






在 2024 年 7 月 24 日的 Unite Shanghai 2024 团结引擎专场演讲中,Unity 中国高级技术经理周赫带大家深入解析了团结引擎的实时全局光照系统。该系统支持完全动态的场景、动态材质和动态灯光的 GI 渲染,包括无限次弹射的漫反射和镜面反射 GI。

周赫:大家好!首先进行一下自我介绍,我现在在团结引擎担任高级技术经理,负责开发图形渲染方面的技术,现在是实时全动态 GI,也就是 Real-time Dynamic Global Illumination 这个系统,很荣幸给大家介绍这一系统。
团结引擎致力于解决中国开发者的需求,全动态的实时全局光照可以说是开发者千呼万唤的功能。在实时渲染领域中,如果常年有海量的物体、海量的灯光,这些物体灯光都可以移动,这些灯光还都带阴影,那么计算实际光照都已经是一个很难的问题了。传统的计算方式,比如说光照图,比如说 Unity 自带的 Enlighten,它是半实时的,需要进行预计算。但是我们看到现实世界中的光照是非常细腻的,灯光和物体运动情况下,它们的动态细节是可以辨认出来的。如果是预计算的话,因为它的预计算时间是很长,但是存储量很有限,这就是实时全动态全局光照需要解决的问题。
传统方案对于重度游戏场景来说难度很大,预计算很难解决这样的问题,因为存储量会更大;对于现在流行的重度开放世界的游戏更难采用这种方案。
还有一个工作流的问题,大型的场景预计算时间很长,每天晚上开始计算场景,到第二天早上都没有计算完,这种对工作流来说也做不到及时反馈,运行画面真实感应也很难保证。
说这么多,下面放一个视频直接感受什么是实时的全动态 GI。
这是一个室内场景,整个场景只用一个平行光做光源,刚才看到的地方都是平行光的阴影。室内场景遮挡复杂,在这些地方有比较细的光照表现。另外,场景中有一个镜子,是完全光滑的表面,它是从镜子往外发射光线,打到 GI 场景的数据结构,这个结构是对整个三角面场景的简化。镜子中的 GI 场景不仔细看无法看出和真实三角面场景的差异,它的光照和几何细节都很细。基于这样的 GI 场景才能实现实时全动态全局光照。
我们再看下一个视频。
这个视频是室外场景。这个场景同样只有一个平行光,因为整个天空盒有一定的亮度,平行光阴影范围内是天空盒光线照亮的。如果是墙面的背面,会有很多凹凸置换的纹理,如果没有我们的实时光照就会是平的。我们播放细节可以看到平行光移动的时候,阴影区域反射光是在变化的,这些都是实时全动态 GI 的细腻效果。游戏中有一类很难表现的阴天/多云场景,这些阴影区域可以认为和这样的场景表现类似。
上面是开发中的视频,首先展示了关掉 GI 的效果,它的材质纹理可以表现出来,但是没有光照细节,看起来很平。怎样打开 GI 呢?只需要一个开关,打开就有这个效果,不需要进行任何预计算。这个场景是开发中的画面,它是从 Asset Store 随机下载的一个室外场景,阳光非常强,没有特意表现间接光照效果,但是实时 GI 对真实感进行了提升。
下面两个视频都展示了在团结编辑器中的交互:
什么是全局光照
我们对实时全局光照进行定义,什么叫做全局光照呢?

