






 本文介绍了自动语音识别(ASR)和文本转语音(TTS)技术。ASR主要涉及语音特征提取,如LogMelSpectrum,以及使用Encoder-Decoder模型进行识别。同时,提到了ConnectionistTemporalClassification(CTC)在处理序列对齐问题上的作用。文章还讨论了不同ASR任务的难度和噪声对识别的影响。
本文介绍了自动语音识别(ASR)和文本转语音(TTS)技术。ASR主要涉及语音特征提取,如LogMelSpectrum,以及使用Encoder-Decoder模型进行识别。同时,提到了ConnectionistTemporalClassification(CTC)在处理序列对齐问题上的作用。文章还讨论了不同ASR任务的难度和噪声对识别的影响。
阅读《Automatic Speech Recognition and Text-to-Speech》,整理了如下关于ASR的笔记
1. 引入
- 语音识别(automatic speech recognition,ASR):输入waveform,输出对应的文字
- 文字转语音(text-to-speech,TTS):输入文字,输出语音
2. ASR
2.1 ASR Tasks
| 划分标准 | 说明 |
|---|---|
| 任务目标的不同 | 识别yes or no、识别数字、识别对话,ASR tasks不同导致对应词表大小不同 |
| 说话者交谈对象不同 | 如果说话者对机器说话,比如朗读课文,这样没有听众互动的,会比较简单;最困难的是两个说话者互相交谈 |
| 是否有噪声 | 没有噪声的语音会更容易识别 |
2.2 特征提取
语音识别的第一步是基于waveform提取特征,也就是在每一个小时间窗口提取对应信号,最常用的特征就是Log Mel Spectrum
1.模拟表示(比如麦克风的模拟电信号)转化为数字信息
- 采样(sampling):**采样率(sampling rate)**是指每秒从连续信号中提取并组成离散信号的采样个数。对于电话语音,采样率可为8000HZ;麦克风语言,采样率可用16000HZ。
- 振幅:振幅测量值是整数,8位(8 bit,即1字节,取值 -128~127)或16位(16 bit,即2字节,取值-32768 ~ 32767)
-
从数字信号中,提取小窗口的频谱特征
- 认为一个小窗口里的信号是平稳的(stationary),也就是说这个小窗口的特征是一个常数
