







首先看一个例子
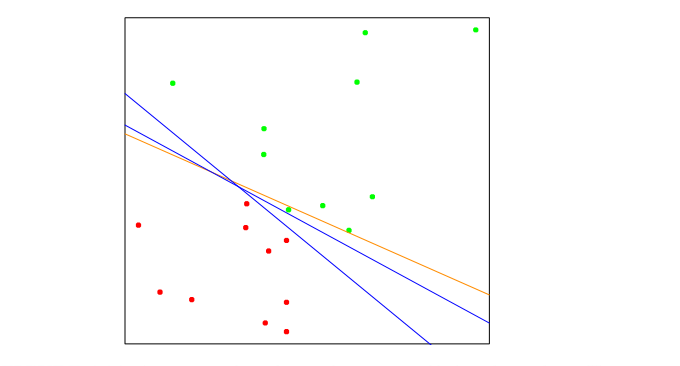
上图显示
IR2
中两个类的20个数据点,这些数据可以被一个线性边界分隔开。前面几篇已经讲了分类的回归方法和LDA,对于这个例子,
橙色的是该问题的最小二乘法解,通过对X上的-1/1响应Y回归得到。
可以看到,这个解不能很好地解决这个问题,因为它错分了一个点。事实上,对于这个问题,LDA的解也就是最小二乘法的解(见上一篇)。
上图中两条蓝色的分隔线是以不同随机初始化的感知机学习算法找出的,可以看到,这里两类被正确分隔开。
感知学习算法(perceptron learning algorithm)试图通过极小化误分类点的函数间隔
yi(xTiβ+β0)
来找出分隔超平面。
如果相应
y=1
被误分类,则
xTβ+β0<0
,而对于被误分类的相应
y=−1
,则
xTβ+β0>0
,感知机的目标是极小化
D(β,β0)=−∑i∈Myi(xTiβ+β0)
其中
M
是误分类点的下标集合。这个量是非负的,并正比于误分类点到判定边界的距离。
梯度由
∂D(β,β0)∂β=−∑i∈Myixi
∂D(β,β0)∂β0=−∑i∈Myi
感知机算法使用随机梯度下降法极小化该准则,这意味着不是每次计算所有误分类数据的梯度和,而是每访问一个误分类观测之后就在该方向上前进一个步长。
因此,按照某种次序访问误分类的观测,并使用下式更新参数
β
β=β+ρyixi
这里把
β0
对应的x的分量看成固定的1。
这里 ρ 是学习率,在这里我们取1。
可以证明,如果类是线性可分隔的,在有限步后,算法收敛于一个分离超平面,如上图中的两条蓝色分隔线。
具体的,考虑如下问题(统计学习基础4.6):
假定
IRp
中有N个点
xi
,这些点具有类标号
yi∈{−1,1}
,现在证明算法在有限步收敛到分隔超平面。
记分隔超平面为
βTx∗=0
,其中
x∗=(x,1)
,
β=(β1,β0)
。设
zi=x∗i/||x∗i||
,
由分隔超平面的性质我们可以得到
yiβTxi>0
所以可以得到
yiβTzi>0
取
yiβTzi
中的最小值m,根据m的定义我们可以得到
yiβTzi>=m
所以
yi(1mβT)zi>=1
在这里定义
βsep=(1mβT)
,所以说存在
βopt
对于任意z,我们有
yiβsepzi>=1
给定当前的\beta_{old},感知机算法之别处z_i被误分类,并产生更新
βnew=βold+yizi
两边同时减去\beta_{sep},然后平方得到
||βnew−βsep||2=||βold−βsep||2+y2i||zi||2+2yi(βold−βsep)Tzi
其中,
y2i||zi||2=1
,又因为是误分类点,所以
2yi(βold−βsep)Tzi=2yiβToldzi−2yiβTsepzi<=(0−1)=−2
所以我们可以得到
||βnew−βsep||2<=||βold−βsep||2−1
所以我们可以得出结论,
感知机算法在不超过
||betastart−βsep||2
步收敛到分离超平面。
感知机模型存在一些问题:
1.当数据可分时,存在很多解,并且找到哪个解依赖于初值。
2.”有限步”的步数可能很大。间隔越小,所需时间越长。
3.当数据不可分时,算法不收敛,并周期变化。该周期很可能很长,因此难以检测。















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