这个公式是做渲染方面很熟悉的,积分号右边是一个 Lr,x’ 是一个表面,ωi 是一个方向,指这个表面在某一个方向接收的光线。左边的 Lr 表示我们要算一个 x 点的 GI。右边的光线来自另外一个表面,另外一个表面发出的光线被接收了。f 是一个 BRDF 双向传播的函数,是关于面元 x 还有两个角度的函数。还有 G,它是距离平方反比的系数,它的两个表面与光线传播方向有一定的夹角就会自然衰减。公式最重要的一点是 V,这个 V 是关于 x 和 x’ 两个面元的函数,可见为 1,不可见为 0。这个公式对场景中所有的面元产生影响,对于有非常多的物体在里面的游戏场景,每个物体划分非常细才能得到比较细的 GI 效果,这个公式的 x 数量级非常高,要算是否可见一般使用射线检测(光线追踪),用这种方式去做计算很耗时,面元数量也非常多,这个 V 可见性的系数计算是非常大的性能开销。
另外一个非常大的计算开销来自哪里呢?我们正常算直接光照,一个光源有多亮是已知数;但在这个公式里它是一个未知数,它是关于 Lr 的方程。已经有文献对这个方程进行求解,改写成了 Fredholm 积分方程形式,可以认为是一个线性公式,用线性算子去求解。Le 是任何一个表面所发射的光线,它发的光线如果不同就写成 Le,Le 是一个已知数,不需要更多的计算量。
我们再看算子求解,它还引出一个概念是多次弹射。左边是 L(未知数),把 L 归并以后,这里用到一个解的技巧,这个 “I-K” 再 “×” 后面是一个单位阵,所以它乘起来就是 “I+K+K²+…” 再 “×E”,再展开以后就变成这么一个公式。
从右边的图可以直观看到复杂程度,首先 Le 是一个面元发射的光线,在图里只有亮的面元(光源的面元)才有 Le。依次弹射指的是直接光照,因为这是一个面积光,第一行中我们看到阴影地方是完全黑的,因为面积光有一定的过渡,但是实际中点光源或者平行光没有过渡,这是直接光照的结果。如果是第二行算一次弹射间接光照,会比刚才的图好一点,但是也好不了多少。第二行最后是多次计算弹射间接光照。这个图,我们认为它的效果是接近真实效果的。
因此我们就引出了计算复杂性的第二个来源“多次弹射”,现实中的场景光源从能量角度来看,从光源发出的能量经过无数次的弹射达到平衡的状态,全局光照就要把平衡状态渲染出来。

刚才说的运算很复杂,像一些电影动画会采用离线渲染来算,一帧画面出几个小时甚至一天的时间。但是我们游戏的实时应用也要全局光照才能达到更高的真实性。全局光照对于画面真实感,还有像阴影区域高频细节提升是非常显著的。要使画面更自然,即使是非真实感的画面也需要全局光照。
这个运算量大的问题怎么解决呢?除了传统的静态方式(光照图、环境光照探针)外,每个探针记录了比较少的系数,但是用这种去做反射,其实还是要存更多的数据,每个探针数据量就会大,要整个场景用探针方式存储量就会很大,尤其是光滑的反射,就不能使用这种方式。
我们还提到了预计算 visibility,即 Unity 现有系统 Enlighten,它其实按刚才的方式把场景分成面元,面元组成一个层级,并不会计算每个面元到每个面元的 visibility 系数,它系数还存在 G,但是运算比较少。我们看 visibility,它计算层级中的一些根节点之间的系数,是否可见记录在这个数据结构中,它的存储量不是 O(n^2) 了,就能存储小一些,但是面元多的话还是存储量太大了。我们使用 Enlighten 的时候,会把场景划分面元划分很大。这是需要预计算的方式,当然更新也需要时间。运行的时候,它能做到场景是静态,光源是动态,而做不到物体和光源完全是全动态。
