









序列最小优化算法(Sequential Minimal Optimization, SMO)是一套训练SVM模型的算法,它能使SVM模型的训练来得更高效、快速和简单。它的核心在于迭代更新方程中的拉格朗日乘数,使得方程最小化,即超平面间隔最大化。终止迭代的条件为函数收敛或迭代次数以达到自定义的最高次数,此时方程已得到对应模型的最佳参数,生成模型。SMO的优势在于不需要QP(Quadratic Programming)分解器来求解,直接通过内循环启发式和外循环启发式分析求解即可,故不需要大量的空间来存储大矩阵。
代码中的算法说明
代码中使用SMO算法对IRIS数据集进行SVM的分类,主要是为了最大化超平面之间的间隔,即最小化以下方程:
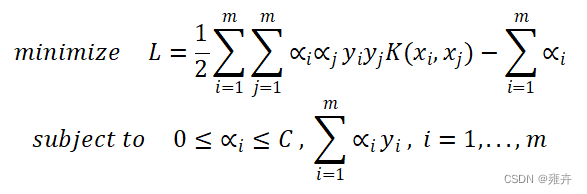
代码中使用的核函数为径向基核函数(Radial Basis Function,RBF)。公式有如下:
,
SMO算法的核心在于不断更新拉格朗日乘数,使得方程L最小化,其中
是一个向量。以下简单概述更新
的方法:任取中的两个拉格朗日乘数即和,更新这两个拉格朗日乘数的值直到方程L达到最小化,完成后再另取两个拉格朗日乘数,重复上述步骤直到方程L达到最小值,即获得全局最优解。SMO的优势在于不需要大量的存储空间来存储巨大的矩阵,故SMO算法的代码中需定义外循环启发式(Outer Loop Heuristic)和内循环启发式(Inner Loop Heuristic)来提升算法的速度。
SMO算法主要分成三个部分,即用于选择第一个拉格朗日乘数的启发式、用于选择和优化第二个拉格朗日乘数的启发式、以及使用该两个拉格朗日乘数使得方程最小化的函数。
一开始需将定义为0向量。定义优化
和
的启发式optimize_alpha_i_j(),方法内包括对是否违反KKT条件的判定,以及各种优化
的步骤如计算的上下界、计算步长和
、修剪
、判断步长是否足够大、计算
、计算b以及计算误差等。
1. 选择的启发式
首先得判断是否违反KKT条件,若违反则继续进行以下优化步骤,反之则不进行。KKT条件为 toler<-0.0001 and <C 或toler>0.0001 and >C,其中toler 为容错率,训练模型时将容错率的阈值设置为常数0.0001,以及惩罚系数C=1.0。在对进行优化之前,需调用innerLoopHeuristic()来选择以配合进行优化。的选择条件为使得误差绝对值最大化的,其中误差绝对值为。
