









Anomaly Detection异常检测
就是将异常的数据检测出来。
举个例子:
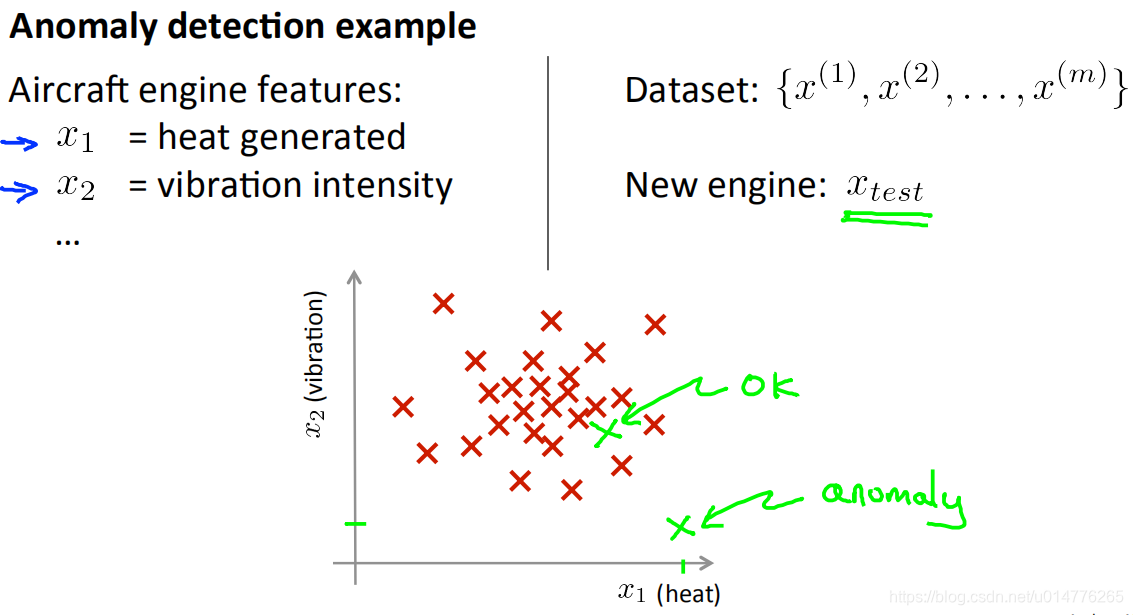
当一辆飞机生产完后,我们需要对它的性能指标进行检测,例如引擎运算时产生的热量,引擎的震动等。然后我们对这些特征向量进行采集,那么就有了一个数据集了。假如我们的测试数据在我们数据集允许的误差范围内,那么这个数据是正常的,假如离误差范围太远,那么这个数据则异常数据的。
假如要更为正式定义异常检测问题,首先我们有一组从 x(1)到x(m)m个样本,且这些样本均为正常的。我们将这些样本数据建立一个模型 p(x), p(x)表示为 x的分布概率。
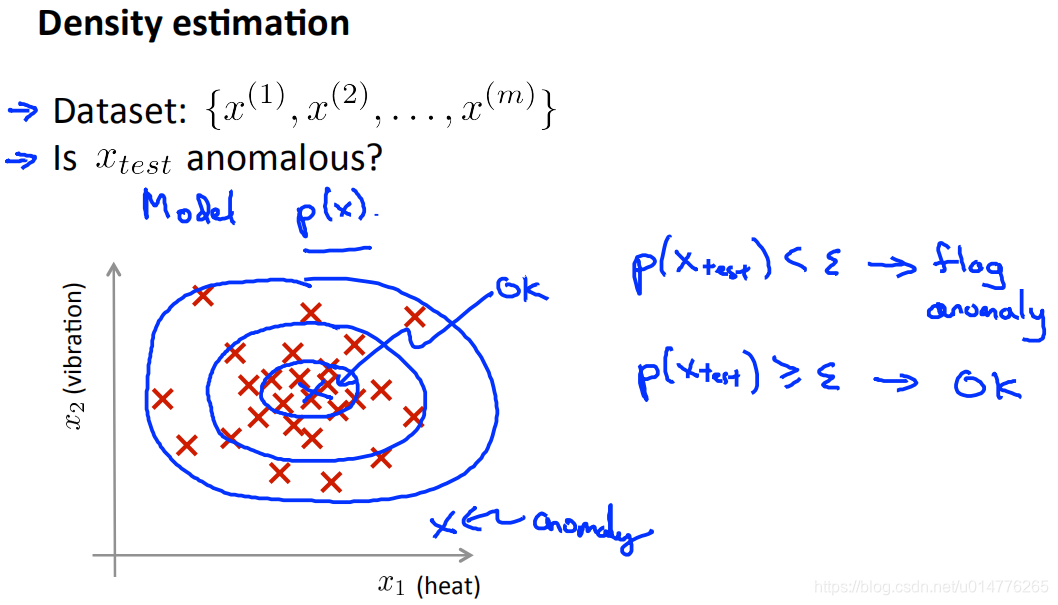
那么假如我们的测试集 xtest概率p低于阈值ε,那么则将其标记为异常。