- 从每个窗口(each window)提取的语言称为帧(frame)。这个窗口有三个参数:frame size(窗口大小,以毫秒为单位)、frame stride(也称为shift或offset)、shape(窗口形状,相较于矩形,Hamming window更常用)。基于如下式子提取特征
$$y[n] = s[n] w[n]$$
这里 s [ n ] s[n] s[n]表示时间点 n n n的信号值(value of the signal)、 w [ n ] w[n] w[n]表示这个时间点的窗口值(value of the window)。
-
离散傅里叶变换(Discrete Fourier Transform)
- 基于离散傅里叶变提取频谱信息
输入 x [ 0 ] , x [ 1 ] , . . . x [ N − 1 ] x[0], x[1], ...x[N-1] x[0],x[1],...x[N−1],离散傅里叶变换定义为
X [ k ] = ∑ n = 0 N − 1 x [ n ] e − j 2 π N k n X[k]=\sum_{n=0}^{N-1}x[n] e^{-j \frac{2\pi}{N}kn} X[k]=n=0∑N−1x[n]e−jN2πkn
其中复变函数欧拉公式 e j θ = cos θ + j sin θ e^{j\theta}=\cos\theta + j\sin\theta ejθ=cosθ+jsinθ
- 基于离散傅里叶变提取频谱信息
-
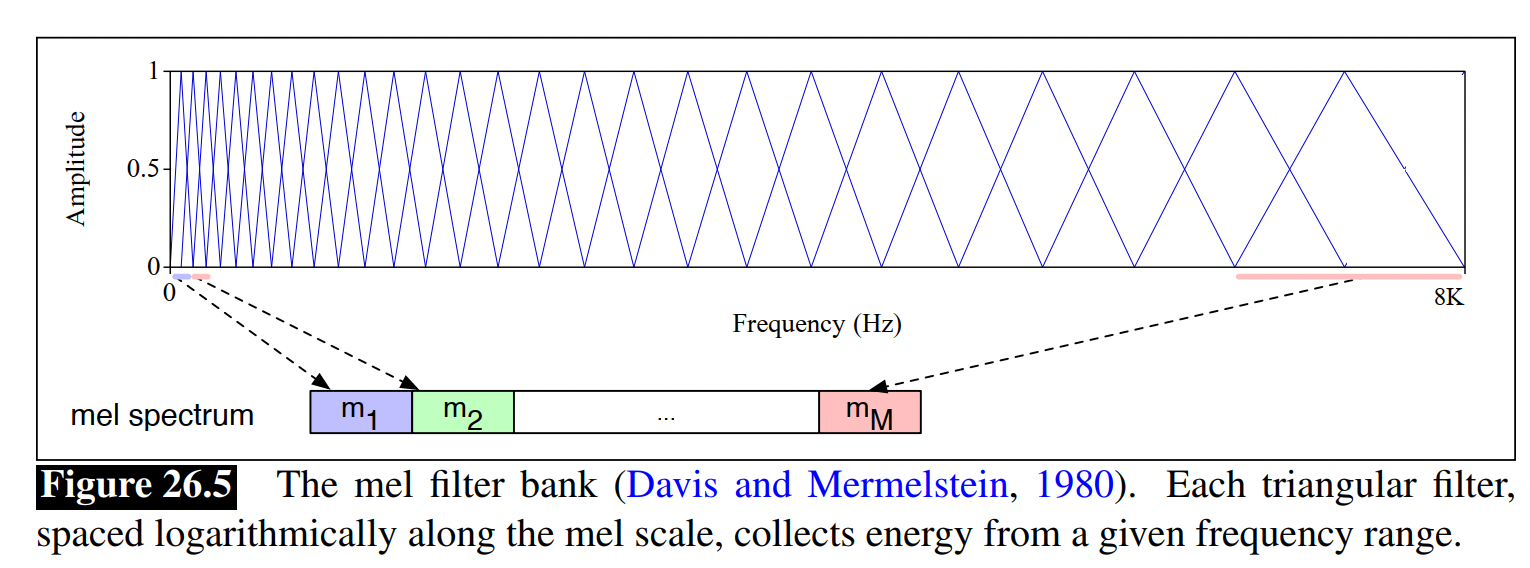
梅尔滤波器 Mel Filter Bank和 Log
- 直觉:人类不是对所有频带(frequency bands)都敏感,人对高频信息(如摩擦噪声)没那么敏感
- 梅尔(mel):音高单位
- mel frequency:可以通过对数变换,从原始声学频率计算mel频率
m e l ( f ) = 1127 ln ( 1 + f 700 ) mel(f) = 1127\ln (1+\frac{f}{700}) mel(f)=1127ln(1+700f)
2.3 ASR模型
2.3.1 encoder-decoder speech recognizer
(1)输入输出:输入特征(这里是指log mel spectral features),输出对应字符
(2) 模型:encoder- decoder
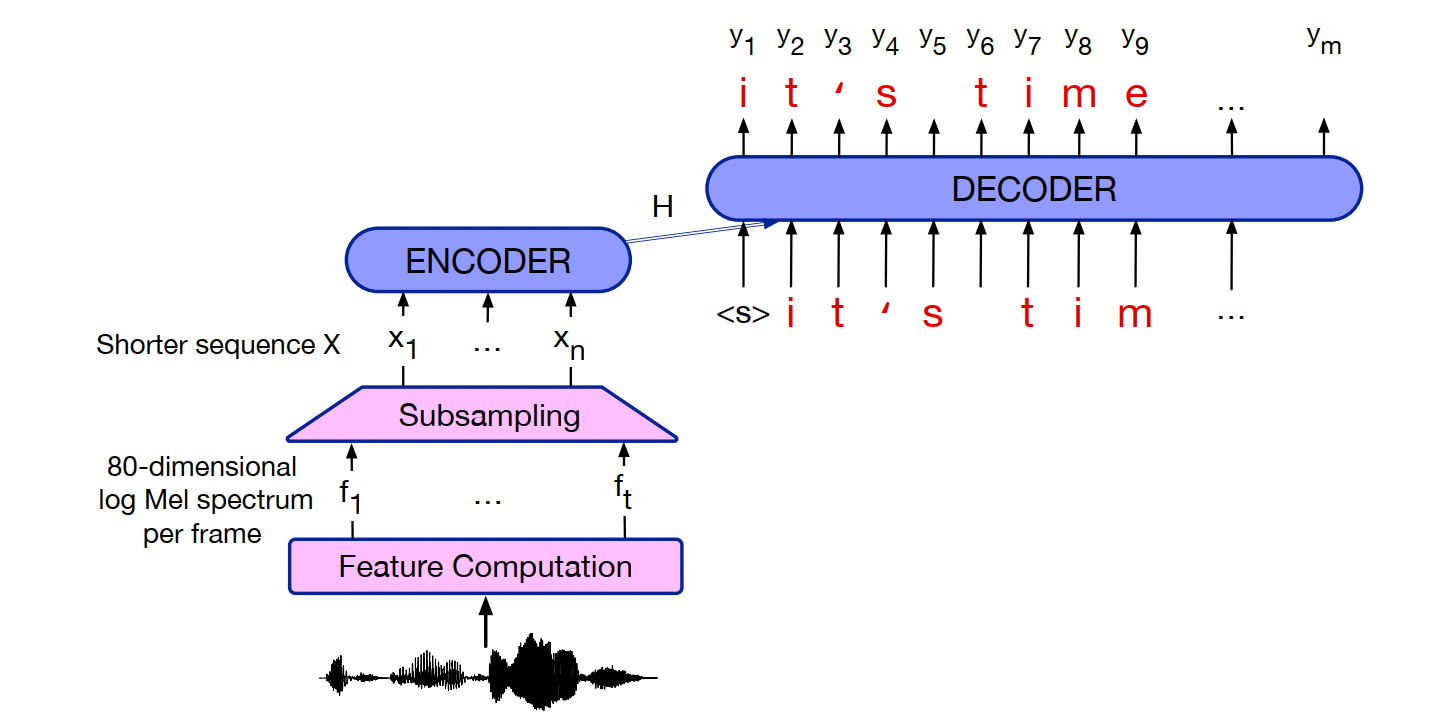