全动态实时全局光照算法演进
下面我们重点介绍一下全动态实时全局光照算法演进。
所有不需要预计算的方法都可以认为是演进的一部分,都有哪些呢?我们可以简单列举一些。

右上角的图(RSM),它从光源出发,渲了一张 reflective shadow map,它其实跟正常阴影贴图相比除了深度以外还有一些材质信息,还有打上去的光的信息,针对每个光源都要进行操作。而且重点是,它只计算了从光源出发到这个点的 visibility,忽略了从这个点反弹的 visibility。我们会看到效果有点怪,我们说一个渲染画面它的质量是由材质和光照,还有一些几何体综合起来构成的。如果像这种场景,只有大的色块,没有材质细节,并没有那么精确,会有比较大的画质损失。还有一些如 Instant Radiosity、ISM。
第二类是基于体素 (LPV,SVOGI,VXGI),LPV 没有 visibility,VXGI 计算了 visibility,但存储的分辨率有限,在接近遮挡物边缘的地方,相当于相邻体素进行了线性差值,会发现过渡是不自然的。也就是说总结下来,我们只要是计算过程中过于省略,忽略很多细节,看到的画面一定会肉眼发现不自然,跟真实场景不一样。所以全局光照对于人观察世界来说是一些重要的细节,我们要把它尽量还原出来才能做到真实。
还有一些问题,因为体素颗粒度比较多,还有基于图像会因为场景中少一些屏幕、摄像机空间之外的信息,也会造成不真实。另外,闪烁也是一个重要的点,如果基于图像,由于信息不完整,导致画面上下帧差异比较大造成闪烁,我们尽量会复用相邻像素的信息进行过滤。
团结引擎全动态实时全局光照系统
我们看一下团结引擎全动态实时全局光照系统。我们基于两阶段的方法,这个方法其实很有历史,1987 年就有人提出。因为计算复杂性来源两个地方,一个是要计算无限次的弹射,另外一个是计算非常多的射线检测。

怎么样能减少运算呢?首先需要把 GI 场景用一种比较粗粒度的方式表现出来,用来计算多次弹射的结果。在最后一次弹射的时候,从画面中的物体弹射到摄像机,实际操作是反过来的(从摄像机出发),这次弹射我们利用屏幕空间的高频信息(G-Buffer),还有相应的 motion vector 信息,用这些信息发出光线,这个信息是精确的,因为屏幕空间包括置换、贴图信息都是包括在内的。
历史上第一个用两阶段方法也是用在离线渲染上,它用的是 Radiosity 加上 Ray Trace,还有著名的算法,比如光子映射,它完全是使用两阶段的方法。因为光子映射是对场景的粗糙表示,只保存低精度的光子,光子数量很少的时候很不精确,但是在最终聚集阶段利用屏幕上的 G-Buffer 点上出发,它的精度是比较高的。即使粗粒度表示精度不高,也能使最终画面效果提升。
第一,使用 GI 场景进行近似计算的话,粗粒度场景有几个功能,首先是进行 Raymarching 加速。也就是说射线检测有多种方式,比如光追、Raymarching,我们如果有距离场或者是一些体素方式,再以一定步长去遍历场景,打到场景中存的物体上,命中或者未命中,能比光追计算要快。光追是完全精确通过 BVH 碰撞三角面,一般来说计算比较慢,比较复杂。