应用场景:
其中一个应用为欺诈检测。假设你有很多用户(工厂、网店等),每个用户都在从事不同的活动,那么你可以将他们的活动记为不同的特征变量,通过建立模型来表示用户各种可能性,然后可以根据这个模型来发现奇怪的用户,进一步筛选出有异常行为或者欺诈行为的用户。
还有就是工业生产中的质量检测。
还有数据中心的计算机监控。在管理一个计算机集群或者数据中心的时候,往往有很多计算机一起工作,那么我们可以为每台计算机计算特征变量,来衡量计算机的内存消耗、硬盘访问量或者CPU负载等复杂的情况。
练习题:

选择(B)
标记了太多异常的值(很多数据不是异常的数据却被当做是异常的),代表当前筛选范围过大。故应该减少阈值ε,这样被分入异常值的个数会减少。
Gaussian Distribution高斯分布(normal distribution 正态分布)
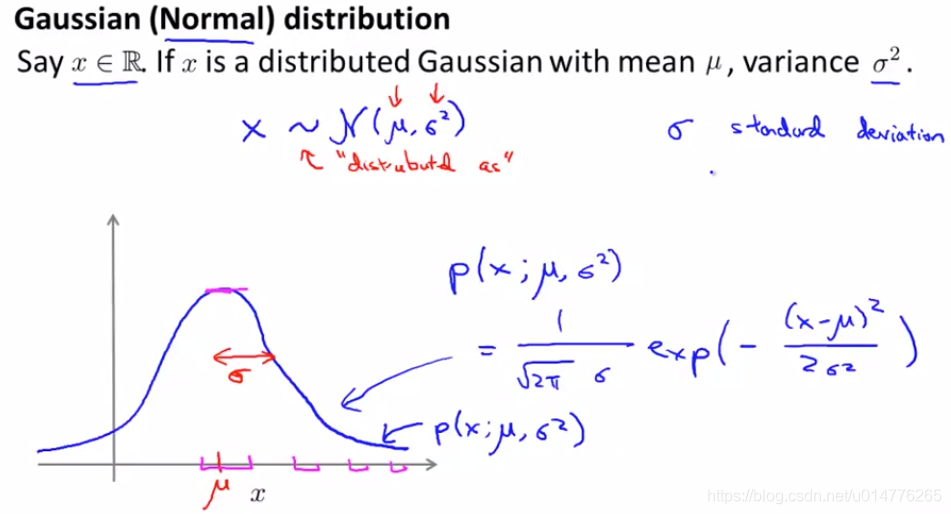
下面我们用高斯分布来推导一个异常检测的算法,在此之前,我们先复习一下什么是高斯分布(正态分布)。
假如 x服从高斯分布,那么我们将表示为:
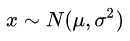
其分布概率为:
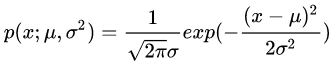
。其中μ 为期望值(均值), ? 2为方差。
其中,期望值 μ决定了其位置,标准差 ?决定了分布的幅度。当
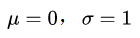
时的正态分布是标准正态分布。
高斯分布举例

其中μ决定了图像对称轴的位置,?决定了对称轴到曲线的宽度(距离)。由于整体概率之和应为1,故对称轴到曲线更宽(即?越大),其高度越低。
练习题:
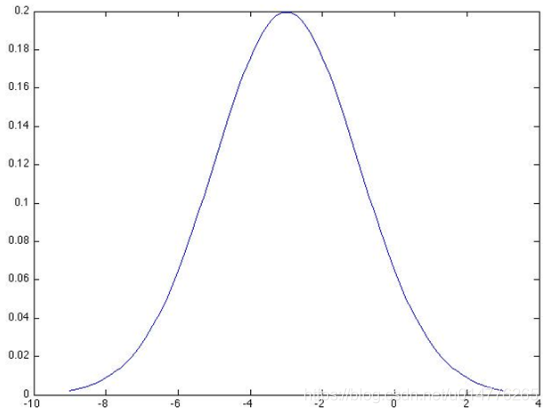

选择(C)
图中可以看出μ为-3,根据查表此时?为2
Density estimation概率密度估计

假如我们有一组m个无标签训练集,其中每个训练数据又有n个特征,那么这个训练集应该是m个n维向量构成的样本矩阵。
我们要从数据中建立一个 p(x)的概率模型。
我们假定每一个特征x1到 xn均服从正态分布,则其模型的概率为:
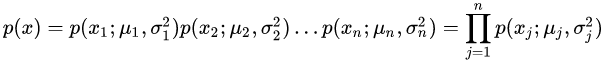
(我们用
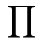
表示连乘的意思)。
练习题:
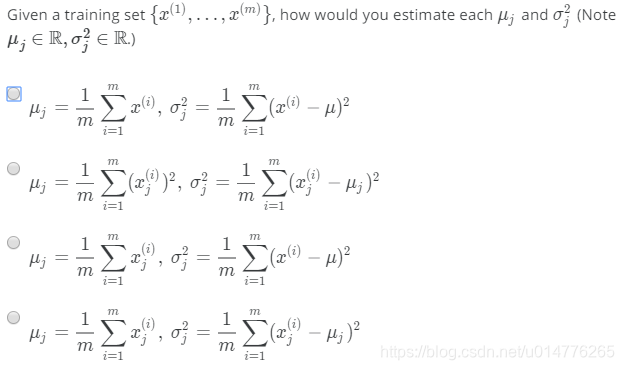
选择(D)
每一个特征都有一个均值,应计算每一个特征的均值与方差,且特征数为uj∈R。故,∑xj(i)为正确。
Anomaly detection algorithm 异常检测算法

