







目录
0. 环境配置
很简单,提示缺包xxx,pip install xxx 就可以了
1. 运行程序
从 DFNI/train.py 开始运行,不报错程序能正常运行就可以了
2. 读代码的思路
因为 DFMN (更名后的DFNI) 的主要贡献是网络结构的设计,因此,我看代码的步骤是:
1)model.py 2) train.py 3) 数据预处理相关代码文件
1)model.py
!! 关于继承
因为是自己设计的网络结构,因此继承了 nn.Module, 初始化代码如下。
可以看到定义的 DFNI 网络,继承了nn.Module。需要注意两个地方:
- class DFNI(nn.Module) 子类的参数要写父类名
- super(DFNI, self).__init__() 子类初始化时要继承父类的所有方法和属性
与父类不同的属性和方法,就需要重新定义进行覆盖。比如:self.firstPart, self.midPart1.
import torch
import torch.nn as nn
class DFNI(nn.Module):
def __init__(self, upscale_factor):
super(DFNI, self).__init__()
self.firstPart = nn.Sequential(
####
)
self.midPart1 = nn.Sequential(
####
)
self.midPart2 = nn.Sequential(
####
)
#
# for p in self.parameters():
# p.requires_grad = False
self.finalPart = nn.Sequential(
###
)
self.con1 = nn.Conv2d(1, 8, kernel_size=7, padding=7 // 2)
self.con2 = nn.Conv2d(8, 16, kernel_size=5, padding=5 // 2)
self.con3 = nn.Conv2d(16, 32, kernel_size=3, padding=3 // 2)
self.con4 = nn.Conv2d(32, 64, kernel_size=1)
self.lrelu = nn.LeakyReLU()
def forward(self, x, xx):
#####
#####
!! 关于网络结构组织
包装一堆卷积和Relu:网络的组成部分最常见的就是卷积和Relu, 一堆卷积和非线性截断函数组成的模块,一般用nn.Sequential()封装成一个模块,并且重新起个名字,方便后续在 forward 调用。
nn.Conv2d 的参数设置:nn.Conv2d(1, 8, kernel_size=7, padding=7 // 2),在这里, 1是输入通道数,8是输出通道数,7是卷积核的大小,默认步长为1,用0填充,尺寸为7 // 2, padding 的尺寸设置为1/2的核尺寸,是为了保证卷积后图像尺寸不变。
nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True))
in_channel: 输入数据的通道数,例RGB图片通道数为3;
out_channel: 输出数据的通道数,这个根据模型调整;
