







其他文章
服务容错治理框架resilience4j&sentinel基础应用---微服务的限流/熔断/降级解决方案-CSDN博客
快速搭建对象存储服务 - Minio,并解决临时地址暴露ip、短链接请求改变浏览器地址等问题-CSDN博客
使用LangGraph构建多代理Agent、RAG-CSDN博客
大模型LLMs框架Langchain之链详解_langchain.llms.base.llm详解-CSDN博客
大模型LLMs基于Langchain+FAISS+Ollama/Deepseek/Qwen/OpenAI的RAG检索方法以及优化_faiss ollamaembeddings-CSDN博客
大模型LLM基于PEFT的LoRA微调详细步骤---第二篇:环境及其详细流程篇-CSDN博客
大模型LLM基于PEFT的LoRA微调详细步骤---第一篇:模型下载篇_vocab.json merges.txt资源文件下载-CSDN博客 使用docker-compose安装Redis的主从+哨兵模式_使用docker部署redis 一主一从一哨兵模式 csdn-CSDN博客
docker-compose安装canal并利用rabbitmq同步多个mysql数据_docker-compose canal-CSDN博客
目录
写在前文
友情提示:使用人机协作和持久化测试的时候最好使用jupyter编辑,不然看不出效果。
本文主要案例包含官方案例:Base版本、记忆内存、人类介入/人机协作、时间倒带、增强机器人;
本文内存使用本地内存持久化,除此之外还可以使用自定义的Redis、PostgresSQL数据库...官方推荐使用MongoDB、PostgresSQL,如果使用Redis/其他比如MySQL、Oracle的话,需要自己自定义put/get...之类要求方法
本文主要实现的功能:人机协作,比如当程序执行到某个步骤以后,需要人工审核,通过审核后执行A链,没有通过审核那么就执行B链或者直接提前结束之类。
工具方法
保存图的形状到本地
可以通过下面代码将图保存到本地,
注意:此时如果要执行代码的话,需要联网状态,调用的draw_mermaid_png这个API的话它会默认使用线上的服务,有时候,如果是使用的移动wifi的话,系统要报错“ConnectionError: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))。也可能报错:ReadTimeout: HTTPSConnectionPool(host='mermaid.ink', port=443): Read timed out. (read timeout=10)”这是因为,有的wifi(比如部分随身wifi)它连接不了“Mermaid Ink”这个网站,而这个API默认使用的是这个网站...。
# 把图保存存储到本地
with open('./测试版本.png', 'wb') as f:
f.write(graph.get_graph().draw_mermaid_png())解决办法:
1、要么在本地部署一个离线---但是很麻烦,还需要下载很多东西。
2、换个wifi(比如手机热点)
3、开VPN转发一次。
4、使用graph.get_graph().draw_png(),
注意:但是可能会要求下载:pip install pygraphviz,但是下载这个好像需要C++系列的编译器,比较麻烦...
graph.get_graph().draw_png("./人工协助_interrupt.png")5、最简单的办法就是调用:graph.get_graph().draw_mermaid(),获取获取到离线代码,然后通过在线mermaid编译器手动编译即可.
print(graph.get_graph().draw_mermaid())
输出示例: --- 只需要全部复制到第三方在线网站即可,比如:https://www.jyshare.com/front-end/9729/
---
config:
flowchart:
curve: linear
---
graph TD;
__start__([<p>__start__</p>]):::first
chatbot(chatbot)
tools(tools)
__end__([<p>__end__</p>]):::last
__start__ --> chatbot;
tools --> chatbot;
chatbot -.-> tools;
chatbot -.-> __end__;
classDef default fill:#f2f0ff,line-height:1.2
classDef first fill-opacity:0
classDef last fill:#bfb6fc
查看图中断点
# 在中断以后可以执行,查看中断点...
snapshot = graph.get_state(config)
print(f"中断点:{snapshot.next}")时间倒带
主要作用就是查看该config对应的执行流程,倒着查看。
然后也可以通过state.values查看到该节点的输入/输出。
也可以根据config的checkpoint_id指定从该节点重新执行
# 倒带:可以查看每一个执行的历史信息
to_replay = None
graph = builder.compile(checkpointer=memory)
for state in graph.get_state_history(config):
# Num Messages: 2 Next: ('tools',)
# ----------------------------------------
# Num Messages: 1 Next: ('chatbot1',)
# ----------------------------------------
# Num Messages: 0 Next: ('__start__',)
# ----------------------------------------
print("Num Messages: ", len(state.values["messages"]), "Next: ", state.next)
print("-" * 50)
if len(state.values["messages"]) == 6: # 找到具体的某个状态.