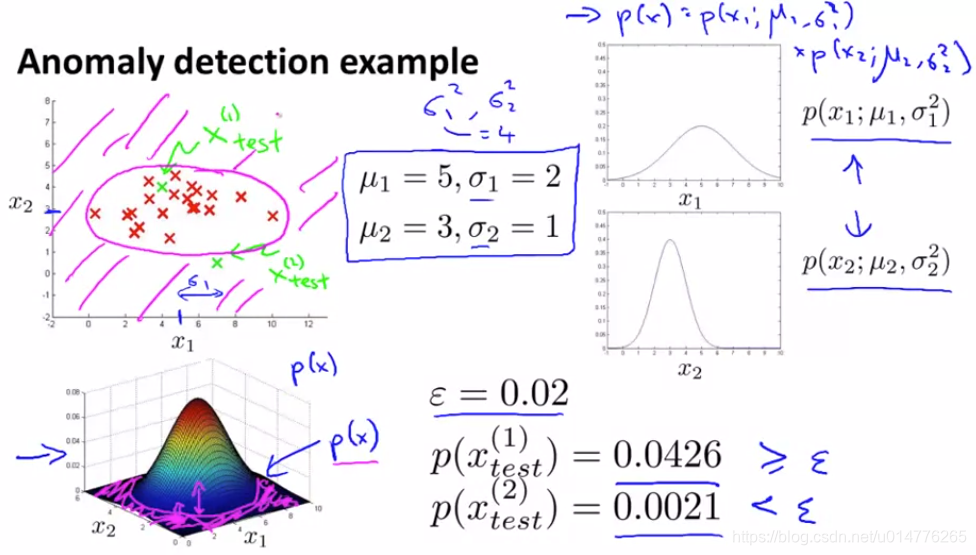
选择那些你认为可能指示出是否为异常值的特征。计算这些特征的均值μ与方差?2。然后代入正态分布求出概率。如果其概率小于ε,则认为是异常值。
Developing and Evaluating an Anomaly Detection System开发和评估异常检测系统


通常我们将数据集分为60%训练集(非标签数据),20%交叉验证集(其中一半的负例数据),20%测试集(其中另一半的负例数据)

所以对于数据倾斜大的数据集,我们一般采用precision和recall来评价算法的好坏。即采用F1-score来综合评价precision和recall的表现。我们采用在交叉验证集上评估算法,并做出决定。比如使用什么特性,使用何种epsilon。当我们选择了一组特征,当我们找到满意的epsilon值时,就可以在测试集上对算法进行最终评估。
练习题:

选择(C)
C.因为数据倾斜很大,所以算法总是会预测出y=0,其就会有很高的accuracy准确度。
Anomaly Detection vs. Supervised Learning选择合适的场景对于异常检测算法与监督学习算法

当正样本(y=1表示异常的样本)的数量很少,负样本很多的时候,使用异常检测算法会比较好。对于监督学习,一般来说,其正负样本的数量都应该是比较大的。
在异常检测算法中,正样本里面往往会有很多不用的异常种类,例如飞机引擎异常的原因可能会有成千上万种,所以对负样本进行建模得出的 p(x)比较简单。因为对于异常检测算法,只有少数正样本,因此学习算法并不可能从这里面学到太多东西,那么相反从负样本中可获得更多大量的信息。(Anomaly Detection异常检测算法相当于只对负样本进行建模,其余的分类都是正样本)
而对于有大量正样本和负样本的数据,并且需要对这些样本进行分类,我们偏向于选择监督学习算法。例如垃圾邮件的分类,我们既有大量的垃圾邮件数据也有大量的非垃圾邮件数据。
所以,对于之前我们提到的偏斜类(Skewed Classes)问题,我们往往选择异常检测算法。
练习题:

选择(A,C)
分析:
A.检测发电厂哪里出现问题。
B.预测明天的发电量,用监督学习更好。
C.监测公司的人不正常的地方。
D.检测进入公司的人是男还是女,监督学习中的分类问题。
A,C中异常情况都为个别,故正样本十分少
Choosing What Features to Use选择要使用的特征

