






基本结构
Transformer基本结构
基本采用经典Transformer结构。由于只需要对交易进行建模,因此只使用左边Encoding部分结构即可。
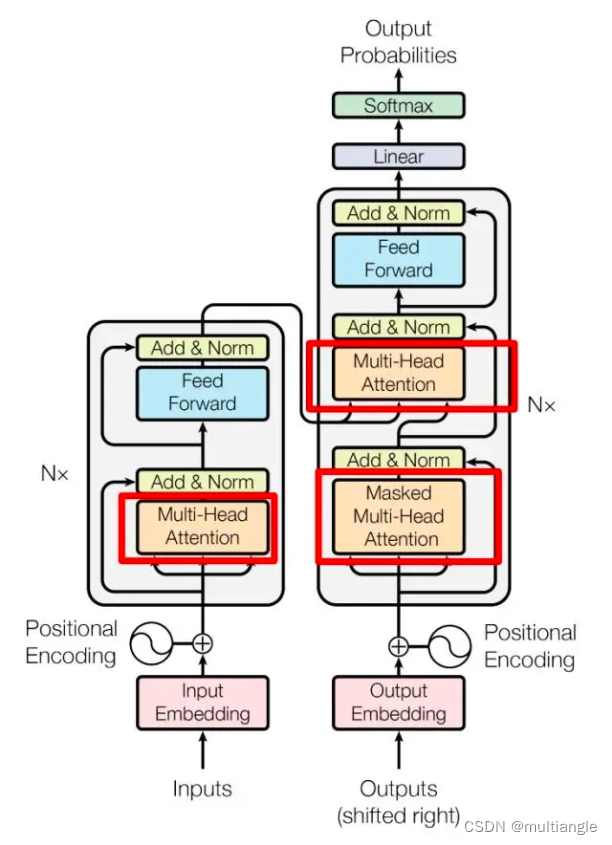
交易序列特征
在特征方面,与一般NLP任务不同,交易序列模型中序列中每个输入由多个特征拼接而成。常用特性包括:交易金额、交易方向、交易时间、交易类型、客户类型、对手客户类型等。特征一般需要经过分桶以后再转为embedding输入
工程化实现
模型实现方面,采用tensorflow方案。
dataset
Tensorflow 2.0中提供了专门用于数据输入的接口tf.data.Dataset,可以简洁高效的实现数据的读入、打乱(shuffle)、增强(augment)等功能。
dataset可以有多个数据源,例如csv、parquet、tensor等等,并方便的实现数据的流式读取
基于numpy array进行构建
data = np.array([0.1, 0.4, 0.6, 0.2, 0.8, 0.8, 0.4, 0.9, 0.3, 0.2])
label = np.array([0, 0, 1, 0, 1, 1, 0, 1, 0, 0])
dataset = tf.data.Dataset.from_tensor_slices((data, label))
for x, y in dataset:
print(x, y)
基于csv进行构建
通过tf.data.experimental.make_csv_dataset api进行直接构建
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=5, # Artificially small to make examples easier to show.一批五个样本
label_name=LABEL_COLUMN,
na_value="?",
num_epochs=1,
ignore_errors=True,
**kwargs)
基于parquet进行构建
直接使用tf读取parquet有一定难度,目前没有成熟高效的解决方案。
一般是通过pyarrow或者fastparquet将parquet文件转为pandas dataframe,然后再转为dataset。
dataset的迭代器、shuffle、重复
# 通过执行repeat()使数据集能多次迭代
dataset = dataset.repeat()
# shuffle()是随机打乱样本次序,参数buffer_size建议设为样本数量,过大会浪费内存空间,过小会导致打乱不充分。
dataset = dataset.shuffle(buffer_size=10)
