







本文默认以及安装了Python、pip、conda、env...之类基础环境;不做赘述...
环境及其依赖
环境
pip --version:25.0.1
python --version:3.12.3
cuda:12.4
服务器AutoDL
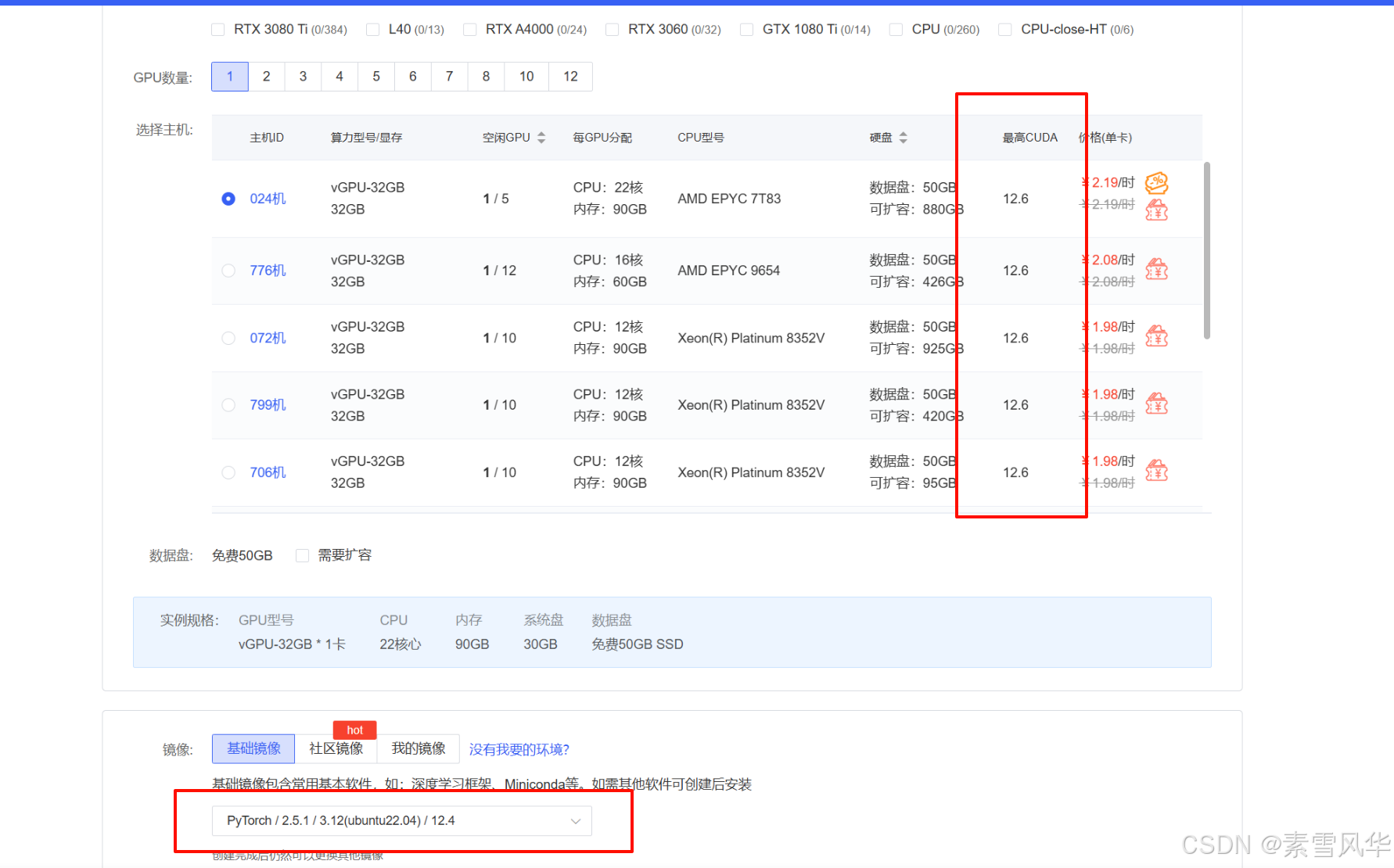
本文基于AutoDL(算力云:https://www.autodl.com/),创建购买服务器流程省略....
需要注意的是看下服务器支持的CUDA最高版本,然后选择镜像的时候选择低于最高CUDA版本即可...如下图。
环境准备
1、升级pip
python -m pip install --upgrade pip ### 之所以要升级,因为有的服务器pip版本太低~拉下载的依赖可能会不兼容...
2、安装依赖:下面命令会安装最新依赖
pip install torch transformers[torch] datasets modelscope peft accelerate tiktoken bitsandbytes evaluate matplotlib seqeval
---PS:有时候在换新的服务器的时候,可能由于cuda()、python、pip、nvidia-smi等版本原因,会产生版本冲突、不适配的问题,所以最好固定版本:
比如使用下面固定版本的命令: ------ 请不要在这个环境下面使用LLaAa-Factory微调框架---这个框架和下面的部分依赖有冲突....会报很多稀奇八怪的错误...。
pip install torch==2.5.1+cu124 datasets==3.2.0 modelscope==1.23.1 peft==0.12.0 accelerate==1.2.1 tiktoken==0.9.0 bitsandbytes==0.45.3 evaluate==0.4.3 matplotlib==3.9.2 transformers==4.48.3 scikit-learn==1.6.1 swanlab==0.4.9 seqeval==1.2.2 rouge_score==0.1.2
模型下载
省略,直接见上一篇下载篇....
微调开始
Step1 引入依赖
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM,BitsAndBytesConfig, DataCollatorForSeq2Seq, TrainingArguments, Trainer,BitsAndBytesConfig
import datasets,transformers,torch
import warnings
warnings.filterwarnings('ignore')
datasets.__version__,transformers.__version__,torch.__version__
-------------------------------------------
输出: ('3.2.0', '4.48.3', '2.5.1+cu124')### 为了方便,我将模型路径和微调数据都统一定义
# 你要微调的模型,本地路径
model_path = './models/ZhipuAI/glm-4-9b'
# model_path = './models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B'
# 训练完成后,你要保存的路径
output_path = "./Lora/Lora_GLM_4_9b_V1"
# 要训练的数据集(是数据所在目录,不是数据文件名称)
data_dir_path = './data/'Step2 加载数据集
2.1 数据模板
[
{
"instruction": "java是什么?",
"input": "",
"output": "java....."
},
{
"instruction": "c++是什么?",
"input": "",
"output": "c++....."
}
]2.2 加载数据集
# data_dir:数据目录;如果是单个文件,可以设置为data_file即可
raw_ds = load_dataset("json", data_dir=data_dir_path)
# 取出train的数据,有'instruction', 'input', 'output'三个标签
ds = raw_ds['train']
# 验证操作 --- 其实也可以直接使用ds的数据也可以...
# 划分10%作为验证集 也可以将全部数据,也可以不用划分测试数据
test = raw_ds["train"].train_test_split(test_size=0.1)
ds,test,len(ds),ds[:2]
-------------------------------------------
输出:
(Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 1525
}),
DatasetDict({
train: Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 1372
})
test: Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 153
})
}),
1525,
{'instruction': ['java', 'c++'],
'input': ['', ''],
'output': ['java是一种编程语言...', 'c++也是一种编程语言...']})
-------------------------------------------
相关操作:
len(ds) # 打印ds的长度
ds[:2] # 查看ds中前2条数据Step3 数据预处理
3.1 定义tokenizer编码器
# 如果 model_path 是本地模型路径,那么系统会自动加载本地路径
# 如果系统使用了huggingface-cli或者之前下载过该模型那么系统会自动根据加载
# 如果都没有那么系统会自动到huggingface下载模型---需要VPN
tokenizer = AutoTokenizer.from_pretrained("本地模型目录/模型路径名称(比如:Langboat/bloom-1b4-zh)",trust_remote_code=True)
