







最小角回归和其他方法的比较
逐步选择(forward selection)算法(例如forward stepwise regression)在进行子集选择的时候可能会显得太具有“侵略性”(aggressive),因为每次在选择一个变量后都要重新拟和模型,比如我们第一步选择了一个变量 x1 ,在第二步中可能就会删除掉一个和 x1 相关但也很重要的变量。
Forward Stagewise是一种比起上面的逐步选择方法更谨慎的方法,但是可能要经过很多步才能到达最后的模型。具体来说,算法每次在变量的solution path上前进一小步,而forward stepwise regression每次都前进一大步。这样一来,Forward Stagewise可以避免漏掉某些重要的和响应相关的变量,但也带来了高昂的计算代价。
Forwad Stagewise有着和Lasso很大的相似性,下图是二者的参数估计,其中 stepwise每次都进行6000步。可以看到,尽管二者的定义看起来完全不同,但是却有着相似的结果。
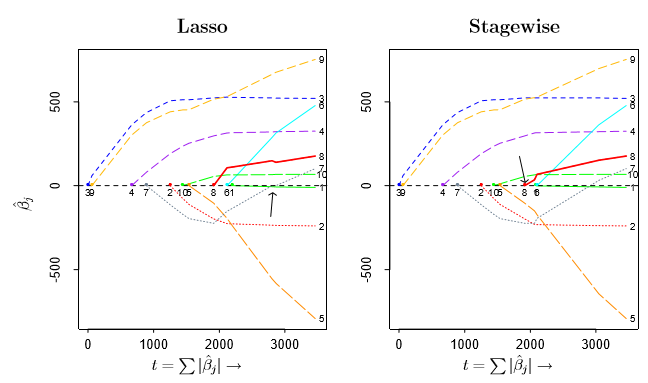
Forward Stagewise和Lasso都可以看做是最小角回归(Least Angle Regression)的变体,事实上缩写LARS中的s就暗示着Lasso和stagewise。
最小角回归(Least Angle Regression)算法加速了计算过程,只需m步(m是自变量的个数)得到参数的估计值。
算法描述
首先简单的描述一下最小角回归,算法从所有系数都为零开始(X标准化,Y中心化),首先找到和响应y最相关的预测变量 xj1 ,在这个已经选择的变量的solution path上前进直到有另一个变量 xj2 ,使得这两个变量与当前残差的相关系数相同。
然后重复这个过程,LARS保证了所有入选回归模型的变量在solution path上前进的时候,与当前残差的相关系数都是一样的。
下面是考虑只有两个变量的情景:
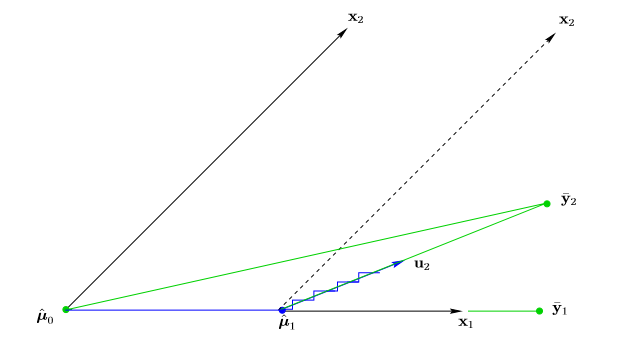
记 μ^ 为当前拟合值,初始化为0向量,定义 c(μ^)
c^=c(μ^)=XT(y−μ^) (1)
所以 c^j 正比于变量 xj 和当前残差向量的相关度。
可以看到,在只有两个变量的情况下,当前的残差(1)只与 y 在
c(μ^)=XT(y−μ)=XT(y2−μ) ,
因为 x1 与 y2−μ 的角度更小,即 c1(μ^0)>c2(μ^0)
LARS算法更新当前拟合值,
μ^1=μ^0+γ^1x1
注意到这里如果是stagewise算法,那么 γ^1 是一个很小的常数,然后算法重复进行此步骤;如果是逐步选择算法, γ^1 是使得
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









