








一、为什么选择 FastAPI?
想象一下,用 Python 写 API 可以像搭积木一样简单,同时还能拥有媲美 Go 语言的性能,这个框架凭借三大核心优势迅速风靡全球:
- 开发效率提升 3 倍:类型注解 + 自动文档,代码即文档
- 性能碾压传统框架:异步架构 + UJSON 序列化,QPS 轻松破万
- 零配置自动化:Swagger UI/ReDoc 文档、数据验证、依赖注入开箱即用
二、5 分钟快速上手
1. 环境准备
# 安装核心库
pip install fastapi uvicorn pydantic
2. 第一个 API
# main.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
3. 启动服务
uvicorn main:app --reload
4. 访问 API
打开浏览器访问 http://localhost:8000/,你会看到:
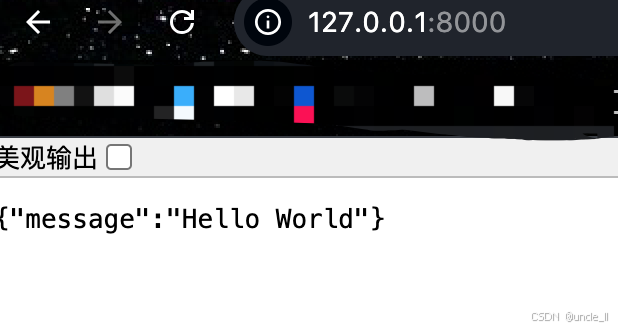
打开浏览器访问 http://localhost:8000/docs,你会看到交互式 API 文档:
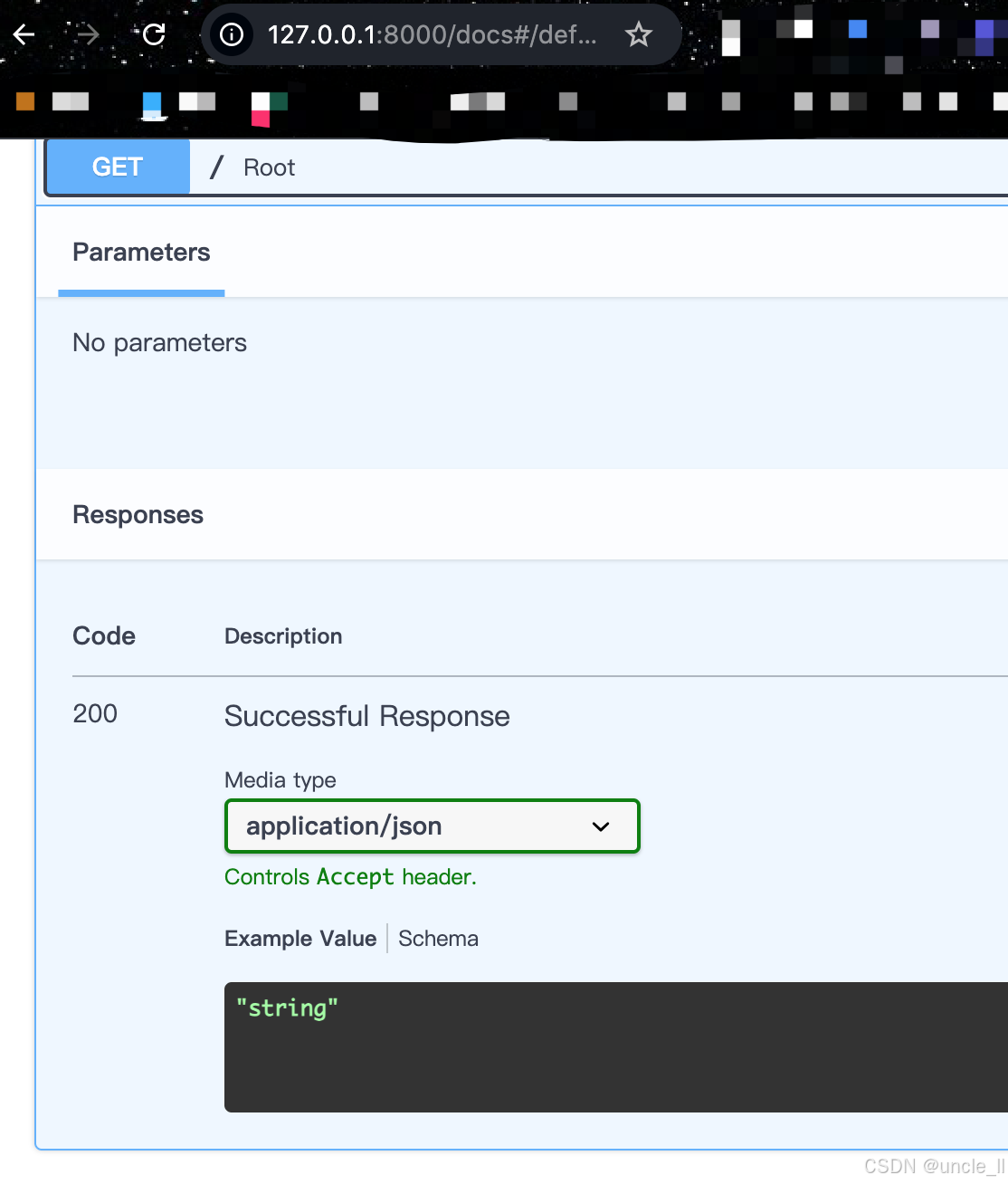
三、核心功能详解
1. 路由系统
路径参数
@app.get("/items/{item_id}")
async def read_item(item_id: int):
return {"item_id": item_id}
查询参数
@app.get("/users")
async def read_users(skip: int = 0, limit: int = 10):
return {"users": fake_users_db[skip : skip + limit]}
响应模型
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
@app.get("/user/{user_id}", response_model=User)
async def get_user(user_id: int):
return User(id=user_id, name="Alice")
2. 数据验证
class Item(BaseModel):
name: str
price: float
is_offer: bool = None
@app.post("/items/")
async def create_item(item: Item):
return {"item_name": item.name, "item_price": item.price}
3. 异步支持
import asyncio
@app.get("/async-task")
async def async_task():
await asyncio.sleep(1) # 模拟耗时操作
return {"result": "Done"}
四、生产级功能
1. 自动文档
- Swagger UI:访问
/docs进行交互式测试 - ReDoc:访问
/redoc获取简洁文档 - OpenAPI 规范:自动生成标准接口契约
2. 依赖注入
def get_db():
db = Database()
try:
yield db