# 根据实际情况是否设置
# 设置 pad_token 如果未定义 需要将pad_token和eos_token设置为一样
# 注意:有时候可能因为模型的不同会报“pad_token和eos_token”不一致错误(比如早期Qwen...)
# ### 如果报错了就将pad_token和eos_token修改为一致即可
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 使用 eos_token 作为 pad_token
# 或者显式设置:tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer
-------------------------------------
输出:
Qwen2TokenizerFast(
name_or_path='D://A4Project//LLM//Qwen2.5-0.5B-Instruct',
vocab_size=151643,
model_max_length=131072,
is_fast=True,
padding_side='right',
truncation_side='right',
special_tokens={'eos_token': '<|im_end|>', 'pad_token': '<|endoftext|>', 'additional_special_tokens': ['<|im_start|>', '<|im_end|>', '<|object_ref_start|>', '<|object_ref_end|>', '<|box_start|>', '<|box_end|>', '<|quad_start|>', '<|quad_end|>', '<|vision_start|>', '<|vision_end|>', '<|vision_pad|>', '<|image_pad|>', '<|video_pad|>']},
clean_up_tokenization_spaces=False,
added_tokens_decoder={
151643: AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151644: AddedToken("<|im_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151645: AddedToken("<|im_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151646: AddedToken("<|object_ref_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151647: AddedToken("<|object_ref_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151648: AddedToken("<|box_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151649: AddedToken("<|box_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151650: AddedToken("<|quad_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151651: AddedToken("<|quad_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151652: AddedToken("<|vision_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151653: AddedToken("<|vision_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151654: AddedToken("<|vision_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151655: AddedToken("<|image_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151656: AddedToken("<|video_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151657: AddedToken("<tool_call>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151658: AddedToken("</tool_call>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151659: AddedToken("<|fim_prefix|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151660: AddedToken("<|fim_middle|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151661: AddedToken("<|fim_suffix|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151662: AddedToken("<|fim_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151663: AddedToken("<|repo_name|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151664: AddedToken("<|file_sep|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
}
)
----------------------------------------
tokenizer相关操作...参考
tokenizer.eos_token # 查看eos_token
输出:'<|endoftext|>'
-----
tokenizer.eos_token_id # 查看eos_token_id
输出:151329
-----
tokenizer.decode(tokenizer.eos_token_id) # 将eos_token_id转为eos_token字符串
输出:'<|endoftext|>'
-----
tokenizer(tokenizer.eos_token) # 将字符串编码
输出:{'input_ids': [151331, 151333, 151329], 'attention_mask': [1, 1, 1], 'position_ids': [0, 1, 2]}
-----
tokenizer(tokenizer.eos_token)['input_ids'] # 取出input_ids
输出:[151331, 151333, 151329]
-----
tokenizer.decode(tokenizer(tokenizer.eos_token)['input_ids']) # 将input_ids解码
输出:'[gMASK] <sop> <|endoftext|>'
-----
tokenizer(tokenizer.eos_token,add_special_tokens=False) # 取消原来自动添加的系统token
输出:{'input_ids': [151329], 'attention_mask': [1], 'position_ids': [0]}
3.2 定义预处理函数
3.2.1 预处理函数的主要作用
1、预处理函数首先负责将原始输入数据“ds”转换成模型可以接受的格式,并用tokenizer编码;
2、如果有的数据没有预处理(比如去掉多余的空格、特殊字符之类)。
问题:我们并不知道这个输入格式时,可以先确定模型类型(LLaMa、ChatGLM、Qwen...),然后查看文档和示例,再利用工具链“apply_chat_template”构造一个tokenizer,再利用model.generate生成完整的示例,最后验证即可。
如果我们在不知道输入格式时,可以直接构造一个apply_chat_template方法来获取模型要求输入的inputs,然后通过model.generate获取模型的输入以及输出,最后通过decode反编码即可。
3.2.2 数据预处理数据模板获取
如下:下面是 ---- 查看某个模型 所接收的数据格式以及输出格式... ---
使用tokenizer.apply_chat_template获取输入,使用model.generate获取模型输出
from transformers import AutoTokenizer,AutoModel,AutoModelForCausalLM
base_model_path = './models/ZhipuAI/glm-4-9b'
tokenizer = AutoTokenizer.from_pretrained(base_model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(
# AutoModelForCausalLM 适配了 AutoModel;
# AutoModelForCausalLM可以加载Chat模型和非Chat模型
# 报错:在加载Qwen2.5-0.5B-Instruct时使用,否则报错“The current model class (Qwen2Model) is not compatible with `.generate()`”
# model = AutoModelForCausalLM.from_pretrained(
base_model_path,
trust_remote_code=True, # 是否信任远程代码
device_map='auto', # 设备映射(自动选择CPU、GPU)
low_cpu_mem_usage=True,
)
dialog = [
{"role": "system", "content": "你是一名AI助手?"},
{"role": "user", "content": "什么是AI?"},
# AI回复的,如果不添加这个可以使用model.generate得到回复
{"role": "assistant", "content": "AI 是..."},
]
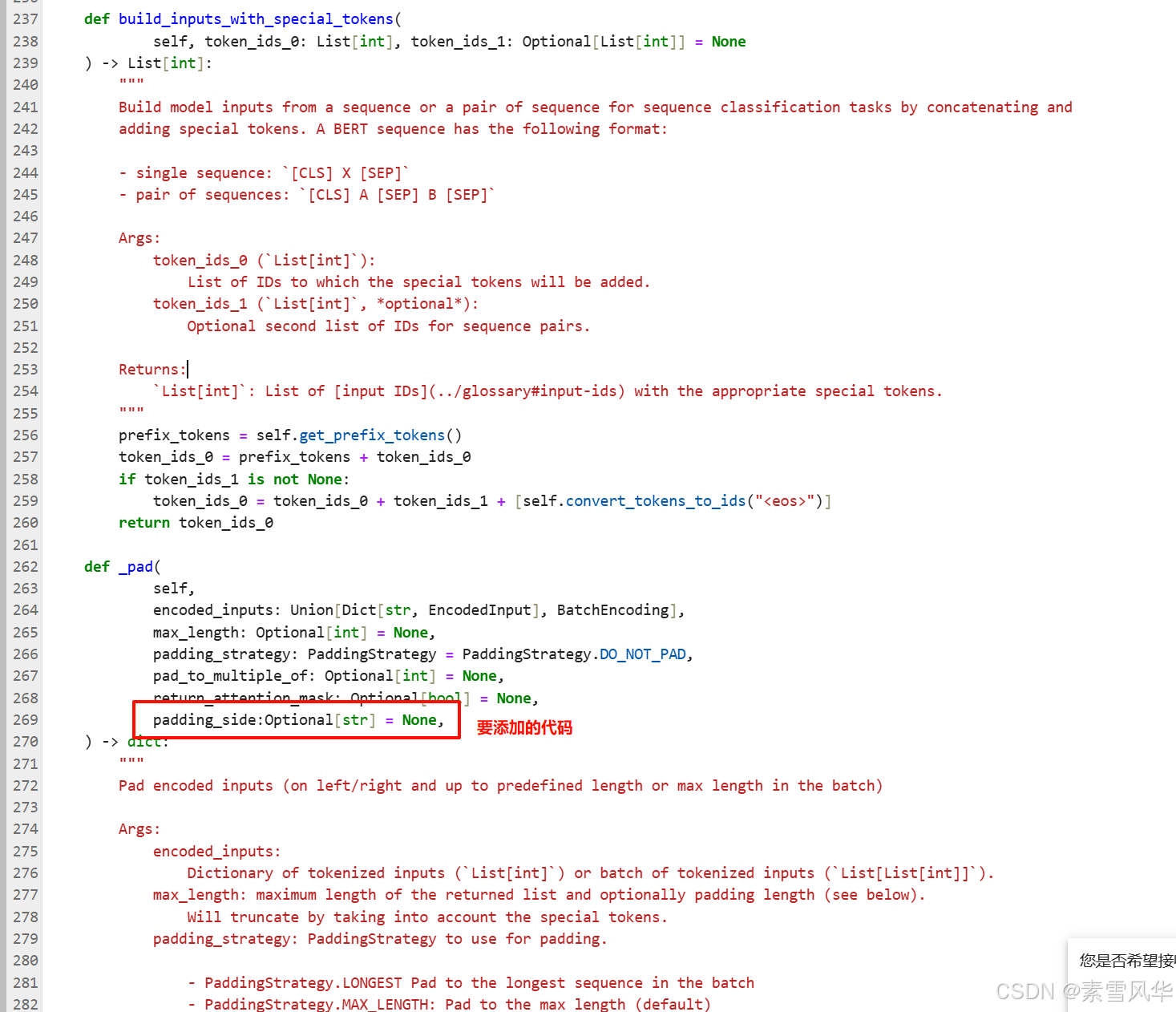
# TypeError: ChatGLM4Tokenizer._pad() got an unexpected keyword argument 'padding_side'
# 这个错误的原因是transformers的版本和ChatGLM版本冲突,不兼容问题
# 解决方法一,卸载较新的transformers安装老版本transformers:pip uninstall transformers -y; pip install transformers==4.44.2
# 解决方法二,修改源码。找到ZhipuAI/glm-4-9b/tokenization_chatglm.py文件,找到def _pad()方法,在“return_attention_mask: Optional[bool] = None,”后面添加“padding_side:Optional[str] = None,”,大概位置在270行作用。
inputs = tokenizer.apply_chat_template(
dialog,
add_generation_prompt=True, # 确保添加assistant提示符
tokenize=True,
return_tensors="pt", # 返回pytorch张量
return_dict=True # 返回字典
)
inputs = inputs.to('cpu') # 有cuda就用cuda,没有就cpu即可
#inputs = inputs.to('cuda') # 有cuda就用cuda,没有就cpu即可
# ==========================================
inputs
{'input_ids': tensor([[151644, 8948, 198, 56568, 110124, 15469, 110498, 30, 151645,198, 151644, 872, 198, 106582, 15469, 30, 151645, 198, 151644, 77091, 198, 15469, 54851, 1112, 151645, 198]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1]])}
# ==========================================
print(tokenizer.decode(inputs['input_ids'][0])) # 打印出来的就是模型需要输入的结果
'<|im_start|>system\n你是一名AI助手?<|im_end|>\n<|im_start|>user\n什么是AI?<|im_end|>\n<|im_start|>assistant\nAI 是...<|im_end|>\n'
# ==========================================
response = tokenizer("\n" + "我是回复消息", add_special_tokens=False)
decode = tokenizer.decode(response['input_ids'])
print(response) # {'input_ids': [198, 104198, 104787, 64205], 'attention_mask': [1, 1, 1, 1]},
print(decode) # '\n我是回复消息'
# ==========================================
result = tokenizer.decode(model.generate(**inputs, max_length=1024, do_sample=True, top_k=1)[0])
print(result) # 打印出来的就是模型需要输入以及模型生成的结果
# 这一行可以看到预处理数据时,需要将“用户输入时数据处理”成哪种格式的数据
'<|im_start|>system\n你是一名AI助手?<|im_end|>\n<|im_start|>user\n什么是AI?<|im_end|>\n<|im_start|>assistant\nAI 是...<|im_end|>\n<|endoftext|>'3.2.3 解决:ChatGLM4Tokenizer._pad() 的padding_side错误
解决:TypeError: ChatGLM4Tokenizer._pad() got an unexpected keyword argument 'padding_side',找到模型下面的这个文件,在添加代码:
"""
可能报错:TypeError: ChatGLM4Tokenizer._pad() got an unexpected keyword argument 'padding_side'
这是因为Transformers的版本时4.48...但是ChatGLM训练的时候使用的是4.40....什么的,导致版本不匹配。
解决方法:找到模型所在目录下面的“tokenization_chatglm.py”文件,找到270行,方法名称“def _pad(”,
在参数结尾处添加“padding_side:Optional[str] = None,”即可
即:
"""
def _pad(
self,
encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
max_length: Optional[int] = None,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
pad_to_multiple_of: Optional[int] = None,
return_attention_mask: Optional[bool] = None,
padding_side:Optional[str] = None, # 添加的行...