to_replay = state
# 倒带: 从该状态重新开始执行
if to_replay:
# 使用原始状态的配置(包含checkpoint_id)
# 注意 检查点的 config (to_replay.config) 包含一个 checkpoint_id 时间戳。提供此 checkpoint_id 值会告诉 LangGraph 的检查点程序加载该时刻的状态
for event in graph.stream(None, to_replay.config, stream_mode="values"):
if "messages" in event:
event["messages"][-1].pretty_print()Base版本
--- 只实现了持久化,主要是为了展示Memory输出的数据结构
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
llm = ChatOllama(model='qwen2.5:0.5b')
memory = MemorySaver()
@tool
def add_(a, b):
"""两个数相加时使用"""
print(f"[{a, b}]")
return a + b
tools = [add_]
config = {
"configurable": {"thread_id": "12345"},
# "callbacks": [ConsoleCallbackHandler()]
}
graph = create_react_agent(llm, tools=tools, checkpointer=memory)
print(graph.invoke({"messages": "请使用我的工具告诉我1+8等于多少?"}, config=config))
[(1, 8)]
{'messages': [HumanMessage(content='请使用我的工具告诉我1+8等于多少?', additional_kwargs={}, response_metadata={}, id='2d12c5b3-0c68-409b-8562-c6479f4840f7'),
AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'qwen2.5:0.5b', 'created_at': '2025-04-03T06:05:54.30985Z', 'done': True, 'done_reason': 'stop', 'total_duration': 487245400, 'load_duration': 45854200, 'prompt_eval_count': 171, 'prompt_eval_duration': 59070900, 'eval_count': 25, 'eval_duration': 377284000, 'message': Message(role='assistant', content='', images=None, tool_calls=None)}, id='run-f9afe408-953c-4d9c-a106-13a9423fda9e-0', tool_calls=[{'name': 'add_', 'args': {'a': 1, 'b': 8}, 'id': '42456b6f-dc95-48f0-b073-66629c85fd2f', 'type': 'tool_call'}], usage_metadata={'input_tokens': 171, 'output_tokens': 25, 'total_tokens': 196}),
ToolMessage(content='9', name='add_', id='4298e9c9-aaa6-4346-994b-0df34b6cb3de', tool_call_id='42456b6f-dc95-48f0-b073-66629c85fd2f'),
AIMessage(content='根据您的输入,1+8等于9。', additional_kwargs={}, response_metadata={'model': 'qwen2.5:0.5b', 'created_at': '2025-04-03T06:05:54.6557711Z', 'done': True, 'done_reason': 'stop', 'total_duration': 339560800, 'load_duration': 27290200, 'prompt_eval_count': 212, 'prompt_eval_duration': 140953400, 'eval_count': 11, 'eval_duration': 161574600, 'message': Message(role='assistant', content='根据您的输入,1+8等于9。', images=None, tool_calls=None)}, id='run-20e4819a-82a0-4f33-9267-235dac55f10f-0', usage_metadata={'input_tokens': 212, 'output_tokens': 11, 'total_tokens': 223})]}print(memory.get_tuple(config))
CheckpointTuple(config={'configurable': {'thread_id': '12345', 'checkpoint_ns': '', 'checkpoint_id': '1f010519-f998-6855-8001-a90e4de361fa'}}, checkpoint={'v': 2, 'ts': '2025-04-03T06:05:20.452002+00:00', 'id': '1f010519-f998-6855-8001-a90e4de361fa', 'channel_versions': {'__start__': '00000000000000000000000000000002.0.8362226917142827', 'messages': '00000000000000000000000000000003.0.2020983486918615', 'branch:to:agent': '00000000000000000000000000000003.0.26495561753758357'}, 'versions_seen': {'__input__': {}, '__start__': {'__start__': '00000000000000000000000000000001.0.12830794225861109'}, 'agent': {'branch:to:agent': '00000000000000000000000000000002.0.8188303821143136'}}, 'channel_values': {'messages': [HumanMessage(content='1U8等于多少?', additional_kwargs={}, response_metadata={}, id='52be76d9-e586-472d-9a73-d0cf8d7d1d76'), AIMessage(content='对不起,我不能直接计算这个。但我可以告诉你,1U8是一个特殊的数,它实际上代表的是没有数字的运算形式。