







 FP-growth算法是一种比Apriori更快的数据挖掘算法,用于发现频繁项集。它通过构建FP树来减少数据库扫描次数,降低IO开销。算法主要包括FP树的构建和挖掘频繁项集两步。在Python中,可以通过构建FP树并递归挖掘来实现该算法。
FP-growth算法是一种比Apriori更快的数据挖掘算法,用于发现频繁项集。它通过构建FP树来减少数据库扫描次数,降低IO开销。算法主要包括FP树的构建和挖掘频繁项集两步。在Python中,可以通过构建FP树并递归挖掘来实现该算法。
概述
FP-growth算法基于Apriori构建,但在完成相同任务时采用了一些不同的技术。这里的任务是将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或者频繁项对,即常在一块出现的元素项的集合FP树。这种做法使得算法的执行速度要快于Apriori,通常性能要好两个数量级以上。
FP-growth算法只需要对数据库进行两次扫描,而Apriori算法对每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-growth算法的速度要比Apiori算法要快。Apriori算法的缺点是多次扫描数据库带来了巨大的IO开销,而FP-growth算法是典型的基于内存的算法,其优点是减少扫描次数来减少IO开销。
FP-growth发现频繁项集的基本过程如下:
(1)构建FP树
(2)从FP树中挖掘频繁项集
FP树的构建
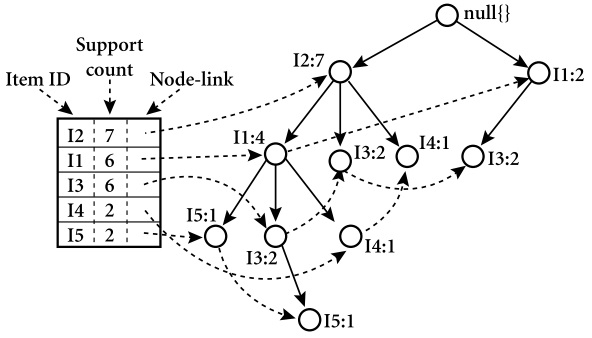
FP树是一种前缀树,有点类似于Trie树但是每个节点有三个指针,分别指向parent,children和nodeLink。此外,算法中还包含有一个头指针表,头指针表中记录每个元素出现的第一个位置(结点),结点中的nodeLink将所有相同的元素连接起来。
第一遍扫描数据库的时候统计每个元素(单项集)出现次数。
第二遍扫描数据库的时候对于原来的每个数据,将数据中支持度小于阈值的元素删除,然后将这个数据按照刚才元素出现次数排序。排序后每个项集都有一个唯一的顺序,这样可以保证后续算法找出所有不重复的频繁项集。然后将这个数据插入到FP树中,并且更新头指针表和nodelink。