kennel_size: 卷积核大小,可以是int,或tuple;kennel_size=2,意味着卷积大小(2,2), kennel_size=(2,3),意味着卷积大小(2,3)即非正方形卷积
stride:步长,默认为1,与kennel_size类似,stride=2,意味着步长上下左右扫描皆为2, stride=(2,3),左右扫描步长为2,上下为3;
padding:零填充
self.firstPart = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=7, padding=7 // 2),
nn.LeakyReLU(inplace=True), #???LeakyReLU
nn.Conv2d(8, 16, kernel_size=5, padding=5 // 2),
nn.LeakyReLU(inplace=True),
nn.Conv2d(16, 32, kernel_size=3, padding=3 // 2),
nn.LeakyReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=1),
nn.LeakyReLU(inplace=True)
)nn.LeakyReLU(inplace=True)
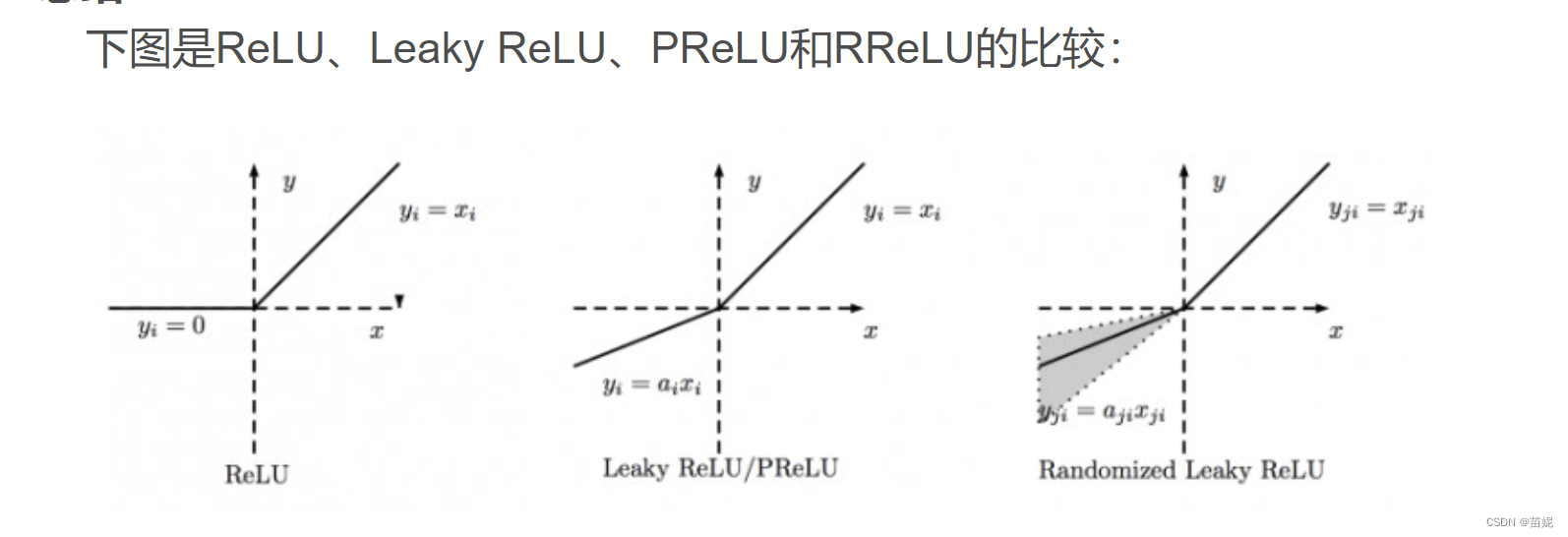
ReLU是将所有的负值都设为零,相反,Leaky ReLU是给所有负值赋予一个非零斜率。
!! 关于 forward
按照数据据的处理流程将定义的模块链接起来就可以了,前一模块的输出是后一模块的输入。
def forward(self, x, xx): # xx 咋来的?
res = x
# x = self.firstPart(x)
x1 = self.lrelu(self.con1(x))
x2 = self.lrelu(self.con2(x1))
x3 = self.lrelu(self.con3(x2))
x4 = self.lrelu(self.con4(x3))
x = torch.cat((x1, x2, x3, x4), dim=1) # dim 为0、1、2 分别表示增加行、增加列、增加厚度三个方向 ??为什么dim 是1
b1 = self.midPart1(x)
b2 = self.midPart2(x)
x = torch.cat((b1, b2), dim=1)
x = torch.add(res, x) # 相加和cat有啥区别?在网络设计的维度上是如何设置的?
x = self.finalPart(x)
x = torch.add(x, xx)
return x在正向传播的时候,因为有级联模块,还有并联模块,残差模块,所以各层的通道数如何设置很困惑?以下是代码作者给出的解答。
x = torch.cat((x1, x2, x3, x4), dim=1) 拼接时,为什么dim 为1?模型输入的是一个四维张量,对应a,第一个相当于个数,为1;第二个为通道数,第三为行,第四为列。即dim=1实现通道数拼接。 x = torch.add(res, x) res的通道数会根据x的通道个数进行复制扩展,比如1->65,然后再相加
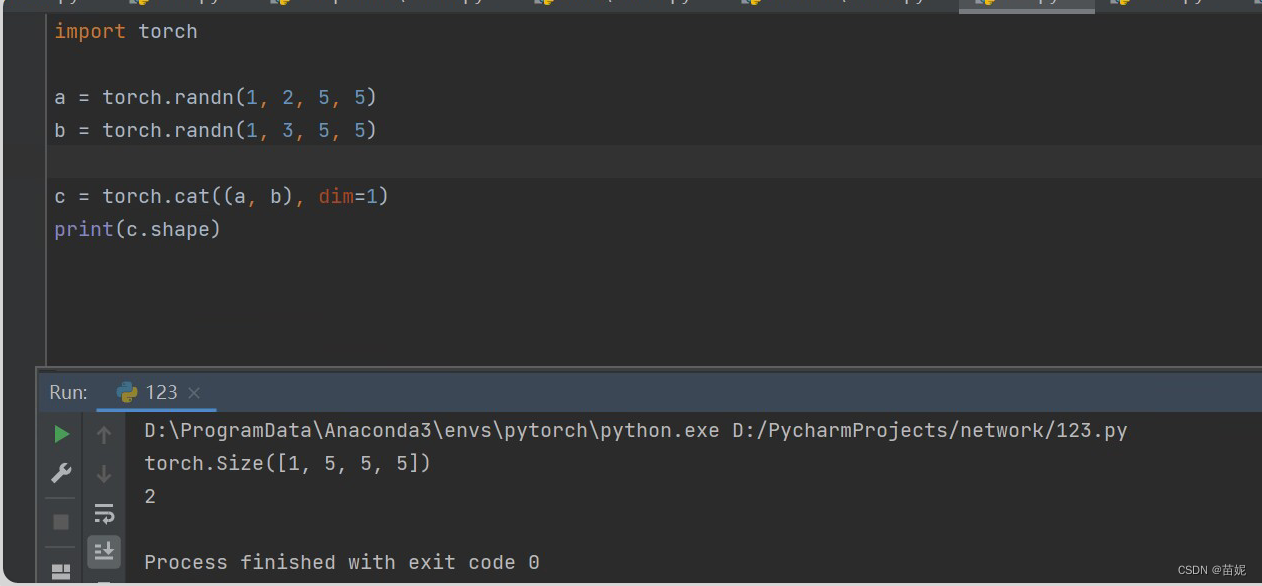
在设计网络初期,如何跟踪每一层输出数据的维度呢?保证每一层设置的参数正确 尤其是有拼接的时候?模型的forward写完之后,然后用随机张量当作输入,调用这个模型测试一下;如果有设计size的问题的话,可以在模型中用print(xx.shape),观察一下。