还有,粗粒度场景可以对材质和光照进行缓存,最重要的是光照缓存。比如之前的 VXGI,如果准备两套体素,在两套体素之间进行传递,比如已经算出上一帧的 VXGI,我们知道它是单次弹射的,如果下一帧复用上一帧的结果,从体素出发打的是上一帧的体素,能得到累计光照的效应。也就是说最开始列的 KL 公式,是累计了之前的结果。可以看到粗粒度表示可以用多种数据结构,可以理解为抽象的一个接口,接口的实现可以用多种方式。一会儿会介绍到最终的实现方式。
第二即用最终聚集计算 GI,也就是刚才提到的从 G-Buffer 出发。
我们再介绍一下团结引擎全动态实时全局光照的特点,两个阶段各有特点,当然后一阶段是提升精度。性能来说,我们发现实际最大量的射线检测是在于 final gather 阶段。另外一个特点是模块化,每个阶段可以支持更多的算法。
PC 和移动平台的特性是不一样的,我们更倾向于在移动平台节省运算量,因为移动平台的带宽很有限、GPU 性能有限,比如光线追踪在移动端也可以有实时方式,但它每秒钟发出的光线数量远少于桌面 GPU,我们必须用一种方式把总的计算量减少。
GI 场景
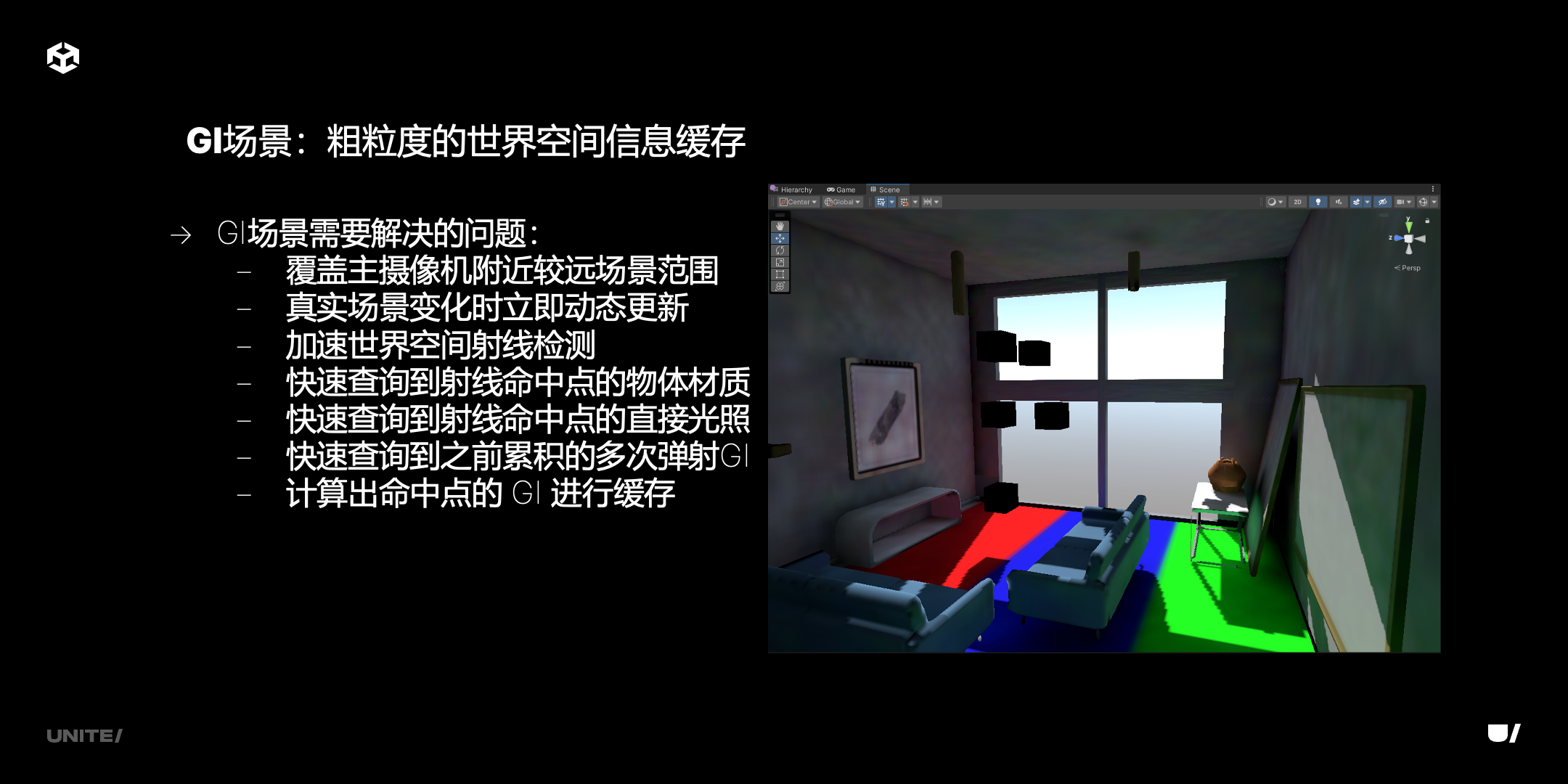
我们现在介绍一下 GI 场景,也就是粗粒度的场景表示。这里是它需要解决的一些问题,首先要覆盖摄像机附近的场景范围,大概 300 米。更远的场景怎么办?更远场景渲染时会有一些图像空间的信息,去补全信息。
还有真实场景变化时实时更新,要做到实时更新有多种方式,一种是所有东西更新一遍,还有一种是在 GPU 端对已有数据进行增删改查,在 GPU 端用 compute shader 处理 CPU 端发布的增量数据。现在主要用的是增量更新。
还有加速世界空间射线检测,刚才也说了很多种数据结构可以做到。另外,我们射线检测只能检测到两个点之间是否可见,可见之后如果是命中了,能得到命中点的三维空间坐标,要想进行后续的光照计算,必须从这个坐标查询到三维空间世界空间的点对应的存储空间,存储空间可能存了物体 PBR 属性,还有之前累积的直接光照和间接光照的数据。必须从 3D 坐标点查询到数据,这需要一种数据结构能快速查询,而且要占的空间更小。如果是之前提到的体素,或稀疏的体素存储,它的存储空间都偏大,所以需要用其他的方式去存。

我们再介绍一下 GI 场景中射线检测的部分。我们提到射线检测是给定一个点,这个点对应 x 面元,从这个点出发可以朝着 final gather 所指定的方向打光线。那么它其实有多种计算方式可以适用不同的场景,对外是一个抽象接口,内部实现有多种。首先是物体空间 SDF,它是两套索引,首先是物体的 instance ID 的索引,每帧都去构造,从摄像机出发,把摄像机追台划分成小的 froxel,每个 froxel 记录它所会相交的 instance 数据,这是每帧计算的,但是因为 froxel 数量有限,所以可以以较快方式把它计算出来,这是物体空间的 SDF。
