







引言
在当今数据驱动的世界中,有效地检索和利用信息是一项关键挑战。在数据库、搜索引擎和众多应用程序中,寻找相似数据是一项基本操作。传统数据库中,基于固定数值标准的相似项搜索相对直接,通过查询语言即可实现,如查找特定工资范围内的员工。然而,当面临更复杂的问题,如“库存中哪些商品与用户搜索项相似?”时,挑战便出现了。用户搜索词可能含糊且多变,如“鞋子”、“黑色鞋子”或“Nike AF-1 LV8”。

为了应对这种复杂性,系统必须能够区分不同搜索词,并理解它们之间的细微差别。例如,理解“黑色鞋子”与普通鞋子之间的区别。这要求系统能够捕捉到对象的深层概念意义。在处理数十亿对象的数据时,这种需求变得尤为突出。
在如此大规模和复杂背景下,传统的基于符号对象表示的数据库搜索方法已不再适用。我们需要更强大的工具来有效搜索语义表示。相似性搜索正是这样一种工具,它利用数据的高级语义表示来快速找到相似项。
相似性搜索,也称为向量搜索,是一种能够根据数据的深层语义和结构相似性来检索信息的技术。它不仅仅局限于文本搜索,还广泛应用于图像识别、推荐系统、语音分析等多个领域。通过将数据转换为高维空间中的向量表示,相似性搜索能够捕捉到数据之间微妙的相似之处,从而提供更加丰富和相关的搜索结果。
相似性搜索的重要性
随着数据量的爆炸性增长,传统数据库搜索面临着前所未有的挑战。在处理大规模数据集时,传统的基于关键字的搜索方法往往无法满足用户对模糊查询和复杂模式识别的需求。相似性搜索的出现,为这些问题提供了创新的解决方案。
1. 解决模糊查询问题:在传统数据库中,模糊查询通常会导致大量不相关的结果,因为它们依赖于精确的关键字匹配。相似性搜索通过理解数据的深层语义,能够识别出与查询意图相关的数据,即使这些数据在表面上并不完全匹配。
2. 处理非结构化数据:随着图像、音频和视频等非结构化数据的大量出现,传统的搜索方法显得力不从心。相似性搜索能够将这些非结构化数据转换为向量表示,从而在向量空间中进行有效的相似性匹配。
3. 提高搜索效率:在处理数百万甚至数十亿条记录时,传统数据库搜索的效率急剧下降。相似性搜索通过使用近似邻近搜索(ANN)技术,能够在保持高准确性的同时,显著提高搜索效率。
4. 支持个性化推荐:在推荐系统中,相似性搜索可以根据用户的历史行为和偏好,找到与之相似的商品或内容,从而提供个性化的推荐。
5. 促进创新应用:相似性搜索的应用不仅限于搜索和推荐系统,它还在图像识别、语音识别、自然语言处理等多个领域发挥着重要作用,推动了人工智能技术的创新和发展。
向量表示与嵌入
在相似性搜索中,向量表示是核心概念之一。它涉及到将现实世界中的对象和概念转换为向量空间中的点,这些点在数学上能够表示对象的属性和相互关系
1. 向量表示的概念:向量表示是一种将对象(如单词、图片、音频片段等)转换为高维空间中的向量的方法。每个维度代表了对象的一个特征或属性。通过这种方式,可以将对象的复杂性和抽象性转化为数学上可处理的格式。
2. 文本数据的向量嵌入:在处理文本数据时,机器学习模型如Word2Vec、GLoVE和Universal Sentence Encoder(USE)被广泛用于创建向量嵌入。这些模型能够理解单词或句子的上下文,并将它们转换为向量。例如,Word2Vec模型通过分析大量文本数据,学习每个单词的向量表示,使得语义相似的单词在向量空间中彼此靠近。
3. 图像数据的向量嵌入:对于图像数据,卷积神经网络(CNN)模型如VGG或ResNet通常用于提取特征并创建向量嵌入。这些模型通过分析图像的像素级信息,提取出能够代表图像内容的高层特征,并将这些特征转换为向量。