假如我们的数据看起来不是很服从高斯分布,我们可以通过对数、指数、幂等数学变换让其接近于高斯分布。(如果不是高斯分布也能使用Anomaly Detection异常检测算法。只是效果来说,数据集分布为高斯分布时,其算法运行效果更好)
octave中调整数据集为高斯分布
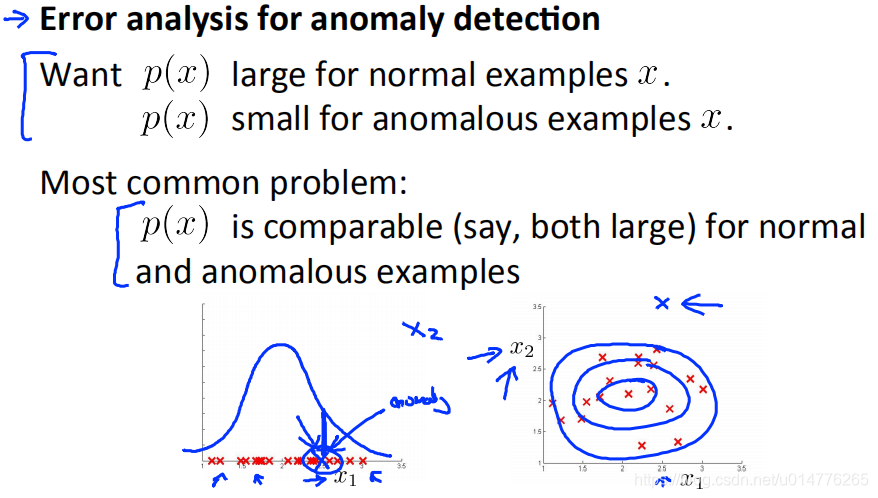
但是一个常见的问题是 p(x)对于正常样本和异常样本的值都很大。
举个例子,我们只用一个特征变量 x1来拟合算法,其高斯分布的图像如上图左下图所示。我们现在有一个异常的样本(绿色样本),但是其在 x1这个特征值里面是没有问题的,所以被分为正常样本的概率就很高。但是在这个特征里面没问题不一定说明它就是没问题。假如我们再添加一个特征 x2拟合,那么该异常样本虽然在 x1特征中正常,但是通过两个甚至更多特征的结合,该异常样本p(x)的值就会偏低。
看看算法未能标记的正例数据,看看这是否能创建一些新特性。因此,找到飞机引擎的一些不寻常之处,并使用它来创建一个新的特性,这样,有了这个新特性,就可以更容易地将异常与好的例子区分开来。

在异常值中选择,其数值异常大或异常小值的特征。
举例:
但是现在,假设我怀疑其中一个故障案例,假设在我的数据集中,我认为CPU负载网络流量趋向于线性增长。也许我在运行一堆Web服务器,所以,如果我的一个服务器为很多用户提供服务,我有很高的CPU负载,并且有很高的网络流量。
因此,如果其中一台机器有非常大的CPU负载,但没有那么多的网络流量,那么在这里,X5将呈现异常大的值,因此这将是一个有助于异常检测捕获的特性,一种特定类型的异常。你也可以获得创造性,并提出其他功能。比如我有一个X6的特性,它的CPU负载除以网络流量。
练习题:

选择(B)
B.增加新的特征来区分正负例样本
多元高斯分布(Multivariate Gaussian distribution):
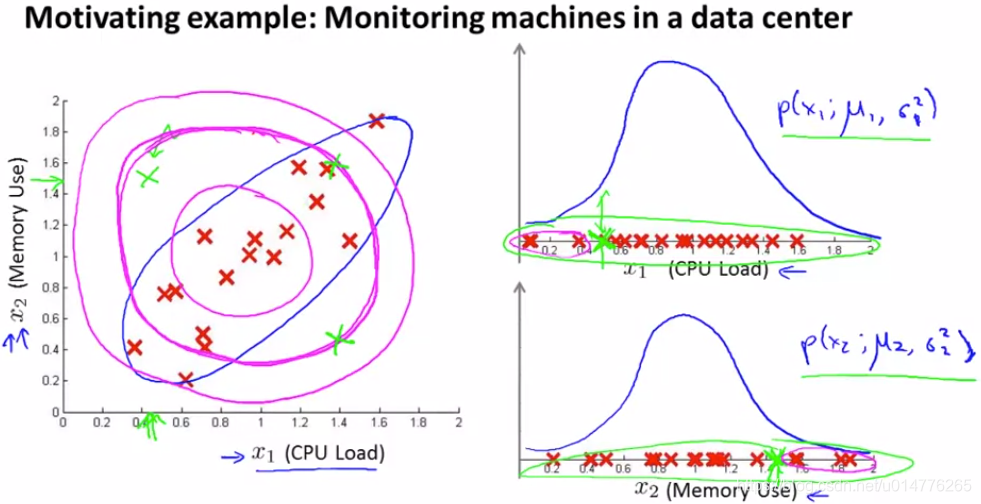
我们以数据中心的监控计算机为例子。x1 是CPU的负载,x2 是内存的使用量。其正常样本如左图红色点所示。假如我们有一个异常的样本(图中左上角绿色点),在图中看很明显它并不是正常样本所在的范围。但是在计算概率 p(x)的时候,因为它在 x1 和 x2的高斯分布都属于正常范围,所以该点并不会被判断为异常点。
这是因为在高斯分布中,它并不能察觉在蓝色椭圆处才是正常样本概率高的范围,其概率是通过圆圈逐渐向外减小。所以在同一个圆圈内,虽然在计算中概率是一样的,但是在实际上却往往有很大偏差。
所以我们开发了一种改良版的异常检测算法:多元高斯分布。