还有重点介绍 GPU DF,它是一个全动态的,无符号的距离场。之所以无符号,因为我们在 GPU 端对三角面进行体素化的时候,并不知道当前的体素格子在面的什么方向,有可能在正向,有可能在反向,我们干脆不判断它在什么方向,而是采用无符号的方式存储它。我们距离场的特点,首先是无符号存储,它也是分块的,因为整体数据结构稀疏,叶子节点是一个块,块里面数据紧凑,但是块外稀疏,可能整个 “N×N” 的块没有任何三角面,在这种情况下就不存储它。如果是有的话,我们会计算块中对应的每个体素到三角面的距离。
另外,它的更新也是完全用 GPU 去实时更新,不同于物体空间 SDF 至少物体的 SDF 是预计算的。刚才说的 froxel 是实时生成,但如果物体是预计算的话,会影响我们动画物体渲染,无法做到完全实时;如果是用 GPU 全动态距离场的话就能做到。
它是怎么更新的呢?首先在 CPU 端对物体的移动、增加、修改、删除进行收集,得到列表,列表放到 GPU compute buffer 里,然后传送到 GPU 端,用 compute shader 进行处理,compute shader 会把这些物体对应的 instant ID 更新到 GPU scene 场景中,里面每个物体会对应一些三角面,这些三角面会对应到每一个体素,就会获取到每个体素块对应的三角面列表。
进行 GPU 实时计算和更新的时候,我们获得列表以后,对于每个块会发射一组 compute shader,每个 shader 的 thread 对应一个体素,整个 compute work group 就对应整个体素块,每个 work thread 会判断距离三角面的距离。通过 shared memory 进行最小值的计算,能得到实际要存储的最小值,也就是存储在距离场的数值。
这个结构是分层的结构。首先是 Cascade,一共 4 级到 8 级,每级 Cascade 比上一级 Cascade 覆盖范围多一倍,每个 Cascade 是一个带有 mipmap 的层级,每个 mipmap 用来索引体素块。一般来说是三级,每级是 16 个体素块,体素块层级最后的叶子节点是稀疏存储的,有可能这个层级没有体素块,就不记录体素块的 ID,如果记录了体素块 ID 会索引到一个大的 atlas,把每个体素块里所有距离的数值进行存储更新,所有体素化完的数据会更新到 atlas 上,atlas 的分配是在 GPU 端计算好的。
我们在进行追踪的时候,是从 cascade 出发,沿着 mipmap 层级最终到体素块,在体素块里面进行距离的步长检测。在 mipmap 阶段,每个 mipmap 元素记录了元素的 AABB,也是为了加速计算。
还有一种情况是摄像机的移动,我们采用 3D 卷轴策略,在摄像机移动之后,它的 cascade 范围有一部分体素层级会移出可见范围,因为总会有对应数量体素移进来,我们就会把这部分更新为移进来的。因为 mipmap 是对下一级 mipmap 进行索引,可以复用旧的 GPU 存储空间。

再介绍一下 Attribute buffer。我们说射线检测命中以后会得到世界空间坐标点,属性缓冲 attribute buffer 就是指通过坐标点能获取到一些数据。因为我们知道 3D 场景中的三角面是比较稀疏的,如果把整体所有的三角面存储到一个地方,一定有一种方式能把材质属性还有 lighting 信息以比较紧凑的方式存在 GPU 端。这与刚才的 GPU DF 不一样的点在于,GPU DF 还需要有一部分不紧凑的地方,因为需要去做 mipmap,但是它的数据不紧凑,有可能有些地方没有存体素,但一定要能索引它,所以要有一定的空间占位。