在数学中,这种形式不被广泛接受和使用,也不被视为任何具体的数值。如果你能提供一个具体的操作或表达式,请告诉我,我可以帮助你进行相应的数学操作。', additional_kwargs={}, response_metadata={'model': 'qwen2.5:0.5b', 'created_at': '2025-04-03T06:05:20.4503128Z', 'done': True, 'done_reason': 'stop', 'total_duration': 2924754900, 'load_duration': 1209905500, 'prompt_eval_count': 166, 'prompt_eval_duration': 666897800, 'eval_count': 69, 'eval_duration': 1043721800, 'message': {'role': 'assistant', 'content': '对不起,我不能直接计算这个。但我可以告诉你,1U8是一个特殊的数,它实际上代表的是没有数字的运算形式。在数学中,这种形式不被广泛接受和使用,也不被视为任何具体的数值。如果你能提供一个具体的操作或表达式,请告诉我,我可以帮助你进行相应的数学操作。', 'images': None, 'tool_calls': None}}, id='run-12a234fb-c61e-4b52-ba5d-646e9d4e1132-0', usage_metadata={'input_tokens': 166, 'output_tokens': 69, 'total_tokens': 235})]}, 'pending_sends': []}, metadata={'source': 'loop', 'writes': {'agent': {'messages': [AIMessage(content='对不起,我不能直接计算这个。但我可以告诉你,1U8是一个特殊的数,它实际上代表的是没有数字的运算形式。在数学中,这种形式不被广泛接受和使用,也不被视为任何具体的数值。如果你能提供一个具体的操作或表达式,请告诉我,我可以帮助你进行相应的数学操作。', additional_kwargs={}, response_metadata={'model': 'qwen2.5:0.5b', 'created_at': '2025-04-03T06:05:20.4503128Z', 'done': True, 'done_reason': 'stop', 'total_duration': 2924754900, 'load_duration': 1209905500, 'prompt_eval_count': 166, 'prompt_eval_duration': 666897800, 'eval_count': 69, 'eval_duration': 1043721800, 'message': {'role': 'assistant', 'content': '对不起,我不能直接计算这个。但我可以告诉你,1U8是一个特殊的数,它实际上代表的是没有数字的运算形式。在数学中,这种形式不被广泛接受和使用,也不被视为任何具体的数值。如果你能提供一个具体的操作或表达式,请告诉我,我可以帮助你进行相应的数学操作。', 'images': None, 'tool_calls': None}}, id='run-12a234fb-c61e-4b52-ba5d-646e9d4e1132-0', usage_metadata={'input_tokens': 166, 'output_tokens': 69, 'total_tokens': 235})]}}, 'step': 1, 'parents': {}, 'thread_id': '12345'}, parent_config={'configurable': {'thread_id': '12345', 'checkpoint_ns': '', 'checkpoint_id': '1f010519-dd96-6c90-8000-2e590460b0e7'}}, pending_writes=[])print(memory.get(config))
{'v': 2,
'ts': '2025-04-03T06:05:54.656961+00:00',
'id': '1f01051b-3fce-6156-8003-50490775334d',
'channel_versions': {'__start__': '00000000000000000000000000000002.0.7223460802266147',
'messages': '00000000000000000000000000000005.0.3757530870598007',
'branch:to:agent': '00000000000000000000000000000005.0.6882549520445602',
'branch:to:tools': '00000000000000000000000000000004.0.4980900768527453'},
'versions_seen': {'__input__': {},
'__start__': {'__start__': '00000000000000000000000000000001.0.039919075880356036'},
'agent': {'branch:to:agent': '00000000000000000000000000000004.0.6659024186473788'},
'tools': {'branch:to:tools': '00000000000000000000000000000003.0.9236884136827139'}},
'channel_values': {'messages': [HumanMessage(content='请使用我的工具告诉我1+8等于多少?', additional_kwargs={}, response_metadata={}, id='2d12c5b3-0c68-409b-8562-c6479f4840f7'),
AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'qwen2.5:0.5b', 'created_at': '2025-04-03T06:05:54.30985Z', 'done': True, 'done_reason': 'stop', 'total_duration': 487245400, 'load_duration': 45854200, 'prompt_eval_count': 171, 'prompt_eval_duration': 59070900, 'eval_count': 25, 'eval_duration': 377284000, 'message': {'role': 'assistant', 'content': '', 'images': None, 'tool_calls': None}}, id='run-f9afe408-953c-4d9c-a106-13a9423fda9e-0', tool_calls=[{'name': 'add_', 'args': {'a': 1, 'b': 8}, 'id': '42456b6f-dc95-48f0-b073-66629c85fd2f', 'type': 'tool_call'}], usage_metadata={'input_tokens': 171, 'output_tokens': 25, 'total_tokens': 196}),