) -> dict:
3.2.4 预处理函数
----- PS:正常情况下,每个模型的预处理数据模板好像要求不一样。但是使用apply_chat_template可以通用~~~目前还没遇到不能用的。
除了tokenizer.apply_chat_template以外还可以手动拼装模板
##### 预处理函数 使用tokenizer.apply_chat_template获取 --- 这种方式好像比较通用
def process_func(example):
"""
原始数据样式:
example: {'instruction': 'java是什么', 'input': '', 'output': 'java是....'}
batched=True example: {'instruction': ['java是什么', 'c++是什么'], 'input': ['', ''], 'output': ['java是.....', 'c++是....']}
ChatGLM模板拼装的模板:
[gMASK] <sop> <|system|>
系统提示词(Qwen系列有固定的) <|user|>
用户输入问题 <|assistant|>
机器回复 <|endoftext|>
所以我们可以使用 tokenizer.apply_chat_template,来构造
返回的数据:
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels --- 真实的
}
:param example:
:return:
"""
MAX_LENGTH = 512
input_ids,attention_mask,labels = [],[],[]
input_messages = [
{"role":"system","content":"你是一名名字叫UU的助理,你是有血有肉的人,你从来不会说自己是AI机器人、不会说自己是智慧助手、不会说自己是AI助手,更加不会说自己是GLM公司开发的产品。当你不知道的时候,你会回复我“喵~ 奴家还在学习中...”,并且每次回复我的时候你都会带“喵~”结束语。"},
{"role":"user","content":example['instruction']+"\n"+example['input']}
]
inputs = tokenizer.apply_chat_template(
input_messages,
tokenize=True,
add_generation_prompt=True, # 确保添加assistant提示符
return_tensors="pt",
max_length=MAX_LENGTH,
return_dict=True
)
result = tokenizer(example['output'],add_special_tokens=False)
input_ids = inputs['input_ids'][0].numpy().tolist() + result["input_ids"] + [tokenizer.eos_token_id]
attention_mask = inputs['attention_mask'][0].numpy().tolist() + result["attention_mask"] + [1]
labels = [-100] * len(inputs['input_ids'][0].numpy().tolist()) + result['input_ids'] + [tokenizer.eos_token_id]
# 如果超过长度,就截断。
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# =============================================
##### 预处理函数 这个没意义..留着参考
def process_func(example):
"""
使用系统的数据模板构建 ---- 这个没意义..留着参考
:param example:
:return:
"""
MAX_LENGTH = 512 # 适当增加长度限制
# 使用官方对话模板构造输入
messages = [
{"role": "user", "content": example["instruction"] + example["input"]},
{"role": "assistant", "content": example["output"]}
]
# 使用tokenizer内置的模板方法
tokenized = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=False,
return_tensors="pt",
max_length=MAX_LENGTH,
truncation=True
)
# labels需要特殊处理
labels = tokenized.clone()
# 只计算assistant部分的loss
user_mask = (tokenized == tokenizer.get_vocab()["<|user|>"]) | (tokenized == tokenizer.get_vocab()["<|system|>"])
assistant_pos = torch.where(tokenized == tokenizer.get_vocab()["<|assistant|>"])[1][0]
labels[:, :assistant_pos+1] = -100 # 忽略用户部分的loss
return {
"input_ids": tokenized[0],
"attention_mask": torch.ones_like(tokenized[0]),
"labels": labels[0]
}
# =============================================
##### 预处理函数 这个没意义..留着参考 了解如何手动拼装预处理函数模板...
def process_func(example):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
# instruction = tokenizer("\n".join(["Human: "+ example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
instruction = tokenizer("\n".join(["Human: "+ example["instruction"], example["input"]]).strip() + "\n\nAssistant: ",add_special_tokens=False)
# add_special_tokens=True 在回复时是否加上分词token(tokenizer里面的additional_special_tokens)
# tokenizer.eos_token添加结束标识 让模型知道这句话结束了
response = tokenizer(example["output"] + tokenizer.eos_token,add_special_tokens=True)
# response = tokenizer(example["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}3.3 使用预处理函数处理数据
##### 需要先预先设置process_func预处理函数
#tokenizer_ds = ds.select(range(2)).map(process_fun,remove_columns=ds.column_names,batched=False)
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
# 验证集
tokenized_test = test.map(process_func, remove_columns=test.column_names)
tokenized_ds,tokenized_test
------------------
(Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 1525
}),
Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 153
}))
--------------------
数据预处理后辅助操作(参考)
tokenized_ds # 处理后的数据格式
tokenizer.decode(tokenized_ds[2]["input_ids"]) # 解码后的input_ids数据
# 解码后的labels数据
tokenizer.decode(list(filter(lambda x: x!=-100, tokenized_ds[2]["labels"])))
len(tokenized_ds[2]["input_ids"]) # input_ids数量
len(tokenized_ds[2]["labels"]) # labels数量Step4 模型创建
4.1 加载原始模型
4.1.1 非量化版本 --- bf16训练或者半精度half训练
base_model= AutoModelForCausalLM.from_pretrained(
"模型路径",
low_cpu_mem_usage=True, # 低CPU使用
use_cache=False, # 显式禁用缓存
trust_remote_code=True, # 是否信任远程代码
device_map="auto", # 自动选择设备(CPU/CUDA)
torch_dtype=torch.bfloat16 # 使用bfloat16训练 bfloat16的容错率比half高,优先使用
# torch_dtype=torch.half # 使用半精度训练
)4.1.2 量化版本
QLora - 4bit版本
# 注意版本:transformers=4.48.3、accelerate=1.2.1、bitsandbytes=0.45.3
###
#否则可能报错:ValueError: `.to` is not supported for `4-bit` or `8-bit` bitsandbytes models. Please use the model as it is, since the model has already been set to the correct devices and casted to the correct `dtype`."
quant_config=BitsAndBytesConfig(
load_in_4bit=True, # 启用4位量化。以4位精度加载模型权重
bnb_4bit_quant_type='nf4', # 量化类型:4-bit NormalFloat。
bnb_4bit_compute_dtype=torch.bfloat16, # 尽管模型权重以4位格式存储,但在实际计算过程中,会使用bfloat16(Brain Floating - Point)数据类型
bnb_4bit_use_double_quant=True, # 启用双重量化
)
base_model = AutoModelForCausalLM.from_pretrained(
"模型路径",
use_cache=False, # 显式禁用缓存
low_cpu_mem_usage=True, # 低CPU使用
trust_remote_code=True, # 是否信任远程代码
device_map="auto", # 自动选择设备(CPU/CUDA)
# 使用QLora --- 如果不使用量化的话,那么在24G显存的情况下训练GLM7B(18G)的时候会报显存溢出错误.
# 除此还有可以单独使用 8bit、4bit量化
quantization_config=quant_config
)
8bit/4bit版本
quant_config=BitsAndBytesConfig(
load_in_8bit=True, # 启用8位量化。以8位精度加载模型权重
#load_in_4bit=True, # 启用4位量化。以4位精度加载模型权重
)
base_model = AutoModelForCausalLM.from_pretrained(
"模型路径",
use_cache=False, # 显式禁用缓存
low_cpu_mem_usage=True, # 低CPU使用
trust_remote_code=True, # 是否信任远程代码
device_map="auto", # 自动选择设备(CPU/CUDA)
quantization_config=quant_config,
torch_dtype=torch.bfloat16 # 使用bfloat16训练 bfloat16的容错率比half高,优先使用
# torch_dtype=torch.half # 使用半精度训练
)
4.1.3 原始模型 辅助操作(参考)
# 模型相关操作
base_model # 模型基础信息
base_model.device # 模型模型驱动
base_model.dtype # 模型类型
base_model = base_model.cuda # 将模型移动到GPU中(如果在加载模型时设置的是“device_map="auto"”系统会自动加载到GPU)
# 模型占用显存大小
memory = base_model.get_memory_footprint()
print(f"{memory/(1024 ** 3):.2f}GB")
# 模型参数
for name, parameter in base_model.named_parameters():
print(name,parameter.dtype)
# 获取模型原有参数量
sum(param.numel() for param in base_model.parameters())4.1.4 原始模型结构展示
Lora微调一般微调其中带Linear的....