Attribute Buffer 中就不存在这个,我们有多种方式去存储。首先是分页方法,它有两种,一种是线性分页,把一个物体占用多个页面,这个页面位置是预计算的,页面有对应的 AABB;还有一种方式是物理空间哈希,这也是比较流行的方法,物体空间也是一个 3D 空间,物体三角面每个点如果以一定的分辨率进行体素化,每个体素 3D 空间点可以映射到 2D 空间点。因为我们知道在分页模式下 Attribute buffer 是一个 2D atlas,需要把 3D 空间映射到 2D 空间。物体空间哈希把物体空间三维坐标带入以后要进行线性同余计算和偏移,这个偏移是直接加上去的,不同的体素加的偏移可能不一样,绝大部分是连续的。也就是说,我们能保证在物体空间哈希中相邻的 3D 空间体素点能对应到 2D 空间点,如果有碰撞的话才会进行偏移,大部分的偏移比较小。我们对 3D 映射到 2D 空间并不能完美利用 2D 空间,但是能做到占用率 95% 以上,这是物体空间哈希分页方法。
Attribute buffer 还支持世界哈希空间方法,这是大概 2022 年以后流行的方法。这个方法还是把世界空间分成体素,但并不是连续存储,而是根据体素坐标进行一个哈希计算。一般进行两次哈希计算保证不碰撞,对于体素周围一定空间范围内的体素合并到一个哈希格子,采用 “8×8×8” 的范围,这个范围之内所有的格子是连续存储的,在格子之外是离散存储的。
世界空间哈希表方法相对于分页方法完全不需要预处理,但是有一个问题是占用存储空间多一些。我们在整个系统中分了多个不同的抽象接口,包括射线检测、Attribute buffer、final gather,每个都有不同的实现方式,也会去平衡存储量和动态性,往往是预计算多一些的方法能更有效利用空间。在一些更高端的平台上,我们会采用更加不需要预处理的方法。
我们会看到线性分页无论是去划分 AABB,还是对物体进行空间哈希都需要进行预处理,空间哈希主要计算每个点的偏移量。
最终聚集

最后介绍一下最终聚集过程。我们说到最终从 G-Buffer 出发,打出光线去采样刚才说的粗粒度场景表示。因为 G-Buffer 存了屏幕上的高频场景信息,包括每个像素的深度以及法线,还有一些材质信息,我们从屏幕空间出发进行 Screen Space Ray Marching,跟正常的 SSRT 走的流程是一样的,只是说反映的范围有限。如果超出范围以外,我们才会去使用粗粒度场景。如果粗粒度场景用了 GPU 的 SDF,比正常物体会大一圈,因为知道 UDF 对于比较薄的物体是可以正常表示的,但是 SDF 不知道比较薄的物体处于哪一面,无法正常表示。UDF 的问题在于如果按照正常采样出的距离步长来算,可能打不到这个物体,会把距离加上偏移值。导致 distance field 比三角面表示的物体会更大一圈,采用 screen space GI 能得到更精确的结果。
