







Pandas的两个主要数据结构:Series和DataFrame
Series
1.类似于一维数组对象,由一组数据(value)和一组与之相关的数据标签(index)组成。
2.Index可以自己指定,也可自动生成
obj = Series([4,7, -5, 3])
obj2 =Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
3.与Numpy相比,pandas可以通过index选取Series中的单个或者一组值
4.Python字典格式数据可以直接创建Series
5. In[20]: sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
In[23]: states = ['California', 'Ohio', 'Oregon', 'Texas']
In [24]: obj4 =Series(sdata, index=states)
In [25]: obj4
Out[25]: California NaN
Ohio 35000
Oregon 16000
Texas 71000
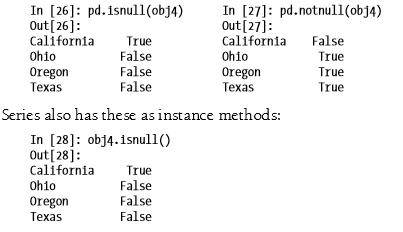
6.pandas.isnull/notnull 可以用于检测缺失数据
7.Series的一个非常重要的功能是,能自动对齐不同索引的数据
8.Series以及Series.index都有一个name属性
DataFrame
1.DataFrame是一个表格型的数据结构,含有一组有序的列。DataFrame既有行索引也有列索引。
2.DataFrame的几种常用构造方法:
2.1 输入一个多维数组 DataFrame([[1,2,3],[4,5,6],[7,8,9]])
也可以指定index和column


这时可以用DataFrame.d/e/f 或者DataFrame[‘d’]/[‘e’]/[‘f’]来表示相应的列。但是,只能从columns中选,不能从index中选
2.2 输入由Numpy数组组成的字典
2.3输入嵌套字典


3.在对列进行赋值时,可以使用常数,或者数组,也可以是Series
4.为不存在的列赋值会创建出一个新列
5.关键词del用于删除列
6.Index的方法以及属性

7.Series.reindex(name_list)调用Series的reindex方法会根据新索引进行重排。如果索引值当前并不存在,则引入缺失值,使用fill_value=0选项能够填充缺失值
8.reindex的method选项:ffill/pad/bfill/backfill 但是在DataFrame中,method方法只能按行应用
9.DataFrame的reindex()可以修改索引,.reindex(columns=…)可以修改列















 1956
1956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