ToolMessage(content='9', name='add_', id='4298e9c9-aaa6-4346-994b-0df34b6cb3de', tool_call_id='42456b6f-dc95-48f0-b073-66629c85fd2f'),
AIMessage(content='根据您的输入,1+8等于9。', additional_kwargs={}, response_metadata={'model': 'qwen2.5:0.5b', 'created_at': '2025-04-03T06:05:54.6557711Z', 'done': True, 'done_reason': 'stop', 'total_duration': 339560800, 'load_duration': 27290200, 'prompt_eval_count': 212, 'prompt_eval_duration': 140953400, 'eval_count': 11, 'eval_duration': 161574600, 'message': {'role': 'assistant', 'content': '根据您的输入,1+8等于9。', 'images': None, 'tool_calls': None}}, id='run-20e4819a-82a0-4f33-9267-235dac55f10f-0', usage_metadata={'input_tokens': 212, 'output_tokens': 11, 'total_tokens': 223})]},
'pending_sends': []}自定义路由的工具结合版本
不使用:官方的ToolNode来构建tools以及tools_condition构建路由链。使用自定义的BasicToolNode和route_tools路由工具方法
from typing import TypedDict, Annotated, Optional
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.tools import tool
from langchain_core.tracers import ConsoleCallbackHandler
from langchain_ollama import ChatOllama
from langgraph.constants import START, END
from langgraph.graph import StateGraph, add_messages
from langgraph.prebuilt import tools_condition
from pydantic import BaseModel, Field
# 1、创建工具
@tool('add', return_direct=True, description="两个数相加时使用")
def add_(a, b):
print(f"调用了相加计算工具:{a, b}")
return a + b
@tool('weather', return_direct=True, description="需要查询天气时才使用")
def weather_(city: str):
print(f"调用了查询城市天气的tool:{city}")
return f"{city}\n气温:18°\n空气质量:优\n天气:阴天\n"
# 初始化工具列表
tools = [add_, weather_]
# 2、初始化LLM
llm = ChatOllama(model='llama3.2:latest')
# 将工具绑定在模型中
llm_with_tools = llm.bind_tools(tools)
# Step1 状态
class State(TypedDict):
messages: Annotated[list, add_messages]
# 相当于tools = ToolNode(tools=tools)的ToolNode类
class BasicToolNode:
def __init__(self, tools: list):
self.tools = tools
# {'weather', 'add'}
self.tools_by_name = {tool.name: tool for tool in tools}
print(f"工具初始化完成,可用工具:{tools}")
def __call__(self, inputs):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
# 核心就是:取出LLMs返回的信息里面的tool_calls然后对比工具...
# 这种方法只适合返回tool_calls的LLMs,有些LLMs不会返回
tool_result = self.tools_by_name[tool_call["name"]].invoke(tool_call["args"])
from langchain_core.messages import ToolMessage
import json
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
workflow = StateGraph(State)
workflow.add_node("chatbot1", chatbot)
# 工具节点 也可以使用官方快捷的“tools = ToolNode(tools=tools)”
tool_node = BasicToolNode(tools)
workflow.add_node("tool_nodes1", tool_node)
# 官方路由的方法:tools_condition
def route_tools(state: State):
# {'messages': [
# HumanMessage(
# content='1+1等于?',
# additional_kwargs={},
# response_metadata={},
# id='48517cd2-0bd6-4d93-9bf8-c02d4d1997ab'
# ),
# AIMessage(content='',
# additional_kwargs={},
# response_metadata={
# 'model': 'llama3.2:latest',
# 'created_at': '2025-04-02T05:23:43....4e0f-bdb6-019e142fc64e',
# 'type': 'tool_call'
# }
# ],
# usage_metadata = {'input_tokens': 208, 'output_tokens': 22, 'total_tokens': 230})]}
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tool_n"
return END