我们将不每一个特征值都分开进行高斯分布的计算,而是作为整个模型进行高斯分布的拟合。
其概率模型为:
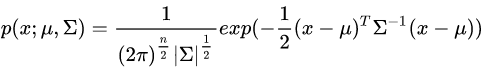
(其中 |∑| 是 ∑ 的行列式)。
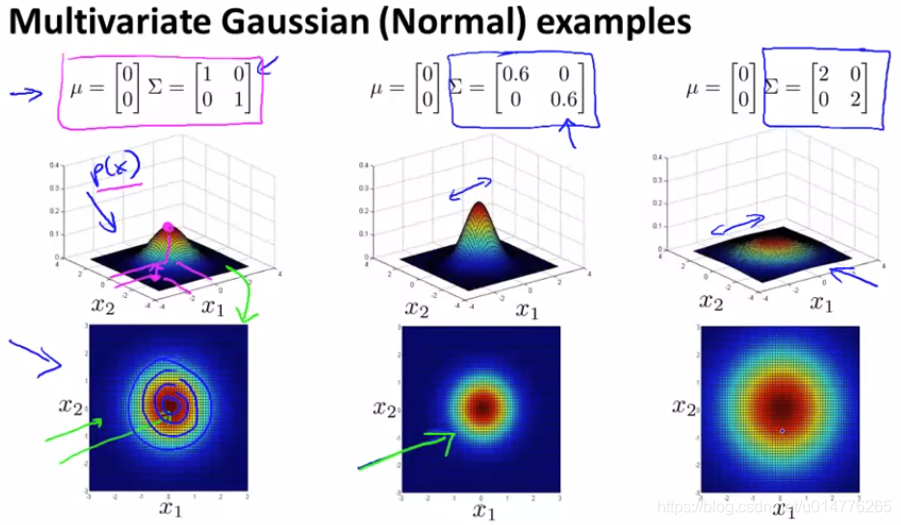
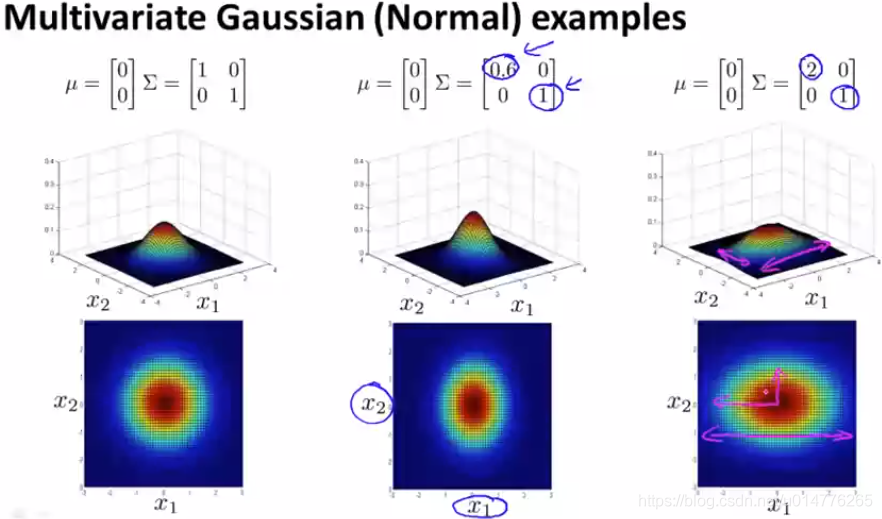
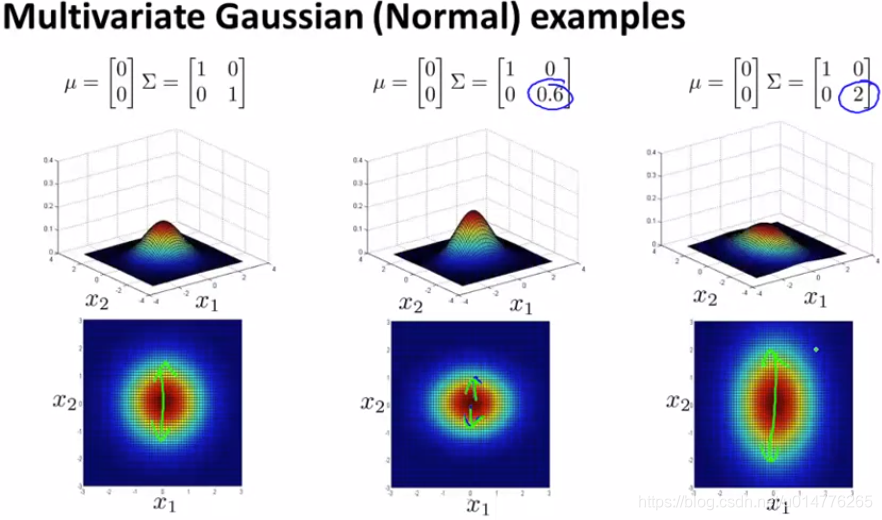
∑中第一个数字是衡量 x1 的,假如减少第一个数字,则可从图中观察到 x1 的范围也随之被压缩,变成了一个横椭圆。假如减少x2的值,其x2的范围被压缩,变成了一个纵椭圆。
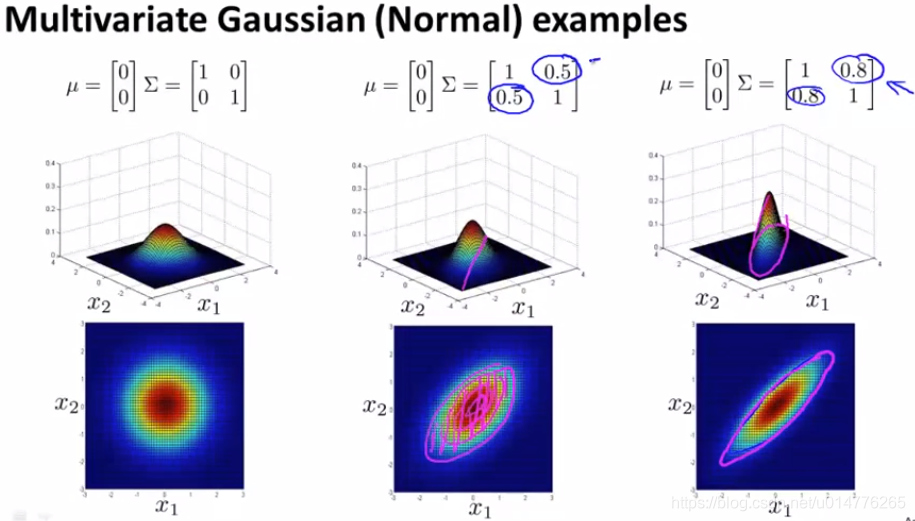
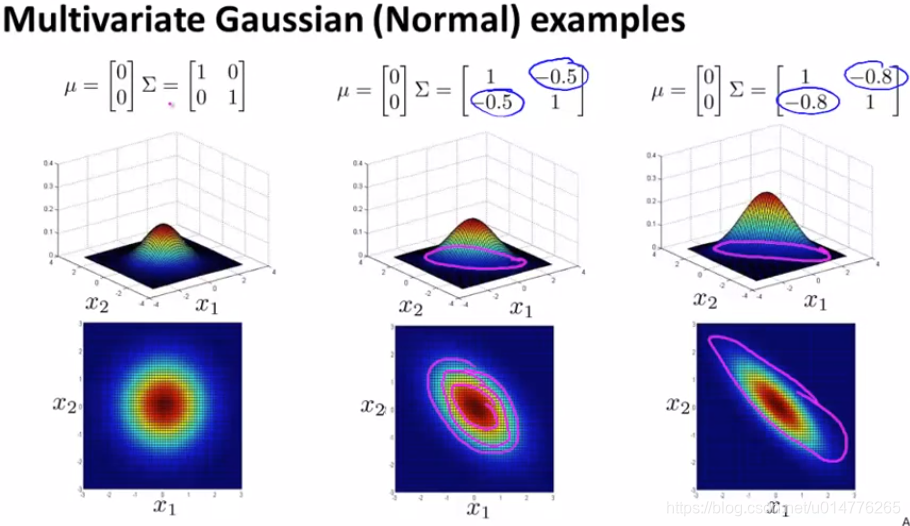
