







Note that:本节中所要讨论的function不适用于large scale dataset training。
看了一下,基本都是最基础的知识,就提几点需要特别注意的地方。
首先,看一下 Multi-layer Perceptron,他可以用于classification,也可以用于regression,用于regression时,output没有activation function,直接输出最后一层计算所得值。
Multi-layer Perceptron function
#used for classification
sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100, ), activation=’relu’, solver=’adam’, alpha=0.0001, batch_size=’auto’, learning_rate=’constant’, learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10)
#hidden_layer_sizes:隐含层的数目
#activation:activation function:{identity’, ‘logistic’, ‘tanh’, ‘relu’}
#solver:求解参数的算法:{‘lbfgs’, ‘sgd’, ‘adam’}
#lbfgs:其核心理念类似于“牛顿算法”,该算法中用到的赫森矩阵是估计值,而非真实的计算值。
#sgd:stochastic gradient descent。
#adam:类似于sgd,但是其learning rate可以自适应调整。
#alpha:L2 penalty parameter。
#batch_size:Size of minibatches for stochastic optimizers。
#power_t:The exponent for inverse scaling learning rate. It is used in updating effective learning rate when the learning_rate is set to ‘invscaling’. Only used when solver=’sgd’.
#shuffle:在每次iteration中是否对sample洗牌
#tol:Tolerance for the optimization。
#momentum:用来保证weight更新的stable,值在0,1之间。其核心思想是,updating weight中掺入原old weight,以保证weight updating稳步进行。
#nesterovs_momentum :是否运用该momentum way,Boolean value{True,False}
#beta_1,beta_2:Exponential decay rate for estimates of first/second moment vector in adam, should be in [0, 1). Only used when solver=’adam’
#epsilon:Value for numerical stability in adam. Only used when solver=’adam’。
#used for regression
sklearn.neural_network.MLPRegressor(hidden_layer_sizes=(100, ), activation=’relu’, solver=’adam’, alpha=0.0001, batch_size=’auto’, learning_rate=’constant’, learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10)
#note that:sgd,adam都可用于online learning,但是,lbfgs不可用于online learning。
Multi-layer Perceptron局限
- 其loss function为non-convex function,有很多的local optimizaiton.
- 需要调节很多的参数,如:hidden layer数量,每层neuron 数量,iteration次数.
- **MLP is sensitive to feature scaling.**所以,在利用MLP function之间,应该先将datavalue调整到(0,1)或者(-1,1)之间。或者进行标准化,使其mean=0,variance=1.
Regularizaiton
MLP classification和MLP regression都采用L2进行正则化,其公式分别如下:
- classification:
- regression:
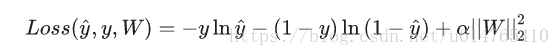
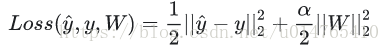
Multi-class vs Binary-class
output activation function比较:
- Binary-class:
- Multi-class:
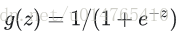
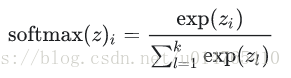
additional monitoring : warm_start=True, max_iter=1
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = MLPClassifier(hidden_layer_sizes=(15,), random_state=1, max_iter=1, warm_start=True)
>>> for i in range(10):
... clf.fit(X, y)
... # additional monitoring / inspection
MLPClassifier(...















 6727
6727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