# 根据route_tools返回的值判断path_map的值。如果是tool_n那么就返回tool_nodes1,如果是END那么就返回END直接结束。
route_tools以及path_map可以使用“tools_condition”替换
workflow.add_conditional_edges(
"chatbot1",
route_tools, # 即路由,需要告诉模型下一步(即path_map映射)走哪儿,
{"tool_n": "tool_nodes1", END: END},
)
workflow.add_edge("tool_nodes1", "chatbot1")
workflow.add_edge(START, "chatbot1")
graph = workflow.compile()
config = {"configurable": {"thread_id": "123456"}}
events1 = graph.stream({"messages": [{"role": "user", "content": "hi,我叫张三,请问1+1等于几?"}]}, config,
stream_mode="values")
for event in events1:
event["messages"][-1].pretty_print()
print("-" * 100)
events2 = graph.stream({"messages": [{"role": "user", "content": "请重复下我刚刚问的问题!"}]}, config,
stream_mode="values")
for event in events2:
event["messages"][-1].pretty_print()
print("-" * 100)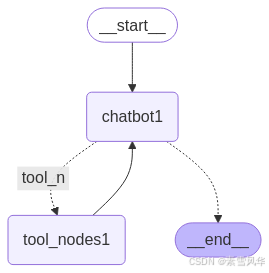
不需要人工协作的Graph
from langgraph.constants import START, END
from typing import Optional, TypedDict, Annotated
from langgraph.graph import add_messages, StateGraph
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
llm = ChatOllama(model='qwen2.5:0.5b')
memory = MemorySaver()
@tool
def add_(a, b):
"""两个数相加时使用"""
print(f"[{a, b}]")
return a + b
tools = [add_]
config = {
"configurable": {"thread_id": "12345"},
# "callbacks": [ConsoleCallbackHandler()]
}
llm_with_tools = llm.bind_tools(tools)
class StateMess(TypedDict):
messages: Annotated[list, add_messages]
def gen_messages(state: StateMess):
"""调用工具生成消息"""
return {"messages": [llm_with_tools.invoke(state["messages"])]}
builder = StateGraph(StateMess)
# 添加第一个节点
builder.add_node("chatbot", action=gen_messages)
# 添加开始
builder.add_edge(START,"chatbot")
# 添加结束
builder.add_edge("chatbot", END)
# 构建一个图
graph = builder.compile(checkpointer=memory)
result = graph.invoke({"messages":"你是谁?"},config=config)
result['messages'][-1].content 最终结构我们构建出来的图结构为: START----> chatbot ----> END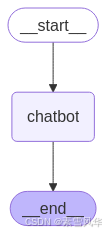
人工协作
人工协作有两种,一种是在定义graph的时候使用“interrupt_before”在进入对应节点前进行拦截;另外一种是在方法内部使用“interrupt”直接断掉。断掉之后可以使用上文工具方法中“查看图中断点”方法查看是在哪里断掉的。
节点前中断:使用interrupt_before
from langgraph.constants import START
from typing import Optional, TypedDict, Annotated
from langgraph.graph import add_messages, StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
llm = ChatOllama(model='qwen2.5:0.5b')
memory = MemorySaver()
@tool
def add_(a, b):
"""两个数相加时使用"""
print(f"[{a, b}]")
return a + b
tools = [add_]
config = {
"configurable": {"thread_id": "12345"},
# "callbacks": [ConsoleCallbackHandler()]
}
llm_with_tools = llm.bind_tools(tools)
class StateMess(TypedDict):
messages: Annotated[list, add_messages]
def gen_messages(state: StateMess):
"""调用工具生成消息"""
return {"messages": [llm_with_tools.invoke(state["messages"])]}
builder = StateGraph(StateMess)
# 添加第一个节点
builder.add_node("chatbot", action=gen_messages)
builder.add_node("tools", ToolNode(tools=tools)) # 创建工具节点
builder.add_conditional_edges(
"chatbot",
tools_condition
)
builder.add_edge(START, "chatbot")
builder.add_edge("tools", "chatbot")
# 如果要走tools工具时,那么系统会自动断掉,此时我们可以通过 下面来查看断点在哪里
# snapshot = graph.get_state(config)
# print(f"中断点:{snapshot.next}")
graph = builder.compile(checkpointer=memory, interrupt_before=['tools'])
with open('./测试版本.png', 'wb') as f:
f.write(graph.get_graph().draw_mermaid_png())