# batch()是使迭代器一次获取多个样本
dataset_batch = dataset.batch(batch_size=5)
Feature Column
feature column是tf中标定的对数据的处理方案。通过dataset与feature column配合,实现数据的读入与处理。
目前总共有九种不同的函数,按产出特征类型来分,大致可以分为categorical和dense两类。
在九种函数中,分别有五种Categorical function、三种numerical function 加上一种bucketized_column可属于任何一种,categorical column中的 with_identity其实和 dense column中的indicator_column没有区别,都是类别特征的one-hot表示,但是其属于不同的特征类别,前者属于categorical后者属于dense,对于estimator编写的不同网络而言,其可接受的one-hot类型不同,这里在实际操作中需要注意转换
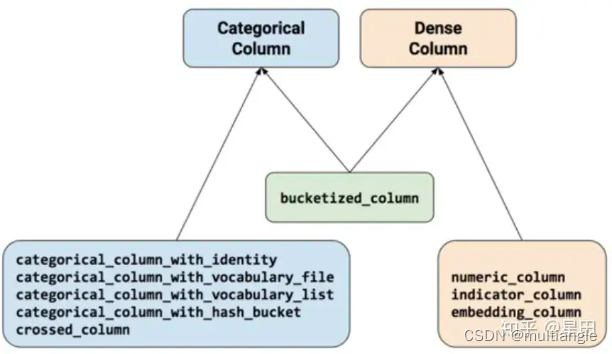
categorical function
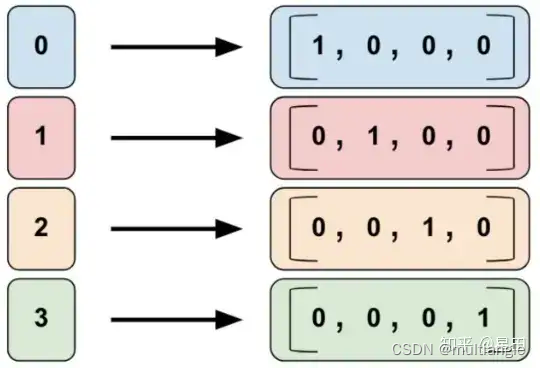
categorical_column_with_identity
把numerical data转乘one hot encoding
categorical_column_with_vocabulary_file
根据单词的序列顺序,把单词根据index转换成one hot encoding
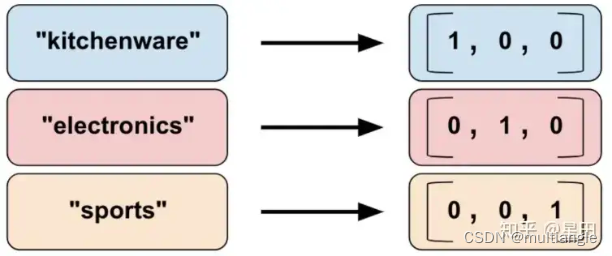
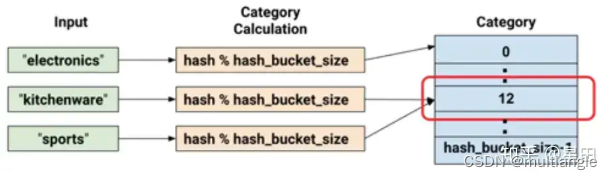
categorical_column_with_hash_bucket
对于处理包含大量文字或数字类别的特征时可使用hash的方式,这能快速地建立对应的对照表,缺点则是会有哈希冲突的问题
crossed_column
特征交叉。对于两个categorical类型的特征,可以使用cross column进行交叉操作(笛卡尔积)
dense function
embedding_column
把categorical的data,借由lookup table的方式找寻对应的embedding vector来表示
numeric_column
把原始数值特征输入模型
特征维度的确定
这个没有一定。最好是根据实际情况实验得到。但是一般来讲,有两种经验公式。
经验法则: n>N**0.25
基于理论推导的结论:n>8.33lnN
第二条,主要是基于这样一个出发点:
语言本身具有一定的不确定性,而我们在用向量编码词语时,编码结果应该要等于甚至小于这种不确定性,才能保证这种编码是有效的、能充分保留原来语言的信息