挖掘频繁项集
在挖掘频繁项集的时候,类似于Apriori算法,从单项集出发每次增加一个元素。对于每一个频繁项集,我们获得这个频繁项集作为结尾的所有前缀路径(起点为根节点),这些路径的集合称为条件模式基(conditional pattern base)。这里就用到了之前的nodeLink指针,我们可以获得当前所有以某个元素结尾的结点指针。
上面说了,FP-growth类似于Apriori算法,从单项集出发每次增加一个元素。FP-growth算法对于每一个频繁项集以前缀路径构造一棵FP树,然后向当前的频繁项集中添加一个元素,然后以深度优先的策略递归的进行这个过程知道发现所有频繁项集。
例子
考虑以下数据集
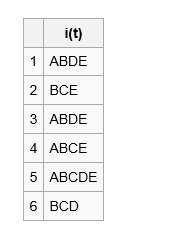
为了构造FP树,首先第一遍扫描数据计算所有单项集的支持度。然后将支持度大于阈值的单项集按照降序排列{ B(6), E(5), A(4), C(4), D(4) }.。
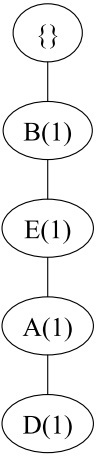
对于第一个数据BEAD,将它插入到FP树中,如下
对于第二个数据BEC,插入到FP树中,如下
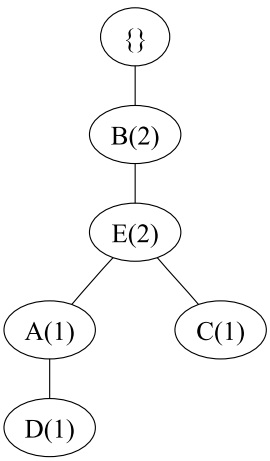
将剩下的数据做相同的操作,最后得到初始的FP树
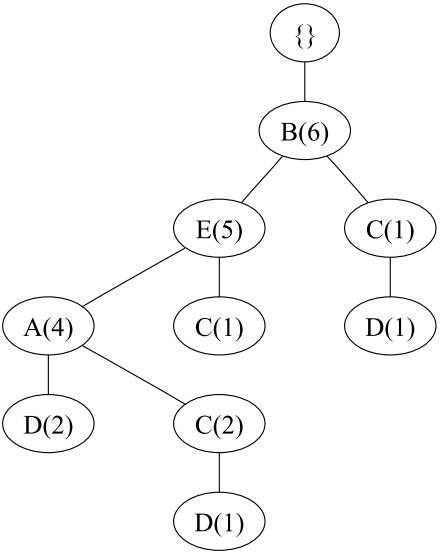
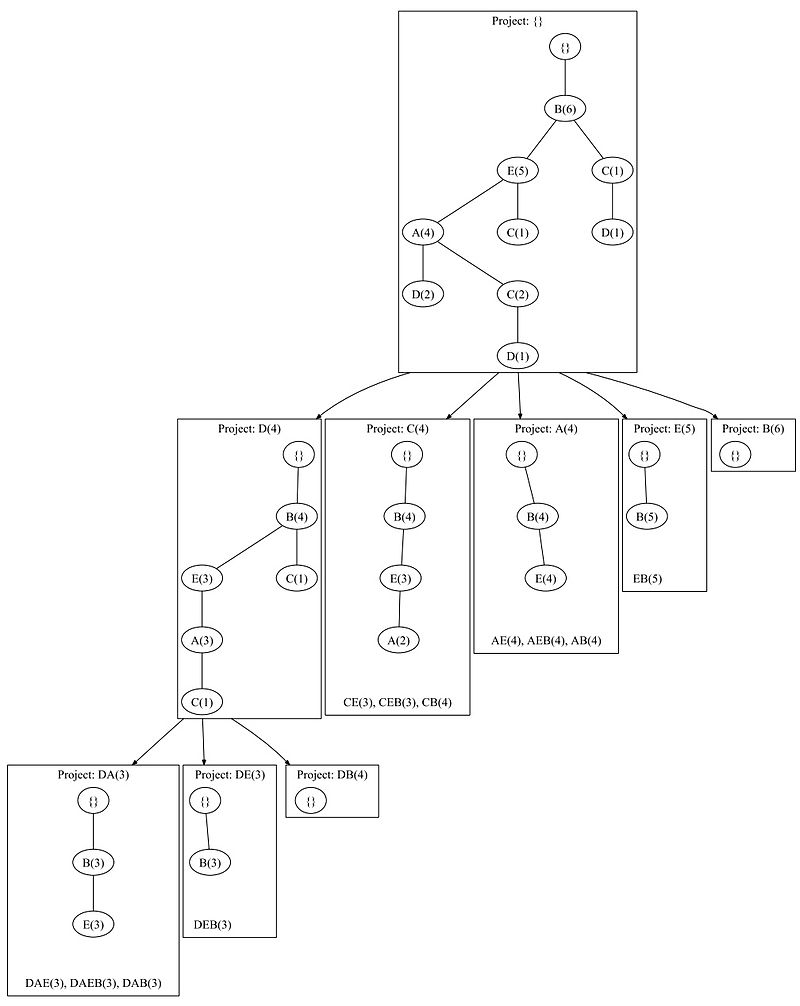
然后开始挖掘频繁项集
第一次调用的时候利用上面构造的初始树,第一步获得频繁项集{D, C, A, E,B},用深度优先的策略,以D为后缀的前缀路径构造一棵新的FP树,然后可以得到频繁项集{DA, DE,DB},然后这样递归下去,直到找到所有频繁项集{ DAE, DAEB, DAB, DEB, CE, CEB, CB, AE, AEB, AB, EB }。流程如下图所示
Python实现代码
from numpy  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