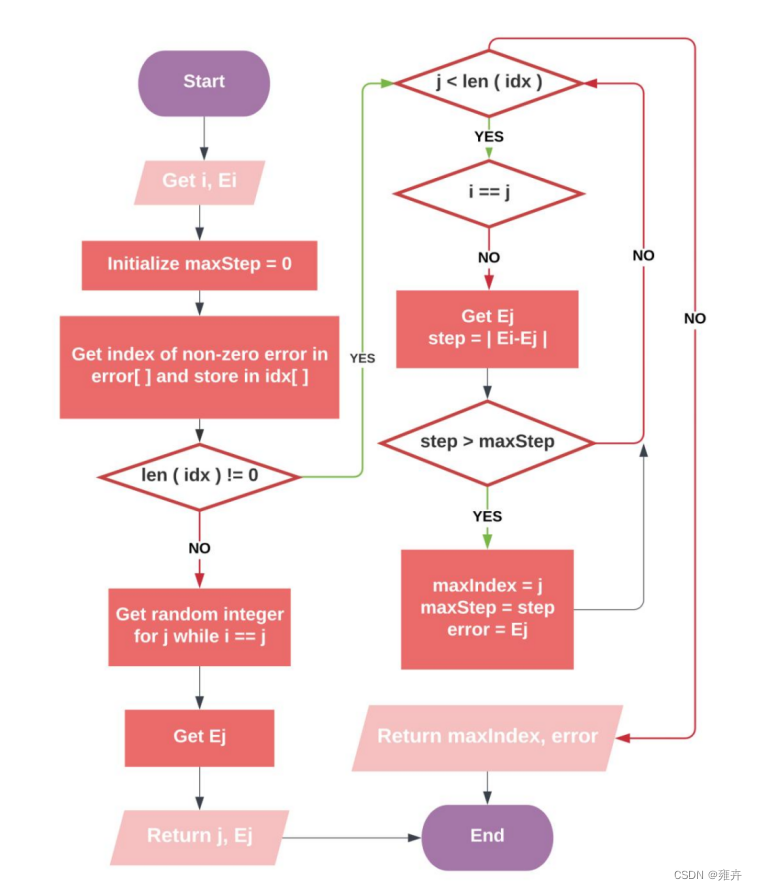
2. 选择和优化的启发式
- 计算
的上下界:L为下界,H为上界,若L==H,表示再也没有优化的空间,则选择新的下一组
进行新一轮的优化,反之则继续进行计算。其中计算公式为:
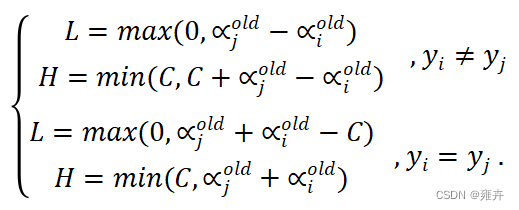
-
更新
:更新上下界后,需计算步长更新
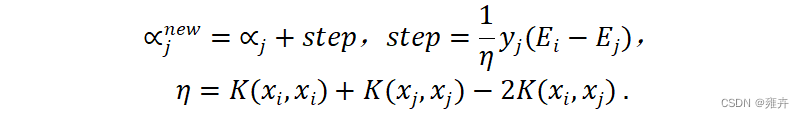
为了使
向量中寻找
.要使step最大化则需满足以下条件:若
则
-
修剪
,若不满足条件则终止计算,选择新的下一组
-
更新
:上述得到
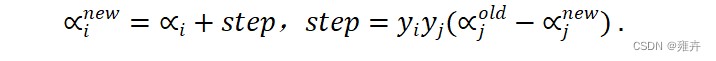
- 更新b:接下来将由b1和b2计算b,计算方式如下 若
,b=b1;若
,b=b2;否则
.
3. 使得方程L最小化
接下来是第三部分,即优化所有。代码中定义了optimize_all_alpha()方法,优化的优先级依次为非边界
、边界
,遍历每个
时调用了optimize_alpha_i_j()方法对该
进行优化。执行完此方法后将把参数b和
值存储起来,方便下一次的迭代使用。
在trainModel()方法中训练模型时,将之前存储好的向量取其中非零
的索引,将这一组索引带入到训练数据样本 X_train 和标签 y_train 中即可找到该模型的支持向量(Support Vector),训练好模型后将使用优化好的参数b和
对测试集进行测试,并计算训练样本以及测试样本的准确率,评估模型的性能。计算预测标签的向量的方程如下:
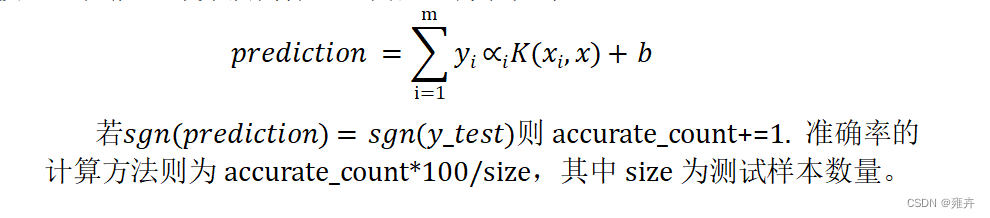
程序流程图
SMO 外层循环启发式流程图

SMO 内层循环启发式流程图
总结
SMO对于输入数据样本量有较大的伸缩空间,可以对巨大的训练样本量进行训练,且高效、快速。SMO算法对线性问题的处理比非线性问题来得高效,这是因为优化参数后的重置工作都是相对简单的算法,而非线性算法大多需使用加权求和,会消耗较大量的时间。















 6901
6901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