两种方式对比:
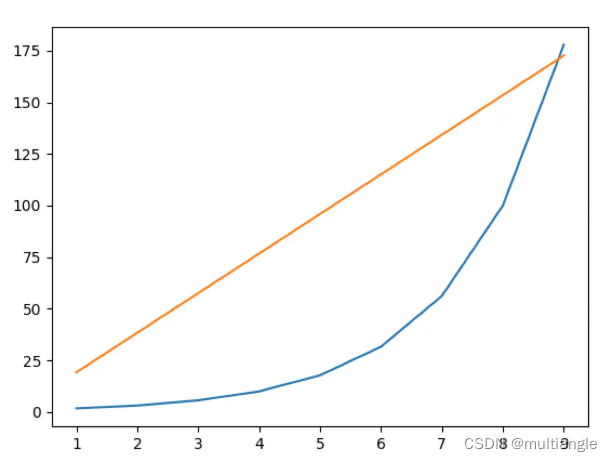
蓝色为第一种。黄色为第二种。横坐标为对数表示。
关于为何经验公式得到的维度值远低于理论推导值的猜测:理论是假设均匀分布的。单词的概率是均匀分布的,词向量也都是均匀分布在超球面上面的;实际的分布存在长尾效应,因此实际的不确定性要比理论预估的更小
平台中结果的输出
官方api: saveOutput
实际运行中,由于其会将所有积累的输出结果一起转为parquet,会占用大量内存,容易导致任务失败。
如果要减少资源占用,可以分批输出,使用pyarrow包自行将每个批次的输出转化为parquet文件放在平台指定位置。
结构优化的尝试
标准Attention与线性Attention
标准attention的公式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
T
K
)
V
Attention(Q,K,V) = softmax(Q^TK)V
Attention(Q,K,V)=softmax(QTK)V
假设:
Q
,
K
,
V
∈
R
n
×
d
Q,K,V\in R^{n\times d}
Q,K,V∈Rn×d
标准attention中,计算复杂度为O(n * n) + O(n * d)
线性attention为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
Q
K
T
V
Attention(Q,K,V) = QK^TV
Attention(Q,K,V)=QKTV,计算复杂度为O(n * d)+O(d * d)
当d<<n时,标准attention复杂度为O(n2),线性attention复杂度为O(n)
实际效果:由于模型序列长度与特征维度差距不大,因此性能提升不明显。
Position Embedding的性质及改动
Position Embedding的三种写法 方法
- 通过模型进行端到端的学习
- 正弦表示
- ROPE表示
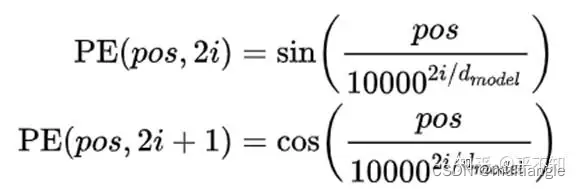
从Attention的论文中,可以得知第一种和第二种方式效果差不多。但是第二种方式可以很方便地用于外推。
正弦形式Position Embedding的性质
从公式推断出来一个长度为18,emb维度为96的position embedding,用热力图表示:
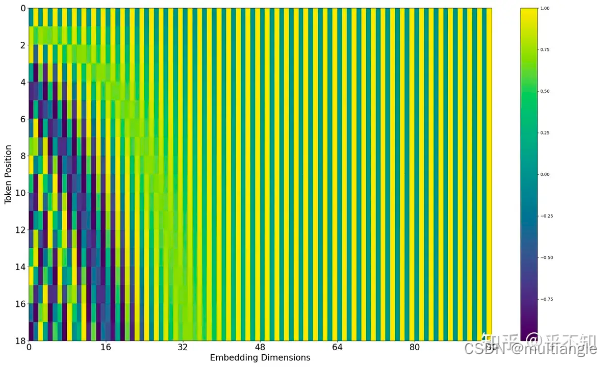
把sin和cos的值分开放置,结果会更加直观:

可以看到,主要是前面几个维度的emb变化比较剧烈,后面的变化幅度很小。
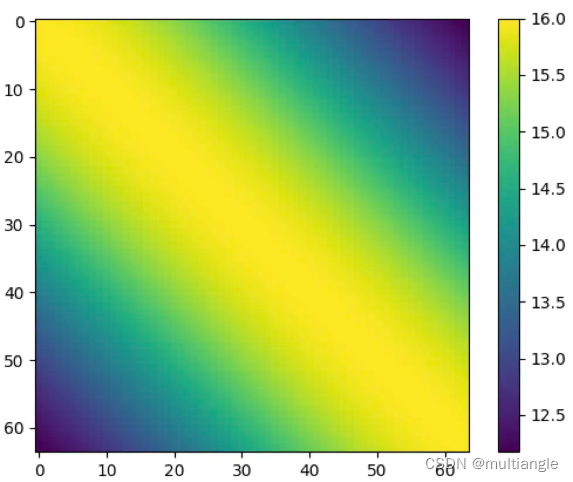
那么在标准PE下面,不同位置之间的关联权重是怎么样的呢?