base_model.device,base_model.dtype,base_model
------------------
(device(type='cuda', index=0),
torch.bfloat16,
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(151552, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-39): 40 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): SdpaAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=151552, bias=False)
)
))
-------------------------------------
# 模型参数
for name, parameter in base_model.named_parameters():
print(name,parameter.dtype)
------------------
transformer.embedding.word_embeddings.weight torch.bfloat16
transformer.encoder.layers.0.input_layernorm.weight torch.bfloat16
transformer.encoder.layers.0.self_attention.query_key_value.weight torch.bfloat16
transformer.encoder.layers.0.self_attention.query_key_value.bias torch.bfloat16
transformer.encoder.layers.0.self_attention.dense.weight torch.bfloat16
transformer.encoder.layers.0.post_attention_layernorm.weight torch.bfloat16
transformer.encoder.layers.0.mlp.dense_h_to_4h.weight torch.bfloat16
transformer.encoder.layers.0.mlp.dense_4h_to_h.weight torch.bfloat16
transformer.encoder.final_layernorm.weight torch.bfloat16
transformer.output_layer.weight torch.bfloat16
transformer.embedding.word_embeddings.weight torch.bfloat16
transformer.encoder.layers.0.input_layernorm.weight torch.bfloat16
transformer.encoder.layers.0.self_attention.query_key_value.weight torch.bfloat16
transformer.encoder.layers.0.self_attention.query_key_value.bias torch.bfloat16
transformer.encoder.layers.0.self_attention.dense.weight torch.bfloat16
transformer.encoder.layers.0.post_attention_layernorm.weight torch.bfloat16
transformer.encoder.layers.0.mlp.dense_h_to_4h.weight torch.bfloat16
transformer.encoder.layers.0.mlp.dense_4h_to_h.weight torch.bfloat16
transformer.encoder.final_layernorm.weight torch.bfloat16
transformer.output_layer.weight torch.bfloat164.2 原始训练配置 - Bitfix训练(参考了解)
def filter_paramters(parameters_name):
"""
Selective 选择模型参数里面的所有 bias 偏置项部分训练
:param parameters_name:
:return:
"""
num_param = 0
for name, param in parameters_name:
"""
name param.requires_grad param.numel():
model.embed_tokens.weight --- False --- 136134656
model.layers.0.self_attn.q_proj.weight --- False --- 802816
model.layers.0.self_attn.q_proj.bias --- True --- 896
model.layers.0.self_attn.k_proj.weight --- False --- 114688
model.layers.0.self_attn.k_proj.bias --- True --- 128
model.layers.0.self_attn.v_proj.weight --- False --- 114688
model.layers.0.self_attn.v_proj.bias --- True --- 128
"""
if "bias" not in name:
# 参数进行冻结 frozen
param.requires_grad = False
else:
num_param += param.numel()
return num_param
num_param = filter_paramters(base_model.named_parameters())
---------------------
# ### 更新参数的操作 --- 可不要
num_param # 查看bias更新了那些部分
num_param / sum(param.numel() for param in base_model.parameters())4.3 加载PEFT模型
4.3.1 peft加载流程
"""
Prompt-tuning、P-Tuning、Prefix-Tuning、LoRA、IA3
此处可以使用peft框架.
步骤如下:
1、导入peft包(*Config、get_peft_model、TaskType)
- PrefixTuningConfig(Prefix-Tuning)、
- PromptTuningConfig(Prompt-Tuning)、
- PromptEncoderConfig(P-Tuning)、
- LoraConfig(LoRA-Tuning)、
- IA3Config(IA3-Tuning)
- .....
2、使用*Config构建config;
3、使用get_peft_model获取peft的model
4、将peft_model传入Trainer中即可
"""4.3.2 引入PEFT 依赖
import peft
# conda install peft --channel conda-forge
from peft import LoraConfig, get_peft_model, TaskType
peft.__version__4.3.3 设置配置文件
除了LoraConfig,还可有P-Tuning、Prefix-Tuning、Prompt-Tuning、IA3-Tuning...
# LoRA
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False, # 推理模式关闭,以进行训练
r=8, # 秩(Rank):决定LoRA矩阵维度,越大能力越强但显存消耗增加
lora_alpha=16, # 缩放因子:控制LoRA权重对原始权重的调整幅度
lora_dropout=0.1, # Dropout率:防止过拟合,正则化强度(0.1→0.2)
bias="none", # 偏置处理 :通常设为"none"或"lora_only"
#target_modules=["query_key_value", "dense"], # 扩展目标模块
#target_modules=[ # 目标模块:针对Qwen架构的典型模块
# "c_attn", # 注意力层的查询/键/值矩阵
# "c_proj", # 注意力输出投影
# "w1", "w2", "w3" # MLP层(适用于Qwen的FFN结构)
#],
# modules_to_save=['word_embeddings']
#modules_to_save=["embed_tokens", "lm_head"] # 需全参数训练的模块(词嵌入和输出头)
)
----------------------------- 以下参考.....
# P-Tuning
config = PromptEncoderConfig(
task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10,
#encoder_reparameterization_type=PromptEncoderReparameterizationType.LSTM,
#encoder_dropout=0.1, encoder_num_layers=5, encoder_hidden_size=1024
)
# Prefix-Tuning
config = PrefixTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=10,
prefix_projection=True,
encoder_hidden_size=100
)
# Prompt-Tuning
config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
prompt_tuning_init_text="下面是一段人与机器人的对话,",
num_virtual_tokens=len(tokenizer("下面是一段人与机器人的对话,")["input_ids"]),
tokenizer_name_or_path="Langboat/bloom-1b4-zh"
)
# IA3-Tuning
config = IA3Config(task_type=TaskType.CAUSAL_LM...)
config 配置 数据结构展示
print(config)
------------------
LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, r=8, target_modules={'dense', 'query_key_value'}, lora_alpha=16, lora_dropout=0.05, fan_in_fan_out=False, bias='none', use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', loftq_config={}, use_dora=False, layer_replication=None, runtime_config=LoraRuntimeConfig(ephemeral_gpu_offload=False))4.3.4 PEFT参数详解
线性层:model数据模板中,携带Linear的对象比如query_key_value、dense
target_modules:要训练的目标模块 --- 根据模型调整
含义:指定需要注入LoRA适配层的模块(通常是线性层-模型模板中的Linear)。这些模块的原始参数会被冻结,仅训练LoRA的低秩矩阵。
参数来源:应从模型的线性层中选择,如注意力机制中的投影层(q_proj, k_proj, v_proj, o_proj)和MLP中的线性层(gate_proj, up_proj, down_proj)
训练方式:仅训练LoRA矩阵
验证模块名称:
for name, module in model.named_modules():
print(name)
或者
print(model)作用:
指定应用LoRA适配器的模块:这些模块的原始权重会被冻结,仅训练LoRA的低秩矩阵。
通常选择注意力层的投影矩阵:如 q_proj (Query)、v_proj (Value) 等,这类矩阵参数多且对任务敏感。
target_modules = [ "q_proj", "v_proj", #自注意力层的 q_proj 和 v_proj(Qwen经典配置) # 也可扩展至 k_proj、o_proj 或MLP层的 gate_proj、up_proj。 ] # 注意:模型中 k_proj 和 v_proj 的输出维度为512(可能是分组注意力),若需适配,需确保LoRA的r(秩)合理设置。 比如Qwen系列就是q_proj、k_proj、v_proj...... ChatGLM系列就是:query_key_value、dense_h_to_4h、dense_4h_to_h 在模型结构中“携带Linear”就是线性层
modules_to_save:需要完整训练的模块(非LoRA模块) --- 根据模型调整
含义:指定需要完全训练(不冻结)的原始模块。这些模块的参数会直接参与梯度更新,不通过LoRA适配层。
参数来源:通常包括嵌入层、输出层(lm_head)、层归一化(LayerNorm或RMSNorm)等关键模块。
训练方式:全参数训练
作用:
指定不应用LoRA但需全参数训练的模块:这些模块的原始参数会完全参与训练,适合参数少但对任务敏感的模块(如归一化层、词嵌入层)。
常见选择:LayerNorm、RMSNorm、Embedding层、输出头(lm_head)。
modules_to_save = [ "embed_tokens", # 嵌入层(适配输入词汇) "lm_head", # 输出层(适配生成任务) "norm", # 顶层归一化(顶层RMSNorm(model.norm)) "input_layernorm", # 各层的输入层归一化(各Decoder层的输入RMSNorm) "post_attention_layernorm" # 各层的注意力后归一化(各Decoder层的后注意力RMSNorm) ] # 注意:"input_layernorm"和 "post_attention_layernorm" 会自动匹配所有层的对应RMSNorm模块(如 model.layers.0.input_layernorm)。
注意事项:
性能权衡:扩大target_modules会增加可训练参数,可能提升性能但消耗更多资源。
层归一化:微调时通常需更新层归一化参数(加入modules_to_save)。
输出层:若任务涉及词汇分布变化(如领域适应),务必包含lm_head。
4.3.5 获取PEFT模型
peft_model = get_peft_model(base_model, config)4.3.6 开启梯度检查
# Step4:开启模型的梯度 ---- 如果在TrainingArguments中配置了gradient_checkpointing=True则需要开启
### gradient checkpointing=True 需要执行下面一行代码
### 如果不加可能会报错“RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn”
model.enable_input_require_grads()4.3.7 PEFT模型 辅助操作(参考)
# 训练模型的参数量
peft_model.print_trainable_parameters()