4. 向量嵌入的应用:一旦有了向量表示,就可以在向量空间中执行各种操作,如计算对象之间的相似性、进行分类、聚类等。这些操作为机器学习任务提供了强大的工具,使得计算机能够理解和处理复杂的现实世界数据。
向量之间的距离
在相似性搜索中,向量之间的距离度量是判断两个向量相似程度的关键。不同的距离度量方法反映了不同的相似性判断标准,常用的距离度量方法包括欧几里得距离、曼哈顿距离、余弦距离等。
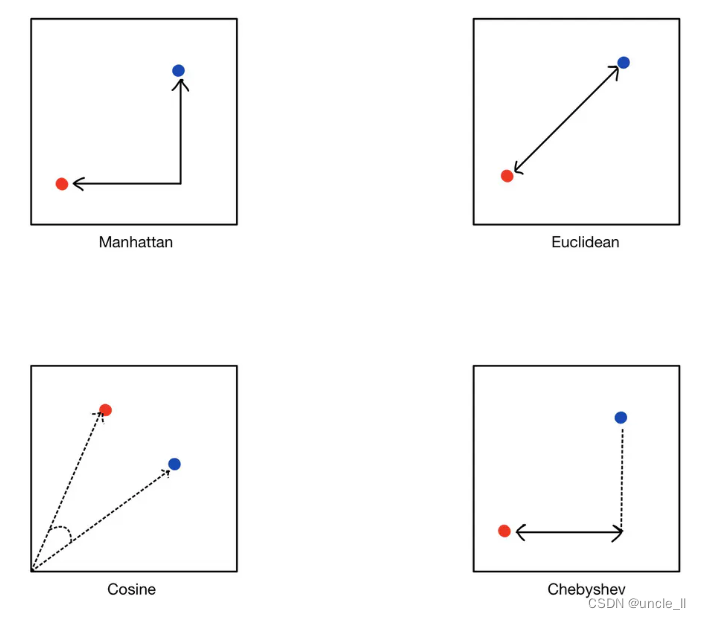
1. 欧几里得距离:这是最常用的距离度量方法,也称为L2范数。它计算的是两点之间的直线距离,即两点在多维空间中的几何距离。欧几里得距离越小,表示两个向量越相似。
2. 曼哈顿距离:也称为L1范数,曼哈顿距离计算的是两点在标准坐标系上的绝对轴距总和。它反映的是在网格状空间中两点之间的距离,适用于那些不能直接走直线的场景。
3. 余弦距离:余弦距离衡量的是两个向量在方向上的相似程度,而不是它们的欧几里得长度。余弦距离的值介于-1和1之间,值越接近1,表示两个向量的方向越相似。
4. 切比雪夫距离:切比雪夫距离是向量空间中的一种度量,它在各个维度上的最大差异决定了两点之间的距离。它对于异常值的影响较小,适用于某些特定的应用场景。
在相似性搜索中,选择合适的距离度量方法取决于具体的应用场景和数据特性。 例如,如果数据中的噪声较多,可能更适合使用曼哈顿距离;而在文本处理中,余弦距离因为能够反映文本的方向相似性,通常是一个更好的选择。通过选择合适的距离度量方法,能够更准确地评估向量之间的相似性,从而在相似性搜索中提供更相关和准确的结果。
执行相似性搜索
通过向量嵌入表示对象,可以利用向量间的距离来衡量对象间的相似性。这就是相似性搜索,或称为向量搜索的核心思想。给定一个查询向量,目标是找到数据集中与之最相似的项目,这通常被称为最近邻搜索。
K最近邻
K最近邻(k-NN)算法是一种流行的方法,用于在向量空间中找到与查询向量最近的向量。这里的k是一个超参数,由我们设定,代表我们希望检索的最近邻的数量。通过对数据集进行k-NN,可以根据向量间的距离来检索查询向量的最近邻。

