




 该博客详细解析了ggplot2中的映射(mapping)功能,包括颜色和形状类型的映射,如color、fill、shape等,以及位置类型映射如x、y、xmin、xmax等。文章介绍了映射的过程、标尺设定、图例生成以及非映射设置,并通过实例展示了映射在数据分组、颜色标尺调整和图例创建等方面的应用。此外,还提到了特殊类型映射如group和order,以及如何处理不同数据类型的映射问题。
该博客详细解析了ggplot2中的映射(mapping)功能,包括颜色和形状类型的映射,如color、fill、shape等,以及位置类型映射如x、y、xmin、xmax等。文章介绍了映射的过程、标尺设定、图例生成以及非映射设置,并通过实例展示了映射在数据分组、颜色标尺调整和图例创建等方面的应用。此外,还提到了特殊类型映射如group和order,以及如何处理不同数据类型的映射问题。
作图前的数据准备工作不仅仅指原始数据的收集,还包括数据外观的整理,这些工作对后续的作图无疑十分重要。和其他作图方法相比,ggplot2的优点之一就是把数据整理融合到了作图过程中,替用户分担了数据整型的部分工作。ggplot2数据层面的操作包括映射和分面。先说映射。
1 映射的类型
前面我们已经了解到ggplot对象的data项存储了整个数据框的内容,而“映射”则确定如何使用这些数据。
ggplot2按照图形属性提供了以下可用映射类型:
- 颜色类型映射:包括 color(颜色或边框颜色)、fill(填充颜色)和 alpha(透明度)
- 形状类型映射:包括 linetype(线型)、size(点的大小或线的宽度)和 shape(形状)
- 位置类型映射:包括 x, y, xmin, xmax, ymin, ymax, xend, yend
- 特殊类型:包括两类,一类是指定数据分组和顺序的映射group和order,另一类是字符串映射。
前两种类型是经典的美学属性映射,第三类的x和y映射也常规,第四类很特别,尤其是字符串映射,很另类,其他类型的映射都可以用aes函数指定,但H.W.为字符串映射专门造了个函数:aes_string。不知道他对字符串特别关照还是实在想不出其他解决方案。
2 颜色和形状类型映射
规律性的东西简单轻松,大家都喜欢;而到处暗藏潜规则、充斥着特例的东西(比如plotrix、perl和中国社会)很杂碎很累人,当然也很让人烦躁和讨厌。ggplot2中颜色和形状这两类映射最符合台面规则的,即:把数据框的变量和图形的美学属性对应起来。
2.1 映射的过程
先看下面ggplot2的数据diamonds:
library(ggplot2) set.seed(100) d.sub <- diamonds[sample(nrow(diamonds), 500), ] head(d.sub, 4)
## carat cut color clarity depth table price x y z ## 16601 1.01 Very Good D SI1 62.1 59 6630 6.37 6.41 3.97 ## 13899 0.90 Ideal D SI1 62.4 55 5656 6.15 6.19 3.85 ## 29792 0.30 Ideal D SI1 61.6 56 709 4.34 4.30 2.66 ## 3042 0.30 Very Good G VS1 62.0 60 565 4.27 4.31 2.66
作图首先要指定x和y数据,即建立数据框变量和x/y之间的映射:
p <- ggplot(data=d.sub, aes(x=carat, y=price))
作出散点图:
theme_set(theme_bw()) p + geom_point()
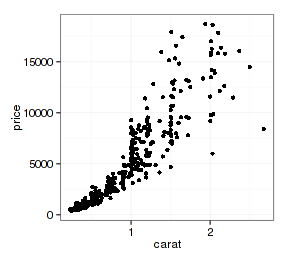
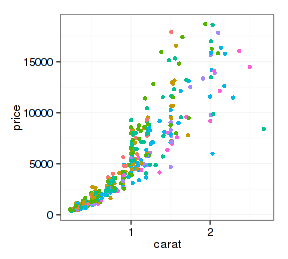
如果还要建立其他映射,比如用钻石颜色(color)分类数据确定点的颜色,图形外观就会发生变化(为方便说明,先去掉图例):
p + geom_point() + aes(color=color) + theme(legend.position=c(2,2))
ggplot2映射的过程可以用plot函数作图步骤进行分解,它包含三方面的操作(不包括图形页面设置):
- 数据分组
- 设定颜色标尺
- 按颜色标尺指定每组数据的颜色
# 设定颜色标尺 levs <- levels(d.sub$color) cl <- rainbow(length(levs)) # 页面设置 par(mar=c(3,3,0.5,0.5), mgp=c(1.5, 0.5, 0), bg="white") plot(d.sub$carat, d.sub$price, type='n', xlab="carat", ylab="price") i <- 1 for(lev in levs){ # 数据分组 datax <- d.sub[d.sub$color==lev, ] # 作图并指定数据点颜色 points(datax$carat, datax$price, pch
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