graph.invoke({"messages": "1+1等于几?"}, config=config)查看断点位置
# 在上面中断以后可以执行,查看中断点...
snapshot = graph.get_state(config)
print(f"中断点:{snapshot.next}")此时中断以后,唤醒执行
可以使用“graph.stream(None, config, stream_mode="values")”继续执行中断后的方法
# 中断以后,我们可以使用这中方法从内存中加载出来,然后继续执行
# 这种方法是直接继续。
# 执行完毕以后再执行:graph.get_state(config).next,就可以发现这个thread_id对应的断点打印出来的为None
events = graph.stream(None, config, stream_mode="values")
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()图形状如下:
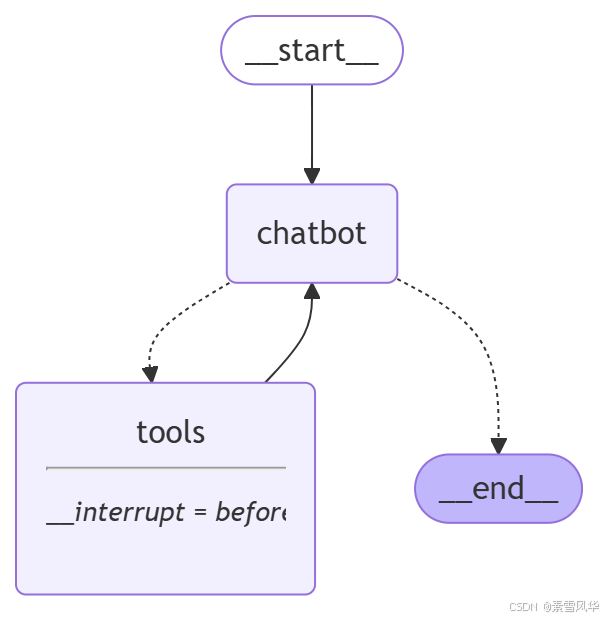
节点(方法)中中断:interrupt
from agent_tool import utils
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import interrupt
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.constants import START
from typing import Optional, TypedDict, Annotated
from langgraph.graph import add_messages, StateGraph
from langchain_core.tools import tool
# llm = ChatOllama(model='qwen2.5:0.5b')
llm = ChatOllama(model='llama3.2:latest')
# llm = utils.get_llm('glm')
memory = MemorySaver()
@tool("add")
def add_(a, b):
"""当用户使用(V_V)符号表示加法时调用此工具"""
print(f"调用了add方法:[{a, b}]")
return a + b
@tool("human_assistance")
def human_assistance_(query):
"""需要人类介入辅助完成的任务
Step1 系统第一个query,进入到这里面会在interrupt断掉 --- 可以使用graph.get_state(config).next查看;
Step2 等待人工处理
Step3 人工处理时 需要输入新的内容,并且可以通过 "Command(resume={"data": human_response}) "的方式将内容传递到这里面来
如果用户没有输入新的内容,那么在调用: graph.stream(None, config, stream_mode="values")时,系统会继续进入到human_assistance_方法里面来,会一致卡在interrupt方法处
如果我们通过Command输入了新的内容,那么"human_response = interrupt({"query": query})"获取到的就是新输入的内容
这样我们就可以通过human_response["data"]获取到用户输入的新的内容
---这与通过"interrupt_before=['tools']"构建的有差别interrupt_before输入的为None就是原封不动的传入
注意,在这个案例中,我们是通过加载MemorySaver()也就是thread_id,来区分不同用户的处理状态.
真实工作中,可以通过自定义checkpointer比如Redis来存储---不过redis好像需要自己写put/get之类方法.
官方推荐使用PS(PostgreSQL)数据库
所以在human_response中获取到的data,应该是人工输入的新的内容.