多元高斯分布还可以给数据的相关性建立模型。假如我们在非主对角线上改变数据(如图中间那副),则其图像会根据 y=x 这条直线上进行高斯分布。非主对角线的数据值越大,其图像越薄。反之,其值越小,图像越厚。矩阵中副对角线为正数,改变的是图像中主对角线的薄厚。矩阵中副对角线为负数,改变的是图像中副对角线的薄厚。
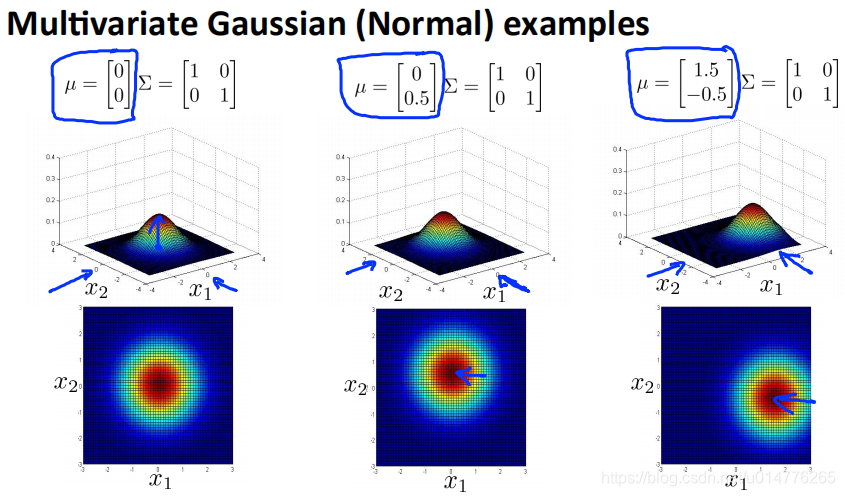
μ的值是改变其中心点的位置。第一个μ代表x轴位置,第二个μ代表y轴上的位置
练习题:
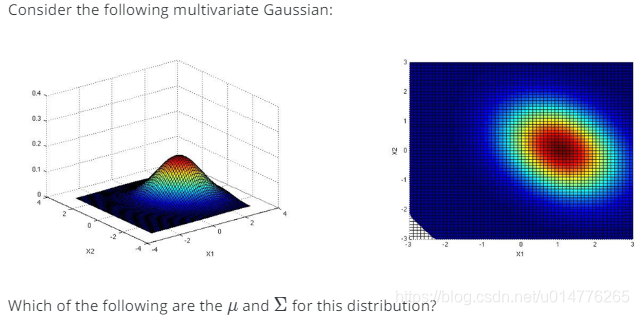
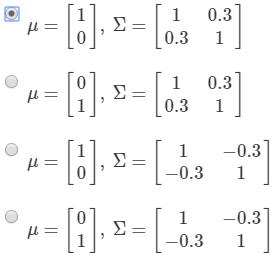
选择(C)
C.图像中中心点靠近x轴正半轴,且图像倾斜方向为副对角线。故其∑矩阵的主对角线上元素应为负值。
Anomaly Detection using the Multivariate Gaussian Distribution基于多元高斯分布的异常检测