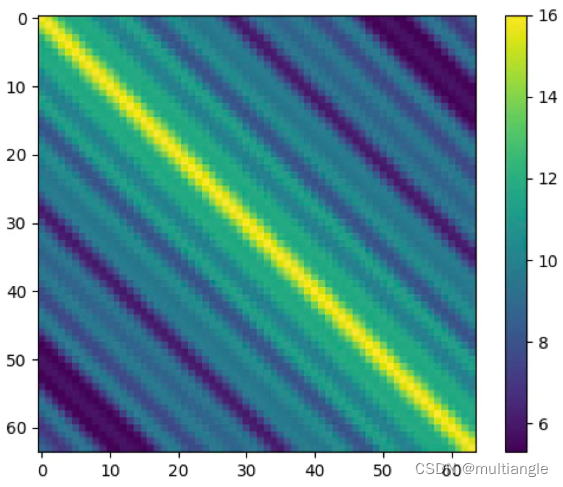
上图为一个长度为64的序列内,各元素之间关系权重的热力图。从中可以得出以下几点结论:
两个元素之间权重只与两者之间相对位置有关,而与其绝对位置无关
两者间距较小时,两者之间权重随着相对距离拉大而减小
两者间距较大时,两者之间权重随着相对距离拉大而波动。
第2、3点在下面的图会更加直观
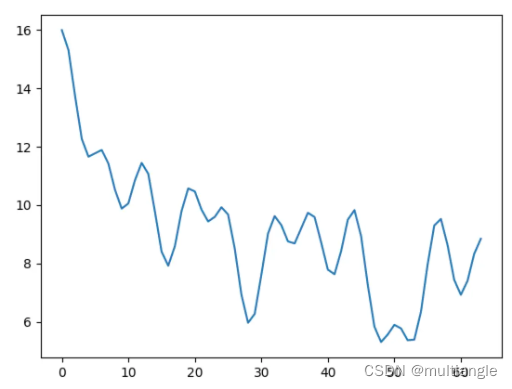
调整PE的scale使之权重单调化
由于上述PE性质中,序列中元素之间权重与相对距离并不是单调关系。那么当模型只用于encoder,序列长度固定时,是否可以调整PE以使之单调?
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
π
L
∗
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos,2i) = sin(\frac{\pi}{L} *\frac{pos}{10000^{2i/d_{model}}})
PE(pos,2i)=sin(Lπ∗100002i/dmodelpos)
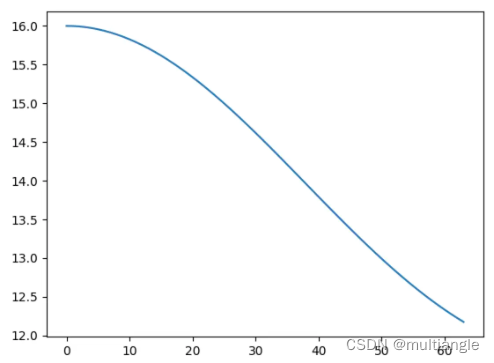
Time Embedding
当对行为进行建模时,往往是时间间隔越短的行为之间关联度越大。如果用传统的PE,则只能保留时序关系,而时间间隔的信息则丢失了
如果将位置信息改为时间间隔信息,则能保留这部分信息。下图中有6段session,可以看到session内由于行为间隔较短,相互之间权重较高;而对于本session之外的行为,由于间隔较长,权重就较低。
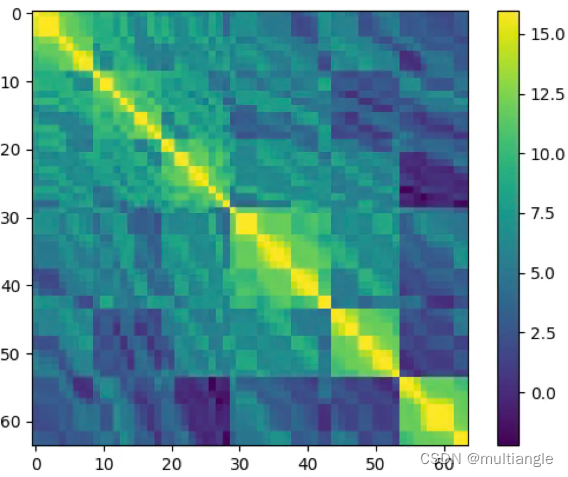















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