"""
print(f"需要人类介入辅助完成的任务:[{query}]")
# 暂停执行,保存状态,等待外部系统提供数据响应
human_response = interrupt({"query": query})
data = human_response["data"] # 获取的应该是通过"Command(resume={"data": human_response})"输入的data ,
print(f"data:{data}")
return data
tools = [add_, human_assistance_]
llm_with_tools = llm.bind_tools(tools)
config = {
"configurable": {"thread_id": "12345"},
# "callbacks": [ConsoleCallbackHandler()]
}
class StateMess(TypedDict):
messages: Annotated[list, add_messages]
# 定义relevance_score字段,用于存储文档相关性评分
relevance_score: Annotated[Optional[str], "Relevance score of retrieved documents, 'yes' or 'no'"]
# 定义rewrite_count字段,用于跟踪问题重写的次数,达到次数退出graph的递归循环
rewrite_count: Annotated[int, "Number of times query has been rewritten"]
def gen_messages(state: StateMess):
"""调用工具生成消息"""
return {"messages": [llm_with_tools.invoke(state["messages"])]}
builder = StateGraph(StateMess)
# 添加第一个节点
builder.add_node("chatbot", action=gen_messages)
builder.add_node("tools", ToolNode(tools=tools)) # 创建工具节点
builder.add_conditional_edges(
"chatbot",
tools_condition # 系统自带的条件
)
builder.add_edge(START, "chatbot")
builder.add_edge("tools", "chatbot")
graph = builder.compile(checkpointer=memory)不进入断点方法
# 理论上是会进入add方法
graph.invoke({"messages": "2(V_V)1等于多少?"}, config=config)进入断点方法,等待人工输入
# 注意,需要在这里检查下AIMessage里面的tool_calls是否为None,
# 如果为None 那么graph.get_state(config).next显示的为None,就没有被断点成功,也就是说没有进入到需要人工介入的方法中
# 此时需要调整提示词或者定义工具时的“description”
# 如果调整以后依然不行,那可能是自己使用的LLMs有问题,性能/质量不行,不太聪明
# 测试,使用qwen2.5:0.5b时就不会进入,但是使用llama3.2:latest或者GLM、deepseek会
result = graph.invoke({"messages": "我需要一些专家来帮我完成一些代理任务。你能帮我请求帮助吗?"}, config=config)
result进入断点后人工输入唤醒
通过分析发现,系统执行顺序为:__start__ ---> chatbot ---> tools ----> chatbot ---> __end__
但是按照我的理想状态应该是:__start__ ---> chatbot ---> tools ----> chatbot ---> tools ---> chatbot ---> __end__
理想状态使用的模型是:GLM、Deepseek;其他模型可能使用的是llama3.1版本的模型
from langchain_core.messages import HumanMessage, ToolMessage
from langgraph.types import Command
# 当系统进入方法human_assistance_中,并且在interrupt断点。后,通过下面方法唤醒.
# 此时,我通过stream重新从断点开始的地方进行执行,
# 正常情况下我理想状态,我发出的命令为“3U5等于多少”我给系统提供的工具中有“add_”方法并且提醒了系统“两个数U加时使用add_”,但是系统并没有执行。
human_response = ("3(V_V)5的值是多少")
human_command = Command(resume={"data": human_response})
for event in graph.stream(human_command, config, stream_mode="values"):
if "messages" in event:
event["messages"][-1].pretty_print()图形状如
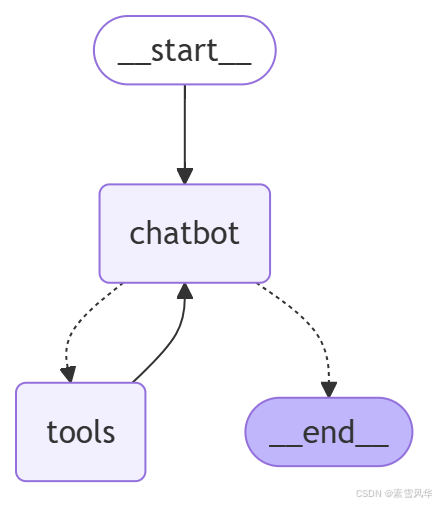
中断后,根据用户输入判断是否继续
from agent_tool import utils
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import interrupt
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.constants import START,END
from typing import Optional, TypedDict, Annotated, Literal
from langgraph.graph import add_messages, StateGraph
from langchain_core.tools import tool
# llm = ChatOllama(model='qwen2.5:0.5b')
llm = ChatOllama(model='llama3.2:latest')
# llm = utils.get_llm('glm')
memory = MemorySaver()
@tool("add")
def add_(a, b):
"""当用户使用(V_V)符号表示加法时调用此工具,如:3(V_V)5=8"""
print(f"调用了add方法:[{a, b}]")
return a + b
@tool("human_assistance")
def human_assistance_(query):
"""需要人类介入辅助完成的任务
Step1 系统第一个query,进入到这里面会在interrupt断掉 --- 可以使用graph.get_state(config).next查看;
Step2 等待人工处理
Step3 人工处理时 需要输入新的内容,并且可以通过 "Command(resume={"data": human_response}) "的方式将内容传递到这里面来
如果用户没有输入新的内容,那么在调用: graph.stream(None, config, stream_mode="values")时,系统会继续进入到human_assistance_方法里面来,会一致卡在interrupt方法处
如果我们通过Command输入了新的内容,那么"human_response = interrupt({"query": query})"获取到的就是新输入的内容
这样我们就可以通过human_response["data"]获取到用户输入的新的内容
---这与通过"interrupt_before=['tools']"构建的有差别interrupt_before输入的为None就是原封不动的传入
注意,在这个案例中,我们是通过加载MemorySaver()也就是thread_id,来区分不同用户的处理状态.