近似邻近搜索ANN
k-NN算法的主要缺点在于,为了找到查询向量的最近邻,必须计算它与数据集中每个向量的距离。这在处理数百万个向量时变得非常低效。
随着数据量的增长和向量维度的提高,传统的最近邻搜索在计算效率上变得越来越不现实。近似邻近搜索(ANN)是一种旨在解决这一问题的技术,它通过牺牲一定程度的准确性来换取搜索效率的提升。
1. ANN的原理:ANN的基本思想是避免计算查询向量与数据集中每个向量之间的精确距离,而是通过索引结构和搜索算法快速找到一组“近似最近邻”。这些近似最近邻通常足够接近真实的最近邻,从而在大多数应用中仍然能够提供满意的结果。
2. 索引结构:ANN算法通常依赖于复杂的索引结构来组织数据向量,这些索引结构能够快速缩小搜索空间。常见的索引结构包括KD树、球树(Ball Tree)、局部敏感哈希(LSH)等。这些结构通过将数据集分割成多个子集,并在搜索时只考虑最有可能包含最近邻的子集,从而减少需要检查的向量数量。
3. 高维数据处理:在高维空间中,传统的欧几里得距离等度量方法往往失效,因为几乎所有向量之间的距离都变得相似。ANN算法通过使用特殊的度量方法或变换来处理高维数据,例如使用随机投影或非线性映射来降低数据的维度,同时保持数据的重要结构特征。
4. 性能与准确度的平衡:ANN算法的性能与准确度之间存在权衡。更快的搜索通常意味着更高的错误率,即找到的近似最近邻可能与真正的最近邻有所不同。在实际应用中,需要根据具体的需求来调整算法参数,以找到性能与准确度之间的最佳平衡点。
通过使用近似邻近搜索,我们能够在保持搜索效率的同时,处理大规模和高维度的数据集,为现代数据密集型应用提供强大的支持。
相似性搜索的应用案例
相似性搜索作为一种强大的技术,已经在多个领域展现出其广泛的应用价值。以下是一些实际的应用案例,展示了相似性搜索如何在不同场景中发挥作用。
1. 推荐系统:在电子商务和内容平台上,相似性搜索被广泛应用于推荐系统中。通过分析用户的历史行为和偏好,系统可以使用相似性搜索来找到与用户过去喜欢的商品或内容相似的新商品或内容。例如,亚马逊和Netflix就利用相似性搜索来向用户推荐商品和电影。
2. 图像识别:在图像处理和计算机视觉领域,相似性搜索可以帮助识别和处理图像中的对象。例如,在自动驾驶汽车中,相似性搜索可以用来识别道路上的行人、车辆和其他障碍物,从而确保安全驾驶。
3. 语音识别:在语音识别系统中,相似性搜索可以用来匹配用户的语音输入与预定义的语音模式。这有助于提高语音识别的准确性和效率,使得智能助手能够更好地理解和响应用户的语音指令。
4. 文本搜索:在搜索引擎中,相似性搜索可以用来改进文本搜索的结果。通过理解查询的深层语义,搜索引擎可以使用相似性搜索来返回与查询最相关的网页,而不仅仅是字面上匹配的结果。
5. 医疗诊断:在医疗领域,相似性搜索可以用来分析患者的医疗记录和图像,以找到与患者症状和影像学表现相似的病例。这有助于医生做出更准确的诊断和治疗方案。
6. 音乐推荐:音乐流媒体服务如Spotify和Apple Music使用相似性搜索来分析音乐的音频特征,并向用户推荐与他们喜欢的歌曲相似的新音乐。
结论
相似性搜索作为一种能够根据数据的深层语义和结构相似性来检索信息的技术,在现代技术中扮演着至关重要的角色。通过将数据转换为向量表示,并在向量空间中计算它们之间的距离,相似性搜索能够快速找到与查询最相似的数据项。这不仅提高了搜索的效率和准确性,还为推荐系统、图像识别、语音识别等多个领域带来了革命性的变革。
















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