- 输入这里会用subsampling方式来缩短输入的序列长度
- 引入预训练好的语言模型,来提升效果。一个简单方式是先用encoder-decoder模型得到n-best hypothesis,然后用语言模型来打分
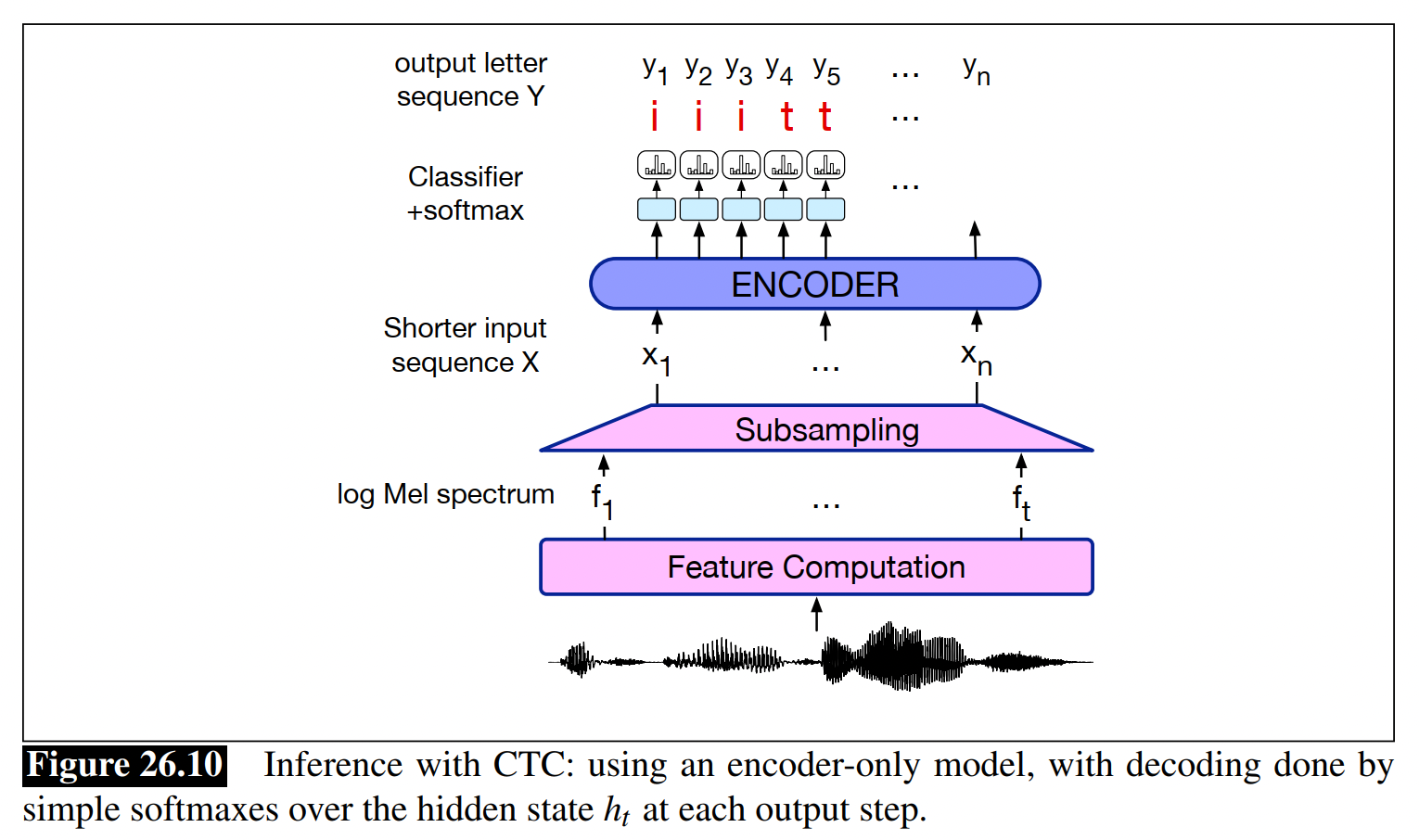
2.3.2 Connectionist Temporal Classification (CTC)
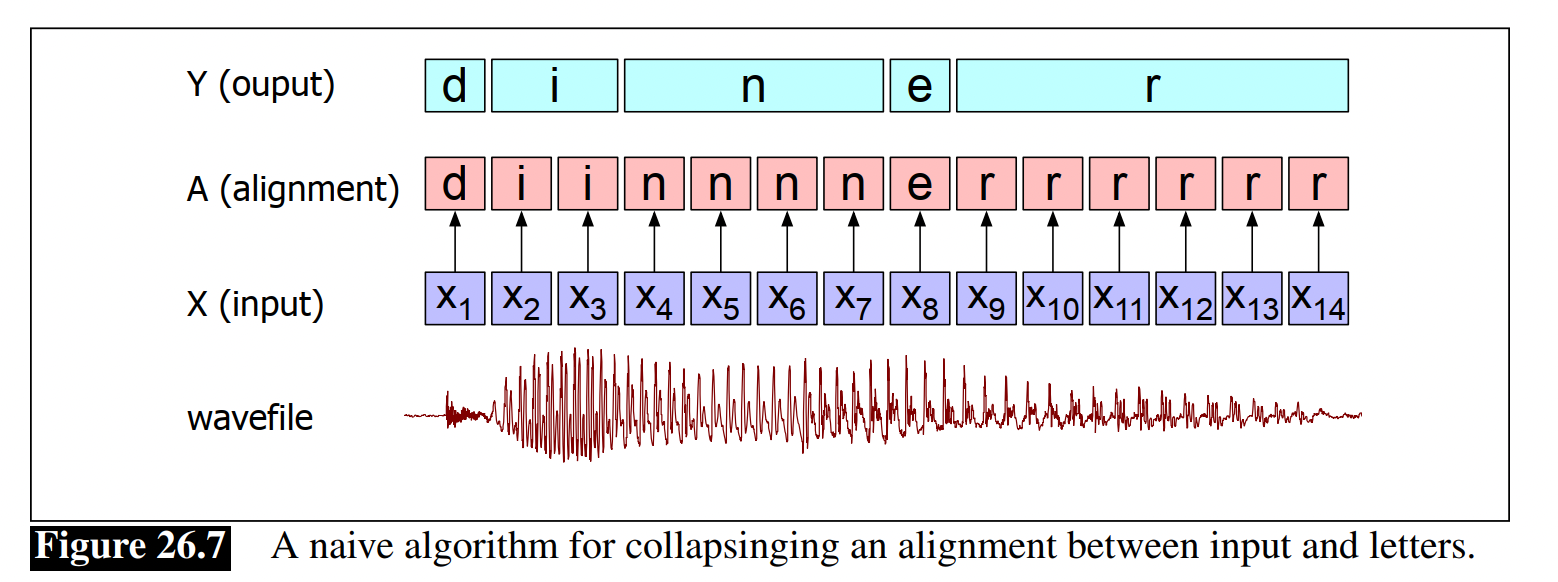
(1) 直觉:对于每一个frame输出一个字符(character),使得输出的序列长度和输入的长度相同,然后再用一个函数合并相同的letters,最后得到一个更短的序列
(2) 基于输出的序列怎么合并,得到一个更短的序列
- 直接去掉连续的重复字符
- 引入空格(blank),然后去掉重复字符和空格
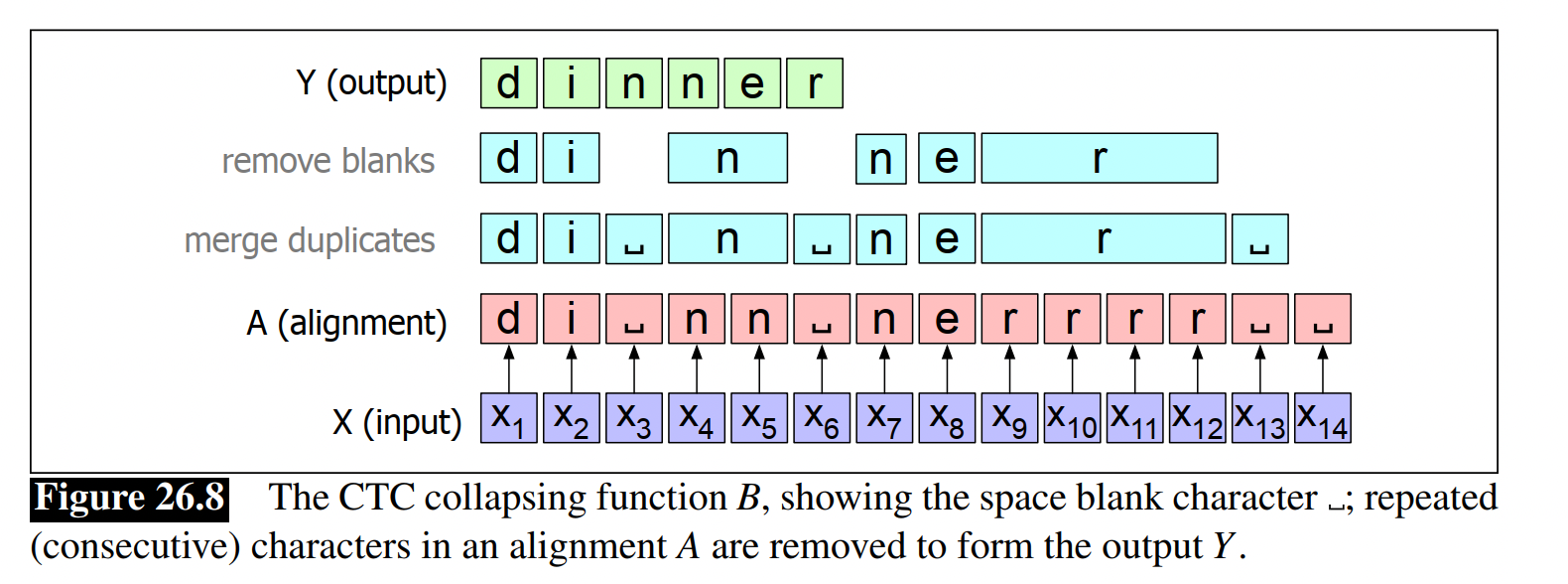
- CTC模型















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