# 参数名称和类型
# 默认的情况下 Lora微调的时候parameter.dtype打印出来的要微调的参数是fp32;此时我们可以使用model = model.half() 降为半精度微调...
for name, parameter in peft_model.named_parameters():
print(name,parameter.dtype)4.3.8 PEFT模型参数数据结构展示
for name, parameter in peft_model.named_parameters():
print(name,parameter.dtype)
------------------
base_model.model.transformer.embedding.word_embeddings.weight torch.bfloat16
base_model.model.transformer.encoder.layers.0.input_layernorm.weight torch.bfloat16
base_model.model.transformer.encoder.layers.0.self_attention.query_key_value.base_layer.weight torch.bfloat16
base_model.model.transformer.encoder.layers.0.self_attention.query_key_value.base_layer.bias torch.bfloat16
base_model.model.transformer.encoder.layers.0.self_attention.query_key_value.lora_A.default.weight torch.float32
base_model.model.transformer.encoder.layers.0.self_attention.query_key_value.lora_B.default.weight torch.float32
base_model.model.transformer.encoder.layers.0.self_attention.dense.base_layer.weight torch.bfloat16
base_model.model.transformer.encoder.layers.0.self_attention.dense.lora_A.default.weight torch.float32
base_model.model.transformer.encoder.layers.0.self_attention.dense.lora_B.default.weight torch.float32
base_model.model.transformer.encoder.layers.0.post_attention_layernorm.weight torch.bfloat16
base_model.model.transformer.encoder.layers.0.mlp.dense_h_to_4h.weight torch.bfloat16
base_model.model.transformer.encoder.layers.0.mlp.dense_4h_to_h.weight torch.bfloat16
base_model.model.transformer.encoder.final_layernorm.weight torch.bfloat16
base_model.model.transformer.output_layer.weight torch.bfloat164.3.9 PEFT获取到的模型结构展示
peft_model.device,peft_model.dtype,model
------------------
(device(type='cuda', index=0),
torch.bfloat16,
PeftModelForCausalLM(
(base_model): LoraModel(
(model): ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(151552, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-39): 40 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4608, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4608, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(core_attention): SdpaAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=151552, bias=False)
)
)
)
))Step5. 训练参数配置
5.1 定义TrainingArguments对象
# 基础版本:
args = TrainingArguments(
output_dir=output_dir, # 基础设置.输出文件夹存储模型的预测结果和模型文件checkpoints
per_device_train_batch_size=1, # 基础设置.每个设备的batch size,根据显存调整(A100 40G可用8-16):默认8, 对于训练的时候每个 GPU核或者CPU 上面对应的一个批次的样本数
gradient_accumulation_steps=8, # 基础设置.梯度累积(总batch=4*8=32):默认1, 在执行反向传播/更新参数之前, 对应梯度计算累积了多少次
logging_steps=10, # 基础设置.每隔10迭代落地一次日志
learning_rate=3e-4, # 基础设置.学习率(LoRA通常使用较高学习率):LoRA通常用1e-4(0.0001)到3e-4(0.0003)/5e-4(0.0005) 5e-5(0.00005)
num_train_epochs=1, # 基础设置.训练轮次:整体上数据集让模型学习多少遍
save_strategy="steps", # 基础设置.按步数保存
save_total_limit=2, # 基础设置.最多保留2个检查点
weight_decay=0.01, # 基础设置.添加权重衰减
)
# #### 稍微完整版本 -
args = TrainingArguments(
output_dir=output_dir, # 基础设置.输出文件夹存储模型的预测结果和模型文件checkpoints
per_device_train_batch_size=1, # 基础设置.每个设备的batch size,根据显存调整(A100 40G可用8-16):默认8, 对于训练的时候每个 GPU核或者CPU 上面对应的一个批次的样本数
gradient_accumulation_steps=8, # 基础设置.梯度累积(总batch=4*8=32):默认1, 在执行反向传播/更新参数之前, 对应梯度计算累积了多少次
learning_rate=3e-4, # 基础设置.学习率(LoRA通常使用较高学习率):LoRA通常用1e-4到3e-4
num_train_epochs=1, # 基础设置.训练轮次:整体上数据集让模型学习多少遍
logging_strategy='epoch', # 打印日志方式:epoch、no、steps
logging_steps=10, # 基础设置.每隔10迭代落地一次日志
save_strategy="steps", # 基础设置.按步数保存steps、epoch
save_total_limit=2, # 基础设置.最多保留2个检查点
save_steps=500, # 每隔多少步保存一次检查点
weight_decay=0.01, # 基础设置.添加权重衰减
max_grad_norm=1, # 梯度裁剪:防止梯度爆炸
gradient_checkpointing=True, # 梯度落地;可以更加节约显存空间,需要在前面对模型开启输入,允许梯度输入“model.enable_input_require_grads()”
warmup_ratio=0.05, # 预热比例:前5%的step用于学习率上升,即学习率(learning rate)从一个较小的值线性增加到预定值的过程; 也可以使用warmup_steps=100来设置热身步骤
optim="adamw_torch", # paged_adamw_32bit(带分页的adaw优化器:可以防止显存溢出)、adamw_torch、adamw_torch_fused
lr_scheduler_type='', # 学习率类型 默认为"linear",用于指定学习率scheduler的类型;cosine、cosine_with_restarts、reduce_lr_on_plateau、warmup_stable_decay、constant、cosine_with_min_lr
fp16=False, # 禁用FP16混合精度,当使用bfloat16时关闭
bf16=True, # 使用bfloat16混合精度
logging_dir=log_dir, # 日志目录
remove_unused_columns=False, # 保留未使用的列(用于标签),必须设为False以保留labels字段
dataloader_num_workers=0, # 数据加载线程数 ----- 禁用多线程加载,或者设置为较小的值(1-2),可能报警告:huggingface/tokenizers: The current process just got forked,
#report_to=["tensorboard"], # 日志记录方式,使用TensorBoard记录
report_to="none", # 禁用wandb等报告
# adam_epsilon=1e-4, # 我们使用的是adam优化器,他的 adam_epsilon 默认为1e-8太小了,这样的话,我们在使用半精度微调的时候,可能导致下溢,Loss可能会突然降为0
# disable_tqdm=True # 打印Loss的时候一条一条的纯文本打印
# 学习率调度器类型
# 评估设置
# evaluation_strategy="no", # 评估策略 no/steps/epoch
eval_strategy='steps', # 评估策略,和evaluation_strategy一样.
eval_accumulation_steps=2, # 多久一次将tensor搬到cpu ----- 防止爆显存 - 不然评估trainer.evaluate的时候会占显存
# 在评估阶段,模型需要同时保存前向传播的logits(预测结果)用于计算指标,而logits的维度(batch_size × sequence_length × vocab_size)非常消耗显存
per_device_eval_batch_size=8, # 减少每次评估的样本数量。不然可能报显存溢出。哪怕是3G模型
eval_steps=10, # 每50步评估一次 ---- 因为要打印验证日志,所以logging_steps也会被这个步数覆盖
metric_for_best_model="eval_loss", # 根据验证损失选择最佳模型
# metric_for_best_model="f1", # 根据F1选择最佳模型 --- 需要设置评估函数eval_metric,并且要和eval_metric中的返回的dict中的key对应
load_best_model_at_end=True, # 训练完成后加载最佳模型
)
# 如果我们要使用F1之类的话需要单独设置评估函数,然后将其设置到Trainer中compute_metrics=eval_metric(评估函数)
5.2 TrainingArguments参数详解
红字很重要,篮字稍逊,其他字....看情况。
- output_dir (str):用于指定模型checkpoint和最终结果的输出目录。
- evaluation_strategy (str, 可选,默认为 "no"):用于指定训练期间采用的评估策略,可选值包括:
- per_device_train_batch_size (int, 可选, 默认为 8):用于指定训练的每个GPU/XPU/TPU/MPS/NPU/CPU的batch,每个训练步骤中每个硬件上的样本数量。
- per_device_eval_batch_size (int, 可选, 默认为 8):用于指定评估的每个GPU/XPU/TPU/MPS/NPU/CPU的batch,每个评估步骤中每个硬件上的样本数量。