距离场比物体大一圈,会导致渲染结果产生过度遮挡 over occlusion,使画面对应部分偏暗。但因为不可能每个 G-buffer 像素都发出光线,实际上发出光线少于屏幕像素数,会有 under occlusion,这两者不能完全抵消,但是能使画面更加自然。得到的结果虽然不完全符合物体,但是二者的效果会达到平衡。这是最终聚集的过程。
我们看一下运算过程。最终聚集有多种实现方式,有 FullScreen ReSTIR 和基于 Probe 的方式,基于 Probe 是把屏幕划分成像素块,每个像素块是 8、16 个像素,对应是一个八面体投影的体积,有点类似于 light probe,只是这个 probe 是在屏幕空间。如果直接对它从像素出发,需要的发射光线数量很多,但如果是 16×16 probe,只发出 “8×8” 的光线,会减少总光线发射数量。
我们再看一下 FullScreen ReSTIR 的方式。我们把每个像素之前位置、速度、上一帧光照信息进行存储,对相邻的像素和上一帧像素进行复用,会进行多次时间、空间复用。因为我们知道屏幕上每个像素只发出一根光线的话,不能累计其他方向的数据,但相邻的像素是有这个数据的,我们只需要复用周围的像素信息,就可以实现提升整体效果。
对于 Screen Probe 来说,它也有一个 ReSTIR 累计方式。我们可以看到相邻的 screen probe,也可以有一定的数据复用。另外对于 screen probe,如果没有采用 ReSTIR 方式,会进行两步过滤,首先是 probe 级别的过滤,用到相邻的像素,但并没有存储 ReSTIR 一样多的信息,所以复用的结果更差一些。但是第二步还会进行像素级别的过滤,像素级别会复用上一帧的数据。进行 Probe 级别的过滤之后噪点会降低一部分,不能完全消除,进行像素级别的过滤后,噪点是完全消除掉的,这是两步过滤。
还有历史信息积累不足的问题,我们也有 world radiance cache,这是世界空间体素的数据结构,这个数据结构是累计了之前 screen probe 的计算结果,不足的时候会进行补充,也就是从 world radiance cache 出发采样光线,分辨率很低就足以实现对 screen probe 的补充。ReSTIR 这些算法已经很多用到实时渲染中。
未来工作
再介绍一下未来工作。

我们现在兼容性支持了 HDRP,URP 还在支持中。我们对于材质支持了 HDRP lit 材质和 shader graph 材质,现在对于 alpha test 是支持的,透明材质也是在支持中。
另外,我们目前支持 Windows 平台,计划继续支持移动平台,并针对 URP 进行足够优化。移动平台主要硬件是 Vulkan 1.1,我们在 Vulkan 1.1 硬件特性上是完全能实现之前的方法。但是之前的方法有一定的问题,就是 GPU SDF 更新是比较慢的,也会很占带宽,需要进一步优化。现在有更多的把场景进行体素化的方法,比如说 ROMA 之类的方法,它利用二进制的运算去体素化场景,这些方法对带宽的占用更低。我们会开放更多的接口,包括粗粒度的场景表示,还有 final gather,让用户自定义去实现。我们也会尽量地去优化 GPU SDF 在移动平台的表现。

最后是我们用到参考文献。
谢谢大家!















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









