









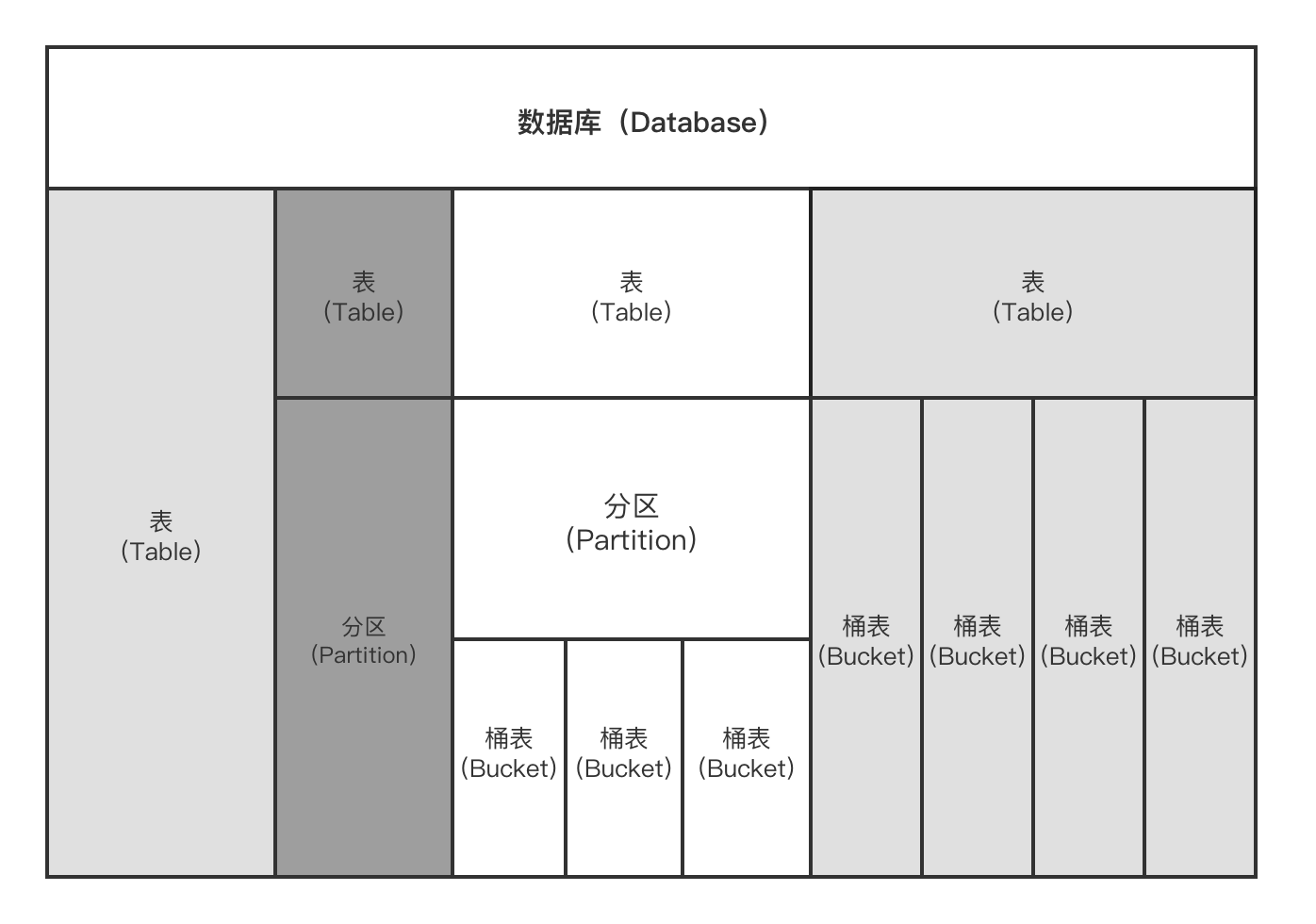
在hive中,数据库、表、分区都是对应到hdfs上的路径,当往表中上传数据的时候,数据会传到对应的路径下,形成新的文件
数据库
当于关系数据库中的命名空间( namespace ),它的作用是将用户和数据库的应用,隔离到不同的数据库或者模式中
Hive中创建数据库等语法
表
- Hive 的表在逻辑上由存储的数据和描述表格数据形式的相关元数据组成
- 元数据:本质上只是用来存储hive中有哪些数据库,哪些表,表的模式,目录,分区,索引以及命名空间。为数据库创建的目录一般在hive数据仓库目录下。
- 表存储的数据存放在分布式文件系统里,如 HDFS
- Hive中的表分为两种:内部表和外部表
- 内部表的数据存储在 Hive 数据仓库中
- 外部表的数据既可以存储在 Hive 数据仓库中,也可以存放在 Hive 数据仓库外的分布式文件系统中
内部表与外部表的区别主要体现在load和drop(是否同时删除元数据
与数据)上:
1.Hive创建内部表时,会将数据移动到数据仓库指向的路径,也就是
hive所在的hdfs路径,hive管理数据的生命周期;
创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变。
2.在删除表时,内部表的元数据和数据会一起被删除。外部表只删除元
数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更
加灵活,方便共享源数据。创建外部表时,甚至不需要知道外部数据
是否存在,可以把创建数据推迟到创建表之后才进行。
分区表
- hive分区就是一种对表进行粗略划分的机制,可以实现加快查询速度的组织形式.
- 在使用分区时, 在表目录下会有相应的子目录
- 当查询时添加了分区谓词,那么该查询会直接定位到相应的子目录中进行查询,避免全表查询,提成查询效率.
- 分区是为了加快数据查询速度设计的,例如,现在有个日志文件,文件中的每条记录都带有时间戳。
- 如果根据时间来分区,那么同一天的数据将会被分到同一个分区中。
- 这样的话,如果査询每一天或某几天的数据就会变得很高效,因为只需要扫描对应分区中的文件即可。
注意事项:
1 . hive的分区使用的表外字段,分区字段是一个伪列但是可以查询过滤。
2 . 分区字段不建议使用中文
3 . 不太建议使用动态分区。因为动态分区将会使用mapreduce来查询数据,如果分区数量过多将导致namenode和yarn的资源瓶颈。所以建议动态分区前也尽可能之前预知分区数量。
4 . 分区属性的修改均可以使用手动元数据和hdfs的数据内容
啥是动态分区?
桶表
- 对于每一个表或者分区来说,可以进一步组织成桶,其实就是更细粒度的数据范围
















 3748
3748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