真实工作中,可以通过自定义checkpointer比如Redis来存储---不过redis好像需要自己写put/get之类方法.
官方推荐使用PS(PostgreSQL)数据库
所以在human_response中获取到的data,应该是人工输入的新的内容.
"""
print(f"需要人类介入辅助完成的任务:[{query}]")
# 暂停执行,保存状态,等待外部系统提供数据响应
human_response = interrupt({"query": query})
data = human_response["data"] # 获取的应该是通过"Command(resume={"data": human_response})"输入的data ,
print(f"data:{data}")
# 判断是否需要直接退出
# 理想状态,系统会直接返回“喵~祝您愉快(*Φ皿Φ*)”并进入END结束。
if data.lower() in ["exit", "quit", "q", "不需要"]:
return {"flow_control": "exit", "result": "你是我定义的一个人类辅助助手,但是用户临时取消操作,所以你不需要处理任何事物,只需要直接回复“喵~祝您愉快(*Φ皿Φ*)”即可"}
return {"flow_control": "continue", "result": data} # 返回控制标识和结果
tools = [add_, human_assistance_]
llm_with_tools = llm.bind_tools(tools)
config = {
"configurable": {"thread_id": "12345"},
}
class StateMess(TypedDict):
messages: Annotated[list, add_messages]
flow_control: Annotated[Optional[Literal["continue", "exit"]], "Flow control flag"] # 新增控制字段
def gen_messages(state: StateMess):
"""调用工具生成消息"""
return {"messages": [llm_with_tools.invoke(state["messages"])]}
builder = StateGraph(StateMess)
# 添加第一个节点
builder.add_node("chatbot", action=gen_messages)
builder.add_node("tools", ToolNode(tools=tools)) # 创建工具节点
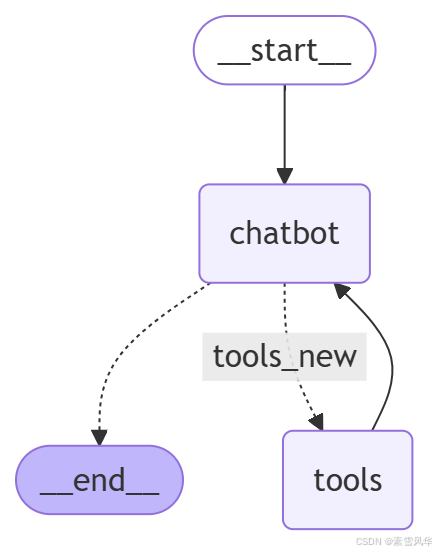
# 修改条件边逻辑 这里取出StateMess判断.
def router(state: StateMess):
# 优先检查流程控制标识
if state.get("messages")[-1].tool_calls:
return "tools_new"
# if state.get("flow_control") == "exit":
return END
builder.add_conditional_edges(
"chatbot",
router,
{
END: END,
"tools_new":"tools",
}
)
builder.add_edge(START, "chatbot")
builder.add_edge("tools", "chatbot")
graph = builder.compile(checkpointer=memory)进入断点
result = graph.invoke({"messages": "我需要一些专家来帮我完成一些代理任务。你能帮我请求帮助吗?"}, config=config)
result人工介入 --- 直接退出
from langchain_core.messages import HumanMessage, ToolMessage
from langgraph.types import Command
# 当系统进入方法human_assistance_中,并且在interrupt断点。后,通过下面方法唤醒.
# 此时,我通过stream重新从断点开始的地方进行执行,
# 正常情况下我理想状态,我发出的命令为“3U5等于多少”我给系统提供的工具中有“add_”方法并且提醒了系统“两个数U加时使用add_”,但是系统并没有执行。
# 通过分析发现,系统执行顺序为:__start__ ---> chatbot ---> tools ----> chatbot ---> __end__ # 使用其他可能不行
# 但是按照我的理想状态应该是:__start__ ---> chatbot ---> tools ----> chatbot ---> tools ---> chatbot ---> __end__ 使用GLM就可
human_response = ("quit")
human_command = Command(resume={"data": human_response})
for event in graph.stream(human_command, config, stream_mode="values"):
if "messages" in event:
event["messages"][-1].pretty_print()图形形状

















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









