是列表、NumPy 数组等)和一个可选的索引数组。
pandas.Series( data, index, dtype, name, copy)参数说明:
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar,myvar[1])指定索引值,根据索引值读取数据:
import pandas as pd
a = ["python", "numpy", "pandas"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar,myvar["y"])也可以使用 key/value 对象,类似字典来创建 Series,字典的 key 变成了索引值
import pandas as pd
sites = {1: "python", 2: "numpy", 3: "pandas"}
myvar = pd.Series(sites)
print(myvar)如果只需要字典中的一部分数据,只需要指定需要数据的索引即可
import pandas as pd
sites = {1: "python", 2: "numpy", 3: "pandas"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)设置 Series 名称参数:
import pandas as pd
sites 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3656
3656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