多元高斯分布中的∑参数求法,相似于PCA降维算法中求和矩阵的求法。
PCA降维算法中的∑求法:
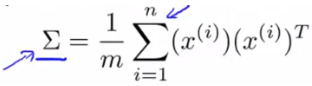
多元高斯分布的异常检测算法如下:

对于x轴或y轴轴对称的等高图图形,其∑矩阵的特征为其主对角线为各个特征的方差。其余部分(除了主对角线之外部分),都为0。
注意多元高斯分布:
其p(x)为各个特征之间的乘积,不允许对于其他组合类型的特征乘积进行建模
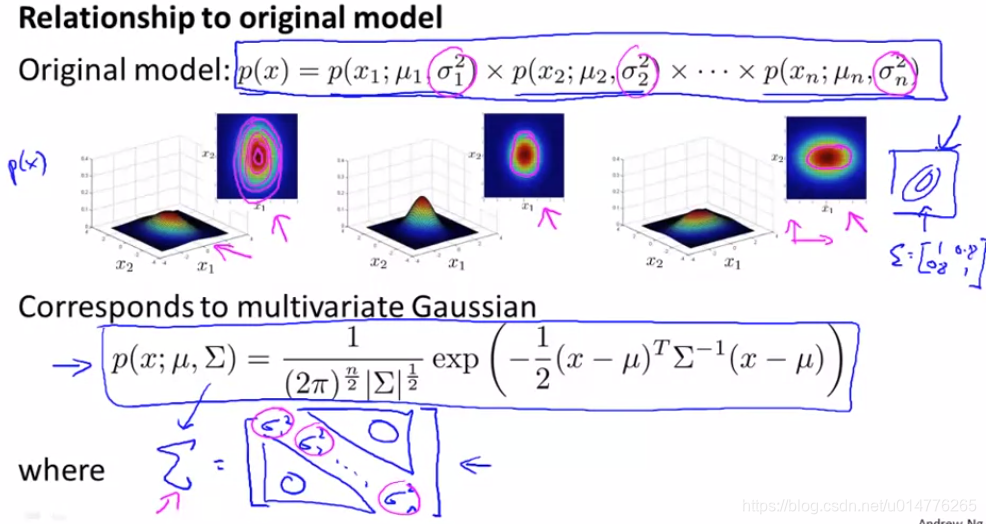
原模型与多于高斯模型进行对比:

1.如果两个特征之间有关联,(相关联的特征对于结果有影响)原模型需要手动添加组合的特征。而多元高斯函数可以自动计算出两个模型之间的关系。
2.原模型计算简便,并且对于很大的特征数量也能进行拟合。多元高斯函数其计算消耗大。(由于其模型中需要计算∑矩阵的逆矩阵)
3.假如训练集数量很小,原模型也能进行拟合。而多元高斯函数对于m>n的情况和∑矩阵不可逆的情况无法进行拟合。(当出现不可逆的情况很有可能是:m<n或有相等同的特征,如:x1=x2(x1与x2想等同),x3=x4+x5(x3与x4,x5相等同))
练习题:

选择(A,C,D)
A.正确,当多元高斯分布的等高线图为轴对称时,原模型对应于多元高斯分布(两个模型相等同)
B.错误,使用多元高斯模型时,其m应该大于n。(数据集的条数大于特征个数)
C.正确,多元高斯函数能够自动计算不同特征之间的关系
D.正确,原模型其计算便捷,并且很大的特征数量也能进行拟合。
测试题:
选择(A,C)
说明: anomaly detection 是通过高斯概率去判断的, 其中三西格玛准则:3σσ 0.9974,超过3σσ认为是不正常.
A. 给出病人的信息,区分哪些人有不寻常的病. 正常的病的概率+不正常的病的概率=100%, 并且正常与不正常的病不是事先知道,是统计完定个标准,例如认为在3σσ内是正常的,在3σσ外是不正常的. 正确 *
B.给出刷卡记录来区分哪些交易用于食物 交通 及衣服.不能用于多分类. 不正确
C.给出刷卡记录来判断哪些是不正常的交易. 刷卡记录符合正态分布. 正确 *
D. 通过人脸的照片,去判断这个脸是不是famous. 要判断必须得有所有的famous的人,不在这些famous的人里面就是非famous的人,即famous的人符合二项分布(只有0和1),不符合高斯分布. 不正确

选择(B)
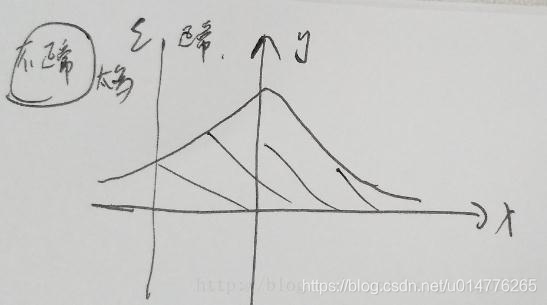
如上图所示, 阴影部分是正常的, 非阴影部分是不正常的,现在不正常的太多了,要增大阴影部分的面积怎么办? 不就是向左称动ε嘛,即减小ε

选择(A)
用正态分布去判断一个飞机引擎是正常的还是不正常的,现在选取了两个特征:振动强度
和产生的发热量,这两个特征的概率都在0-1之间,并且没有0值;对于正常的引擎来说,振动强度与产生的发热量是正相关的;但对于不正常的引擎振动强度很大但是发热量越很小,虽然不正常但是引擎振动强度也没有超出正常范围
关键点是: 正常时震动小发热量小;异常时震动小发热量大,所以出异常时这个比例值将会非常大,所以选A
关键点是: 不正常状况下:引擎振动强度也没有超出正常范围,所以用加乘都看不出异常来.

选择(B,D)
A.错误。如果您正在开发异常检测系统,则无法使用已标记数据来改进系统。错。标记数据更有利于改善算法。
B.正确。如果你没有任何标记的数据(或者所有的数据都有标签),那么仍然可以学习,但是评估系统或选择一个好的值可能比较困难。
C.错误。如果你有一个很大的标记训练集,有许多积极的例子和许多负面的例子,异常检测算法很可能会执行的监督学习算法,如支持向量机一样好,错,异常检测算法对偏斜类问题处理更好。
D.正确。当为异常检测系统选择特征时,寻找那些异常大或小值的特征(主要是)异常示例是个好主意。
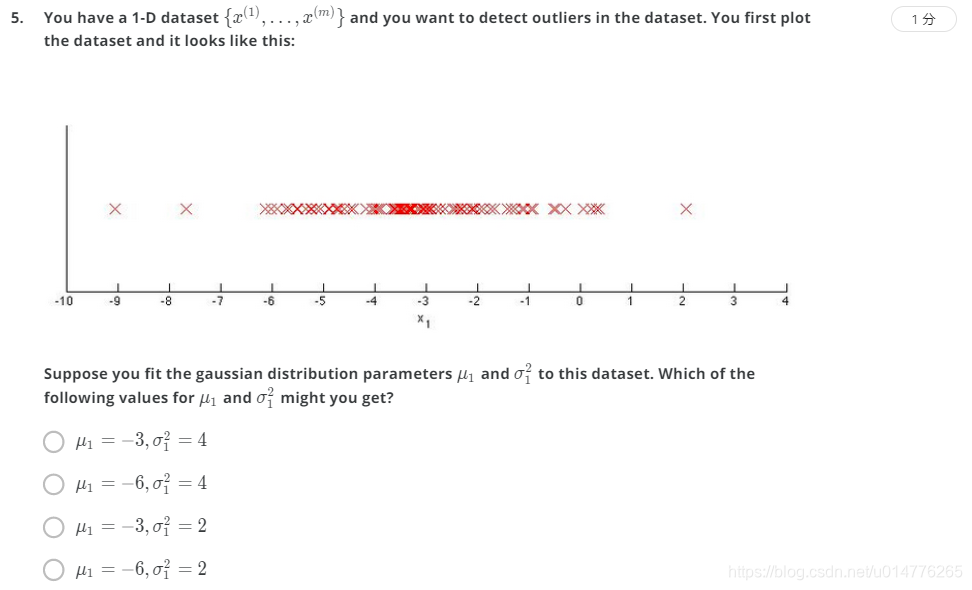
选择(A)
解析:
对称轴位于-3的位置。

大部分点位于[-5,-1]区间之间。
而根据求方差公式:

故:
4=1/2×(-5+3)2×(-1+3)2=1/2×8=4
故方差应为4。














 5947
5947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