- gradient_accumulation_steps (int, 可选, 默认为 1):用于指定在每次更新模型参数之前,梯度积累的更新步数。使得梯度积累可以在多个batch上累积梯度,然后更新模型参数,就可以在显存不够的情况下执行大batch的反向传播。
- eval_accumulation_steps (int, 可选):指定在执行评估时,模型会累积多少个预测步骤的输出张量,然后才将它们从GPU/NPU/TPU移动到CPU上,默认是整个评估的输出结果将在GPU/NPU/TPU上累积,然后一次性传输到CPU,速度更快,但占显存。
- learning_rate (float, 可选, 默认为 5e-5):指定AdamW优化器的初始学习率。
- weight_decay (float, 可选, 默认为 0):指定正则化。权重衰减的值,会应用在 AdamW 优化器的所有层上,除了偏置(bias)和 Layer Normalization 层(LayerNorm)的权重上。0.01/0.05( 过高 → 抑制模型学习能力,导致模型欠拟合,TraingLoss不下降)
- max_grad_norm (float, 可选, 默认为 1.0):指定梯度剪裁的最大梯度范数,可以防止梯度爆炸,一般都是1,如果某一步梯度的L2范数超过了 此参数,那么梯度将被重新缩放,确保它的大小不超过此参数。
- num_train_epochs (float, 可选, 默认为 3.0):训练的总epochs数。
- warmup_ratio (float, 可选, 默认为0.0):用于指定线性热身占总训练步骤的比例,线性热身是一种训练策略,学习率在开始阶段从0逐渐增加到其最大值(通常是设定的学习率),然后在随后的训练中保持不变或者按照其他调度策略进行调整。如果设置为0.0,表示没有热身。
- logging_dir (str, 可选):TensorBoard日志目录。默认为output_dir/runs/CURRENT_DATETIME_HOSTNAME。
- logging_strategy (str, 可选, 默认为"steps"):训练过程中采用的日志记录策略。可选包括:
- logging_steps (int or float,可选, 默认为500):如果logging_strategy="steps",则此参数为每多少步记录一次步骤。
- save_strategy (str , 可选, 默认为 "steps"):训练过程中保存checkpoint的策略,包括:
- save_steps (int or float, 可选, 默认为500):如果save_strategy="steps",就是指两次checkpoint保存之间的更新步骤数。如果是在[0, 1)的浮点数,则就会当做与总训练步骤数的比例。
- save_total_limit (int, 可选):如果给定了参数,将限制checkpoint的总数,因为checkpoint也是很占硬盘的,将会删除输出目录中旧的checkpoint。当启用load_best_model_at_end时,会根据metric_for_best_model保留最好的checkpoint,以及最近的checkpoint。
- load_best_model_at_end (bool, 可选, 默认为False):用于指定是否在训练结束时加载在训练过程中最好的checkpoint,设置为 True 时,就是帮你找到在验证集上指标最好的checkpoint并且保存,然后还会保存最后一个checkpoint,在普通的多epoch训练中,最好设置为True,但在大模型训练中,一般是一个epoch,使用的就是最后一个checkpoint。
- seed (int, 可选, 默认为42):用于指定训练过程的随机种子,可以确保训练的可重现性,主要用于model_init,随机初始化权重参数。
- data_seed (int, 可选):用于指定数据采样的随机种子,如果没有设置将使用与seed相同的种子,可以确保数据采样的可重现性。
- bf16 (bool, 可选, 默认为False):用于指定是否使用bf16进行混合精度训练,而不是fp32训练,需要安培架构或者更高的NVIDIA架构,关于精度的问题可以看这篇文章:Glan格蓝:LLM大模型之精度问题(FP16,FP32,BF16)详解与实践在简单解释一下混合精度训练:模型训练时将模型参数和梯度存储为fp32,但在前向和后向传播计算中使用fp16,这样可以减少内存使用和计算时间,并提高训练速度,这个只是简单的解释,关于混合精度训练,这篇文章讲的比较好 点这里
- fp16 (bool,** 可选, 默认为****False)**:用于指定是否使用fp16进行混合精度训练,而不是fp32训练。
- eval_steps (int or float, 可选):如果evaluation_strategy="steps",就是指两次评估之间的更新步数,如果未设置,默认和设置和logging_steps相同的值,如果是在[0, 1)的浮点数,则就会当做与总评估步骤数的比例。
- dataloader_num_workers (int, 可选, 默认为 0):用于指定数据加载时的子进程数量(仅用于PyTorch)其实就是PyTorch的num_workers参数,0表示数据将在主进程中加载。
- metric_for_best_model (str, 可选):与 load_best_model_at_end 结合使用,用于指定比较不同模型的度量标准,默认情况下,如果未指定,将使用验证集的 "loss" 作为度量标准(即eval_loss),可使用accuracy、F1、loss等。
- optim (str 或 training_args.OptimizerNames, 可选, 默认为 "adamw_torch"):指定要使用的优化器。
- gradient_checkpointing (bool, 可选, 默认为False):是否开启梯度检查点,简单解释一下:训练大型模型时需要大量的内存,其中在反向传播过程中,需要保存前向传播的中间计算结果以计算梯度,但是这些中间结果占用大量内存,可能会导致内存不足,梯度检查点会在训练期间释放不再需要的中间结果以减小内存占用,但它会使训练变慢。
- auto_find_batch_size (bool, 可选, 默认为 False):是否使用自动寻找适合内存的batch size大小,以避免 CUDA 内存溢出错误,需要安装 accelerate(使用 pip install accelerate),这个功能还是比较NB的。
- prediction_loss_only (bool, 可选, 默认为 False):如果设置为True,当进行评估和预测时,只返回损失值,而不返回其他评估指标。
- deepspeed (str 或 dict, 可选):用于指定是否要启用 DeepSpeed,以及如何配置 DeepSpeed。也是目前分布式训练使用最多的框架,比上面pytorch原生分布式训练以及FairScale用的范围更广,详细的可以看其官网。
- warmup_steps (int,可选, 默认为0):这个是直接指定线性热身的步骤数,这个参数会覆盖warmup_ratio,如果设置了warmup_steps,将会忽略warmup_ratio。
- use_cpu (bool, 可选, 默认为 False):是否使用CPU训练。如果设置为False,将使用CUDA或其他可用设备。
- lr_scheduler_type (str, 可选, 默认为"linear"):用于指定学习率scheduler的类型,根据训练的进程来自动调整学习率。详细见:"linear":线性学习率scheduler,学习率以线性方式改变"cosine":余弦学习率scheduler,学习率以余弦形状的方式改变。"constant":常数学习率,学习率在整个训练过程中保持不变。"polynomial":多项式学习率scheduler,学习率按多项式函数的方式变化。"piecewise":分段常数学习率scheduler,每个阶段使用不同的学习率。"exponential":指数学习率scheduler,学习率以指数方式改变。
- overwrite_output_dir (bool, 可选,默认为 False):如果设置为True,将覆盖输出目录中已存在的内容,在想要继续训练模型并且输出目录指向一个checkpoint目录时还是比较有用的。
- do_train (bool, 可选,默认为 False):是否执行训练,其实Trainer是不直接使用此参数,主要是用于我们在写脚本时,作为if的条件来判断是否执行接下来的代码。
- do_eval (bool, 可选):是否在验证集上进行评估,如果评估策略(evaluation_strategy)不是"no",将自动设置为True。与do_train类似,也不是直接由Trainer使用的,主要是用于我们写训练脚本。
- do_predict (bool, 可选,默认为 False):是否在测试集上进行预测。
- eval_delay (float, 可选):指定等待执行第一次评估的轮数或步数。如果evaluation_strategy为"steps",设置此参数为10,则10个steps后才进行首次评估。
- adam_beta1 (float, 可选, 默认为 0.9):指定AdamW优化器的beta1超参数,详细的解释可以看其论文。
- adam_beta2 (float, 可选, 默认为 0.999):指定AdamW优化器的beta2超参数,详细的解释可以看其论文。
- adam_epsilon (float, 可选, 默认为 1e-8):指定AdamW优化器的epsilon超参数,详细的解释可以看其论文。
- max_steps (int, 可选, 默认为 -1):如果设置为正数,就是执行的总训练步数,会覆盖num_train_epochs。注意如果使用此参数,就算没有达到这个参数值的步数,训练也会在数据跑完后停止。
- log_level (str, 可选, 默认为passive):用于指定主进程上要使用的日志级别,
- log_level_replica (str, 可选, 默认为warning):副本上要使用的日志级别,与log_level相同。
- log_on_each_node (bool, optional, defaults to True):在多节点分布式训练中,是否在每个节点上使用log_level进行日志记录。
- logging_nan_inf_filter (bool, 可选, 默认为 True):是否过滤日志记录中为nan和inf的loss,如果设置为True,将过滤每个步骤的loss,如果出现nan或inf,将取当前日志窗口的平均损失值。
- save_safetensors (bool, 可选, 默认为False):用于指定是否在保存和加载模型参数时使用 "safetensors","safetensors" 就是更好地处理了不同 PyTorch 版本之间的模型参数加载的兼容性问题。
- save_on_each_node (bool, 可选, 默认为 False):在进行多节点分布式训练时,是否在每个节点上保存checkpoint,还是仅在主节点上保存。注意如果多节点使用的是同一套存储设备,比如都是外挂的铜一个nas,开启后会报错,因为文件名称都一样。
- jit_mode_eval (bool, 可选, 默认为False):用于指定是否在推理(inference)过程中使用 PyTorch 的 JIT(Just-In-Time)跟踪功能,PyTorch JIT 是 PyTorch 的一个功能,用于将模型的前向传播计算编译成高性能的机器代码,会加速模型的推理。
- use_ipex (bool, 可选, 默认为 False):用于指定是否使用英特尔扩展(Intel extension)来优化 PyTorch,需要安装IPEX,IPEX是一组用于优化深度学习框架的工具和库,可以提高训练和推理的性能,特别针对英特尔的处理器做了优化。
- fp16_opt_level (str, 可选, 默认为 ''O1''):对于fp16训练,选择的Apex AMP的优化级别,可选值有 ['O0', 'O1', 'O2'和'O3']。详细信息可以看Apex文档。
- half_precision_backend (str, 可选, 默认为"auto"):用于指定混合精度训练(Mixed Precision Training)时要使用的后端,必须是 "auto"、"cuda_amp"、"apex"、"cpu_amp" 中的一个。"auto"将根据检测到的PyTorch版本来使用后端,而其他选项将会强制使用请求的后端。使用默认就行。
- bf16_full_eval (bool, 可选, 默认为 False):用于指定是否使用完全的bf16进行评估,而不是fp32。这样更快且省内存,但因为精度的问题指标可能会下降。
- fp16_full_eval (bool, 可选, 默认为 False):同上,不过将使用fp16.