finally:
db.close()
@app.get("/items/")
async def read_items(db: Database = Depends(get_db)):
return db.query("SELECT * FROM items")
3. 中间件
@app.middleware("http")
async def add_process_time_header(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
process_time = time.time() - start_time
response.headers["X-Process-Time"] = str(process_time)
return response
五、进阶技巧
1. 代码结构优化
myapi/
├── main.py
├── routers/
│ ├── items.py
│ └── users.py
├── models.py
└── schemas.py
2. 性能优化
# 使用orjson加速序列化
from fastapi import FastAPI
from fastapi.responses import ORJSONResponse
app = FastAPI(default_response_class=ORJSONResponse)
3. 测试方案
from fastapi.testclient import TestClient
client = TestClient(app)
def test_root():
response = client.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Hello World"}
六、生态工具链
| 工具类型 | 推荐工具 | 核心功能 |
|---|---|---|
| 代码生成 | fastapi-code-generator | 从 OpenAPI 生成项目骨架 |
| 调试工具 | httpie | 命令行 API 测试 |
| 监控 | Prometheus + Grafana | 性能指标可视化 |
| 部署 | Docker + Kubernetes | 云原生部署 |
七、真实案例
某电商平台使用 FastAPI 重构商品推荐接口后:
- 日均请求量从 200 万增至 800 万
- 响应时间中位数从 420ms 降至 110ms
- 接口联调周期缩短 60%
八、常见问题
- 如何处理跨域请求?
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
- 如何自定义异常响应?
@app.exception_handler(ValueError)
async def value_error_handler(request, exc):
return JSONResponse(
status_code=400,
content={"message": f"Invalid value: {exc}"},
)


















 1982
1982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