#写在模型定义外
model = DFNI(4)
input1= torch.randn(1, 1, 175, 63)
input2 = torch.randn(1, 1, 700, 252)
model.load_state_dict(torch.load('DFNI_4.pt',map_location='cpu'))
out = model(input1, input2)
#写在模型内
print(x4.shape)2) 数据预处理
论文的数据是取自开源数据。下采样过程为规律下采样,非规律的会引入噪声。
模型的数据包括:输入(下采样数据,传统方法实现的插值结果<运行inputdataGet>),输出:原始数据。
我们需要准备训练数据集和测试数据集,在Pytorch中,读取数据集需要用到Dataset和DataLoader两个类,Dataset负责对数据的读取,读取的内容是每一个数据和它对应的标签;DataLoader负责对Dataset读取的数据进行打包,然后分批次送入神经网络。
在自定义数据集中,关键是要实现数据类型转换为Dataset,这样就可以调用DataLoader了。
本例子中实现了,npy到Dataset的类型转换。
# 定义了DatasetFromFolder,继承自Dataset,目的:将自定义的数据转为Dataset类
class DatasetFromFolder(Dataset):
def __init__(self, input1, input2, target):
super(DatasetFromFolder, self).__init__()
self.input1 = input1
self.input2 = input2
self.target = target
def __getitem__(self, index):
return self.input1[index], self.input2[index], self.target[index]
def __len__(self):
return len(self.target)
# input1, input2, target均来自.npy 文件,是一个npy数据转为Dataset的范例
input1, input2, target = dataGet_2(num)
input1 = input1.astype(np.float32) #变化数组类型
input2 = input2.astype(np.float32)
target = target.astype(np.float32)
trainSet = DatasetFromFolder(input1, input2, target)
trainDataLoader = DataLoader(dataset=trainSet)3)train.py
本论文的实验,由于数据量少,所以没考虑验证集(???但在实验结果的可信度上我也不确定),或许最后的残差的加入(加入传统插值训练结果进行训练),能够保证实验有较好的效果。
标准的训练、验证、测试模板参考,写的很赞!Pytorch模型训练和模型验证_MoxiMoses的博客-CSDN博客_pytorch训练模型














 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