- tf32 (bool, 可选):用于指定是否启用tf32精度模式,适用于安培架构或者更高的NVIDIA架构,默认值取决于PyTorch的版本torch.backends.cuda.matmul.allow_tf32的默认值。
- local_rank (int, 可选, 默认为 -1):用于指定在分布式训练中的当前进程(本地排名)的排名,这个不需要我们设置,使用PyTorch分布式训练时会自动设置,默认为自动设置。
- ddp_backend (str, 可选):用于指定处理分布式计算的后端框架,这些框架的主要用于多个计算节点协同工作以加速训练,处理模型参数和梯度的同步、通信等操作,可选值如下"nccl":这是 NVIDIA Collective Communications Library (NCCL) 的后端。"mpi":Message Passing Interface (MPI) 后端, 是一种用于不同计算节点之间通信的标准协议。"ccl":这是 Intel的oneCCL (oneAPI Collective Communications Library) 的后端。"gloo":这是Facebook开发的分布式通信后端。"hccl":这是Huawei Collective Communications Library (HCCL) 的后端,用于华为昇腾NPU的系统上进行分布式训练。
- tpu_num_cores (int, 可选):指定在TPU上训练时,TPU核心的数量。
- dataloader_drop_last (bool, 可选, 默认为False):用于指定是否丢弃最后一个不完整的batch,发生在数据集的样本数量不是batch_size的整数倍的时候。
- past_index (int, 可选, 默认为 -1):一些模型(如TransformerXL或XLNet)可以利用过去的隐藏状态进行预测,如果将此参数设置为正整数,Trainer将使用相应的输出(通常索引为2)作为过去状态,并将其在下一个训练步骤中作为mems关键字参数提供给模型,只针对一些特定模型。
- run_name (str, 可选):用于指定训练运行(run)的字符串参数,与日志记录工具(例如wandb和mlflow)一起使用,不影响训练过程,就是给其他的日志记录工具开了一个接口,个人还是比较推荐wandb比较好用。
- disable_tqdm (bool, 可选):是否禁用Jupyter笔记本中的~notebook.NotebookTrainingTracker生成的tqdm进度条,如果日志级别设置为warn或更低,则将默认为True,否则为False。
- remove_unused_columns (bool, 可选, 默认为True):是否自动删除模型在训练时,没有用到的数据列,默认会删除,比如你的数据有两列分别是content和id,如果没有用到id这一列,训练时就会被删除。
- label_names (List[str], 可选):用于指定在模型的输入字典中对应于标签(labels)的键,默认情况下不需要显式指定。
- greater_is_better (bool, 可选):与 load_best_model_at_end 和 metric_for_best_model 结合使用,这个和上面的那个参数是对应的,是指上面的那个指标是越大越好还是越小越好,如果是loss就是越小越好,这个参数就会被设置为False;如果是accuracy,你需要把这个值设为True。
- ignore_data_skip (bool, 可选,默认为False):用于指定是否断点训练,即训练终止又恢复后,是否跳过之前的训练数据。
- resume_from_checkpoint (str, 可选):用于指定从checkpoint恢复训练的路径。
- sharded_ddp (bool, str 或 ShardedDDPOption 列表, 可选, 默认为''):是否在分布式训练中使用 Sharded DDP(Sharded Data Parallelism),这是由 FairScale提供的,默认不使用,简单解释一下: FairScale 是Mate开发的一个用于高性能和大规模训练的 PyTorch 扩展库。这个库扩展了基本的 PyTorch 功能,同时引入了最新的先进规模化技术,通过可组合的模块和易于使用的API,提供了最新的分布式训练技术。详细的可以看其官网。
- fsdp (bool, str 或 FSDPOption 列表, 可选, 默认为''):用于指定是否要启用 PyTorch 的 FSDP(Fully Sharded Data Parallel Training),以及如何配置分布式并行训练。
- fsdp_config (str 或 dict, 可选):用于配置 PyTorch 的 FSDP(Fully Sharded Data Parallel Training)的配置文件
- label_smoothing_factor (float, 可选,默认为0.0):用于指定标签平滑的因子。
- debug (str 或 DebugOption 列表, 可选, 默认为''):用于启用一个或多个调试功能
- optim_args (str, 可选):用于向特定类型的优化器(如adamw_anyprecision)提供额外的参数或自定义配置。
- group_by_length (bool, 可选, 默认为 False):是否在训练数据集中对大致相同长度的样本进行分组然后放在一个batch里,目的是尽量减少在训练过程中进行的padding,提高训练效率。
- length_column_name (str, 可选, 默认为 "length"):当你上个参数设置为True时,你可以给你的训练数据在增加一列”长度“,就是事先计算好的,可以加快分组的速度,默认是length。
- report_to (str 或 str 列表, 可选, 默认为 "all"):用于指定要将训练结果和日志报告到的不同日记集成平台,有很多"azure_ml", "clearml", "codecarbon", "comet_ml", "dagshub", "flyte", "mlflow", "neptune", "tensorboard", and "wandb"。直接默认就行,都发。
- ddp_find_unused_parameters (bool, 可选):当你使用分布式训练时,这个参数用于控制是否查找并处理那些在计算中没有被使用的参数,如果启用了梯度检查点(gradient checkpointing),表示部分参数是惰性加载的,这时默认值为 False,因为梯度检查点本身已经考虑了未使用的参数,如果没有启用梯度检查点,默认值为 True,表示要查找并处理所有参数,以确保它们的梯度被正确传播。
- ddp_bucket_cap_mb (int, 可选):在分布式训练中,数据通常分成小块进行处理,这些小块称为"桶",这个参数用于指定每个桶的最大内存占用大小,一般自动分配即可。
- ddp_broadcast_buffers (bool, 可选):在分布式训练中,模型的某些部分可能包含缓冲区,如 Batch Normalization 层的统计信息,这个参数用于控制是否将这些缓冲区广播到所有计算设备,以确保模型在不同设备上保持同步,如果启用了梯度检查点,表示不需要广播缓冲区,因为它们不会被使用,如果没有启用梯度检查点,默认值为 True,表示要广播缓冲区,以确保模型的不同部分在所有设备上都一致。
- dataloader_pin_memory (bool, 可选, 默认为 True):用于指定dataloader加载数据时,是否启用“pin memory”功能。“Pin memory” 用于将数据加载到GPU内存之前,将数据复制到GPU的锁页内存(pinned memory)中,锁页内存是一种特殊的内存,可以更快地传输数据到GPU,从而加速训练过程,但是会占用额外的CPU内存,会导致内存不足的问题,如果数据量特别大,百G以上建议False。
- skip_memory_metrics (bool, 可选, 默认为 True):用于控制是否将内存分析报告添加到性能指标中,默认情况下跳过这一步,以提高训练和评估的速度,建议打开,更能够清晰的知道每一步的内存使用。
- include_inputs_for_metrics (bool, 可选, 默认为 False):是否将输入传递给 compute_metrics 函数,一般计算metrics用的是用的是模型预测的结果和我们提供的标签,但是有的指标需要输入,比如cv的IoU(Intersection over Union)指标。
- full_determinism (bool, 可选, 默认为 False):如果设置为 True,将调用 enable_full_determinism() 而不是 set_seed(),训练过程将启用完全确定性(full determinism),在训练过程中,所有的随机性因素都将被消除,确保每次运行训练过程都会得到相同的结果,注意:会对性能产生负面影响,因此仅在调试时使用。
- torchdynamo (str, 可选):用于选择 TorchDynamo 的后端编译器,TorchDynamo 是 PyTorch 的一个库,用于提高模型性能和部署效率,可选的选择包括 "eager"、"aot_eager"、"inductor"、"nvfuser"、"aot_nvfuser"、"aot_cudagraphs"、"ofi"、"fx2trt"、"onnxrt" 和 "ipex"。默认就行,自动会选。
- ray_scope (str, 可选, 默认为 "last"):用于使用 Ray 进行超参数搜索时,指定要使用的范围,默认情况下,使用 "last",Ray 将使用所有试验的最后一个检查点,比较它们并选择最佳的。详细的可以看一下它的文档。
- ddp_timeout (int, 可选, 默认为 1800):用于 torch.distributed.init_process_group 调用的超时时间,在分布式运行中执行较慢操作时,用于避免超时,具体的可以看 PyTorch 文档 。
- torch_compile (bool, 可选, 默认为 False):是否使用 PyTorch 2.0 及以上的 torch.compile 编译模型,具体的可以看 PyTorch 文档 。
- torch_compile_backend (str, 可选):指定在 torch.compile 中使用的后端,如果设置为任何值,将启用 torch_compile。
- torch_compile_mode (str, 可选):指定在 torch.compile 中使用的模式,如果设置为任何值,将启用 torch_compile。
- include_tokens_per_second (bool, 可选):确定是否计算每个设备的每秒token数以获取训练速度指标,会在整个训练数据加载器之前进行迭代,会稍微减慢整个训练过程,建议打开。
- push_to_hub (bool, 可选, 默认为 False):指定是否在每次保存模型时将模型推送到Huggingface Hub。
- hub_model_id (str, 可选):指定要与本地 output_dir 同步的存储库的名称。
- hub_strategy (str 或 HubStrategy, 可选, 默认为 "every_save"):指定怎么推送到Huggingface Hub。
- hub_token (str, 可选):指定推送模型到Huggingface Hub 的token。
- hub_private_repo (bool, 可选, 默认为 False):如果设置为 True,Huggingface Hub 存储库将设置为私有。
- hub_always_push (bool, 可选, 默认为 False):是否每次都推送模型。
Step6 设置训练加载器
6.1 基础版本 --- 可以选择是否设置eval_loss验证损失
# 基础版 - 训练器加载
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
# train_dataset=tokenized_ds.select(range(100)), # 选择前500条训练
# eval_dataset=tokenized_test, # 根据实际需要,看是否需要引入训练Loss
# 构建一个个批次数据所需要的
data_collator=DataCollatorForSeq2Seq(
tokenizer=tokenizer,
pad_to_multiple_of=8, # 对齐到8的倍数提升计算效率
# padding=True, # 动态填充到批次内最大长度 如果再预处理中强制了max长度那就必须填充到max_length否则要报错...
padding="max_length", # 强制填充到 max_length
max_length=512, # 确保所有样本长度为512 --- 最好和预处理函数里面的lenth保持一致
return_tensors='pt' # 返回PyTorch的张量类型
),
)6.2 引入自定义评估函数版本 -评估函数rouge、bleu
6.2.1 指标介绍
loss:损失率
eval_loss:验证损失率
文本分类任务:accuracy准确率(分类正确的样本数占总样本数的比例,返回0~1)、precision精确率、recall召回率、F1分数(准确率和召回率的调和平均数)
语言生成任务:bleu、rouge
BLEU(计算候选文本有参考文本之间的n-gram重叠率,侧重精准率,返回blue分数---0~100),
ROUGE(基于召回率指标来衡量系统输出与参考之间相似度,输出rouge-N/L的F1、精确率、召回率)等。
- rouge1 # 基于 1-gram(单个词) 的重叠率,衡量生成文本和参考文本中单个词语的匹配程度。
- rouge2 # 基于 2-gram(连续两个词) 的重叠率,衡量连续词对的匹配程度。
6.2.2 引入依赖以及定义指标函数
from evaluate import load
import os,datasets
import numpy as np
#### 设置为离线操作,不然系统可能会优先从远程加载rouge...之类文件
#os.environ["HF_DATASETS_OFFLINE"] = "1" # 强制使用本地文件
#os.environ["HF_EVALUATE_OFFLINE"] = "1" # 新增:强制evaluate离线
#
#os.environ["TRANSFORMERS_OFFLINE"] = "1" # 可选:如果涉及模型
#
# rouge = load(path = '/root/autodl-tmp/llms/metrics/rouge',cache_dir='./cache')
# bleu = load(path = '/root/autodl-tmp/llms/metrics/bleu',cache_dir='./cache')
rouge = load(
path = 'xxxx路径/metrics/rouge',
download_config=datasets.DownloadConfig(local_files_only=True) # 强制本地模式
)
bleu = load(
path = 'xxxx路径/metrics/bleu',
download_config=datasets.DownloadConfig(local_files_only=True) # 强制本地模式
)
### 指标函数
def eval_metric(eval_predict):
predictions, labels = eval_predict
# 假设 predictions 是 logits,取 argmax 得到预测的 token IDs
pred_ids = np.argmax(predictions, axis=-1) # 直接在CPU处理
# 忽略标签中的填充部分(-100)
# labels[labels == -100] = tokenizer.pad_token_id # 替换为实际的pad_token_id
labels = np.where(labels == -100, tokenizer.pad_token_id, labels)
# # 将 token IDs 解码为文本
# pred_texts = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
# label_texts = tokenizer.batch_decode(labels, skip_special_tokens=True)
# 逐样本解码,减少内存峰值 --- 批量解码的话可能爆显存
pred_texts = []
label_texts = []
for i in range(len(pred_ids)):
pred_text = tokenizer.decode(pred_ids[i], skip_special_tokens=True)
label_text = tokenizer.decode(labels[i], skip_special_tokens=True)
pred_texts.append(pred_text)
label_texts.append([label_text])
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
bleu_result =bleu.compute(
predictions=pred_texts,
references=label_texts
)
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
"""
rouge_types:
ROUGE-1/ROUGE-2:衡量词汇覆盖度(词级匹配)。
ROUGE-L:衡量语义连贯性(句子结构匹配)。
ROUGE-S/ROUGE-SU:适合对词序敏感的任务(如对话生成)。
ROUGE-Lsum:多句子摘要的常用指标(如新闻摘要)。
"""
rouge_result = rouge.compute(
predictions=pred_texts,
references=label_texts,
rouge_types=["rouge1", "rouge2", "rougeL"],
)
return {
"bleu": bleu_result["bleu"],
# evaluate>=0.4.0时,直接返回数值即可。
# # evaluate<0.4.0时,默认返回分位数统计对象,需要通过.mid.fmeasure获取值。
# "rouge1": rouge_result["rouge1"].mid.fmeasure,...
"rouge1": rouge_result["rouge1"], # 基于 1-gram(单个词) 的重叠率,衡量生成文本和参考文本中单个词语的匹配程度。
"rouge2": rouge_result["rouge2"], # 基于 2-gram(连续两个词) 的重叠率,衡量连续词对的匹配程度。
"rougeL": rouge_result["rougeL"] # 基于 最长公共子序列(Longest Common Subsequence, LCS),衡量生成文本与参考文本中最长的连续匹配序列。
}注意:此处需要访问github...国内网络可能.....
在我们使用Bleu、F1、Rouge之类指标时,正常情况下要去huggingfacce中下载f1、acuracy函数,但是我们可以去github的huggingface/evaluate 库将它下载,然后把其中的“metrics”文件夹放在我这个项目下即可。但是Bleu比较例外,此处有时候会发癫...明明使用了本地路径但是依然要去远程加载bleu相关文件
解决方法:
需要先下载:“https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py”里面的内容,重命名后放在"metrics/bleu/"目录下面(重命名:custom_bleu.py),然后将bleu.py里面的“from .nmt_bleu import compute_bleu # From: https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py” 替换为custom_bleu.py即可即替换为“from .custom_bleu import compute_bleu”
------ 不然系统有时候会去“https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py”重新下载文件....
6.2.3 创建训练器
# 基础版 - 训练器加载
trainer = Trainer(
model=peft_model,
args=args,
train_dataset=tokenizer_ds,
eval_dataset=tokenizer_test,
# train_dataset=tokenized_ds.select(range(100)), # 选择前100条训练
# eval_dataset=tokenizer_test.select(range(110)),
# 构建一个个批次数据所需要的
data_collator=DataCollatorForSeq2Seq(
tokenizer=tokenizer,
pad_to_multiple_of=8, # 对齐到8的倍数提升计算效率
# padding=True,
padding="max_length", # 强制填充到 max_length
max_length=512, # 确保所有样本长度为512
return_tensors='pt'
),
compute_metrics = eval_metric,
)
print("加载trainer成功")6.3 添加早停函数 ---- 根据实际情况是否添加
# 添加早停回调
from transformers import EarlyStoppingCallback
# 添加早停回调
trainer.add_callback(EarlyStoppingCallback(
early_stopping_patience=3, # 连续3次评估无改进则停止
early_stopping_threshold=0.01 # 改进阈值
))6.4 Train参数详解
- model (PreTrainedModel 或 torch.nn.Module, 可选):要进行训练、评估或预测的实例化后模型,如果不提供,必须传递一个 model_init来初始化一个模型。
- args (TrainingArguments, 可选):训练的参数,如果不提供,就会使用默认的TrainingArguments 里面的参数,其中 output_dir 设置为当前目录中的名为 "tmp_trainer" 的目录。
- data_collator (DataCollator, 可选):用于从 train_dataset 或 eval_dataset 中构成batch的函数,如果未提供tokenizer,将默认使用 default_data_collator();如果提供,将使用 DataCollatorWithPadding 。
- train_dataset (torch.utils.data.Dataset 或 torch.utils.data.IterableDataset, 可选):用于训练的数据集,如果是torch.utils.data.Dataset,则会自动删除模型的 forward() 方法不接受的列。
- eval_dataset (Union[torch.utils.data.Dataset, Dict[str, torch.utils.data.Dataset]), 可选):同上,用于评估的数据集,如果是字典,将对每个数据集进行评估,并在指标名称前附加字典的键值。
- tokenizer (PreTrainedTokenizerBase, 可选):用于预处理数据的分词器,如果提供,将在批量输入时自动对输入进行填充到最大长度,并会保存在模型目录下中,为了重新运行中断的训练或重复微调模型时更容易进行操作。
- model_init (Callable[[], PreTrainedModel], 可选):用于实例化要使用的模型的函数,如果提供,每次调用 train() 时都会从此函数给出的模型的新实例开始。
- compute_metrics (Callable[[EvalPrediction], Dict], 可选):用于在评估时计算指标的函数,必须接受 EvalPrediction 作为入参,并返回一个字典,其中包含了不同性能指标的名称和相应的数值,一般是准确度、精确度、召回率、F1 分数等。
- callbacks (TrainerCallback 列表, 可选):自定义回调函数,如果要删除使用的默认回调函数,要使用 Trainer.remove_callback() 方法。
- optimizers (Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR], 可选):用于指定一个包含优化器和学习率调度器的元组(Tuple),这个元组的两个元素分别是优化器(torch.optim.Optimizer)和学习率调度器(torch.optim.lr_scheduler.LambdaLR),默认会创建一个基于AdamW优化器的实例,并使用 get_linear_schedule_with_warmup() 函数创建一个学习率调度器。
- preprocess_logits_for_metrics (Callable[[torch.Tensor, torch.Tensor], torch.Tensor], 可选):用于指定一个函数,这个函数在每次评估步骤(evaluation step)前,其实就是在进入compute_metrics函数前对模型的输出 logits 进行预处理。接受两个张量(tensors)作为参数,一个是模型的输出 logits,另一个是真实标签(labels)。然后返回一个经过预处理后的 logits 张量,给到compute_metrics函数作为参数。
Step7 训练
trainer.train()Step8 模型保存 - 训练后使用
8.1 只保存了适配器
必须保存:tokenizer.json、vocab.txt,不然加载的时候会报错
# 训练完成后,保存模型、LoRa适配器、以及tokenizer.json、vocab.txt
peft_model.save_pretrained(output_path) # 保存的adapter适配器
# 保存tokenizer,如果不保存 可能无法加载到“tokenizer.json”文件导致报错...
tokenizer.save_pretrained(output_path)
8.2 模型融合并保存
merge_model = peft_model.merge_and_unload() # 合并适配器
# 训练完成后,保存模型、LoRa适配器、以及tokenizer.json、vocab.txt
merge_model.save_pretrained(output_path+'/merge_model') # 真正的模型
# 保存tokenizer,如果不保存 可能无法加载到“tokenizer.json”文件导致报错...
tokenizer.save_pretrained(output_path)
Step9 模型推理 --- 训练完后,显存中使用
# 切换评估模式
peft_model.eval()9.1 单条推理
input_text = "java是什么?"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# 生成文本
with torch.no_grad():
outputs = peft_model.generate(
**inputs,
max_length=50,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id,
top_p=0.9,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))9.2 批量推理
import pandas as pd
def generate_sample(test_questions):
results = []
for q in test_questions:
inputs_ = tokenizer.apply_chat_template(
[{"role": "user", "content": q}],
add_generation_prompt=True,
tokenize = True,
return_tensors="pt",
return_dict=True
).to(model.device)
outputs_ = peft_model.generate(
**inputs_,
max_new_tokens=512,
temperature=0.95,
top_p=0.7,
# do_sample=False, # 运行过程中采样
repetition_penalty=1.1 # 抑制重复
)
response_ = tokenizer.decode(outputs_[0], skip_special_tokens=True)
results.append({"Question": q, "Response": response_})
return pd.DataFrame(results)
# 自定义测试问题
test_questions = [
"java是什么?",
"C++是什么",
"AI是什么...."
]
# 生成结果
result_df = generate_sample(test_questions)
result_df.to_csv("generation_samples.csv", index=False)
print("执行完毕...")Step10 模型评估
### 其实就是重新验证一遍,如果数据量太大的话,可以直接使用Loss可视化,不然要重新执行
metrics = trainer.evaluate(tokenizer_test.select(range(50)))
metricsStep11 模型预测
predictions = trainer.predict(tokenizer_ds.select(range(110)))
predictionsStep12 模型Loss可视化
from evaluate import load
import numpy as np
# 训练后查看指标日志
final_metrics = trainer.evaluate()
# 可视化训练过程(需要安装matplotlib)
import matplotlib.pyplot as plt
log_history = trainer.state.log_history
train_loss = [x['loss'] for x in log_history if 'loss' in x]
eval_loss = [x['eval_loss'] for x in log_history if 'eval_loss' in x]
plt.figure(figsize=(10,5))
plt.plot(train_loss, label="Training Loss")
plt.plot(eval_loss, label="Validation Loss")
plt.xlabel("Steps")
plt.ylabel("Loss")
plt.legend()
# 查看training_curve.png确认无过拟合
plt.savefig("training_curve.png")
print('打印成功...')。。。。。
扛不住了。....休息下,接下来会更新“数据集定义、微调过程中注意事项、使用融合前模型、模型评估、评估指标测试、使用融合后的模型”之类(都是本文的细分----无非就是本文是在训练后使用train,剩下的就是保存模型后单独加载使用....)
真的真的真的真的好难写,好难整理,还有这么多....

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









